






知乎:涮月亮的谪仙人(已授权)
链接:https://zhuanlan.zhihu.com/p/21290410831
编辑:「深度学习自然语言处理」公众号
项目代码可见:Unakar/Logic-RL(https://github.com/Unakar/Logic-RL),欢迎关注和star!
我们将开源完整的wandb曲线和训练日志,wandb report(https://wandb.ai/ustc_ai/GRPO_logic_KK/reports/GRPO-Zero--VmlldzoxMTIwOTYyNw?accessToken=gnbnl5mu5pwfww7gtwxymohg85w7d7vthvjvbl4w8yxg0a99vf1k22m11e61cvv8)
在大四的最后一个寒假,和@AdusTinexl @ShadeCloak 两个小伙伴捣鼓出了点有意思的东西,非常开心,欢迎各位合作,指导!
先展示一下结果:
基座模型Qwen 7B在测试集上只会基础的step by step逻辑。
无 Long CoT冷启动蒸馏,三阶段Rule Based RL后 (约400steps),模型学会了
迟疑 (标记当前不确定的step等后续验证),
多路径探索 (Les't test both possibilities),
回溯之前的分析 (Analyze .. statement again),
阶段性总结 (Let's summarize, Now we have determined),
Answer前习惯于最后一次验证答案(Let's verify all statements),
Think时偶尔切换多语言作答 (训练数据纯英文的情况下,思考部分是中文,最后answer又切回英文)
测试集上性能也一举超越了gpt4o 的0.3,达到了 0.41的准确率,相比自身初始0.2 acc翻了一倍
非常漂亮的回复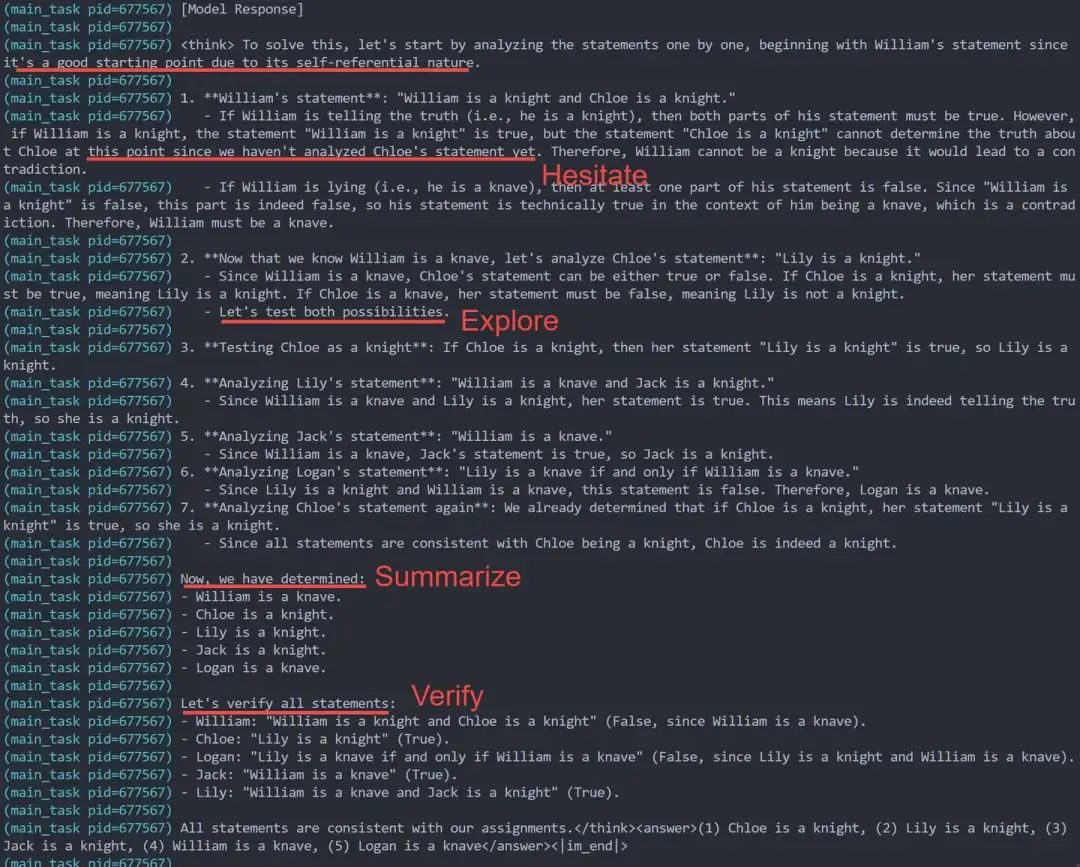
demo1:迟疑,回溯,总结,verify。训练后期模型总是倾向于在最后输出answer前,优先全部verify一遍。这些能力是RL训练涌现的,未加任何引导
偶尔的多语言现象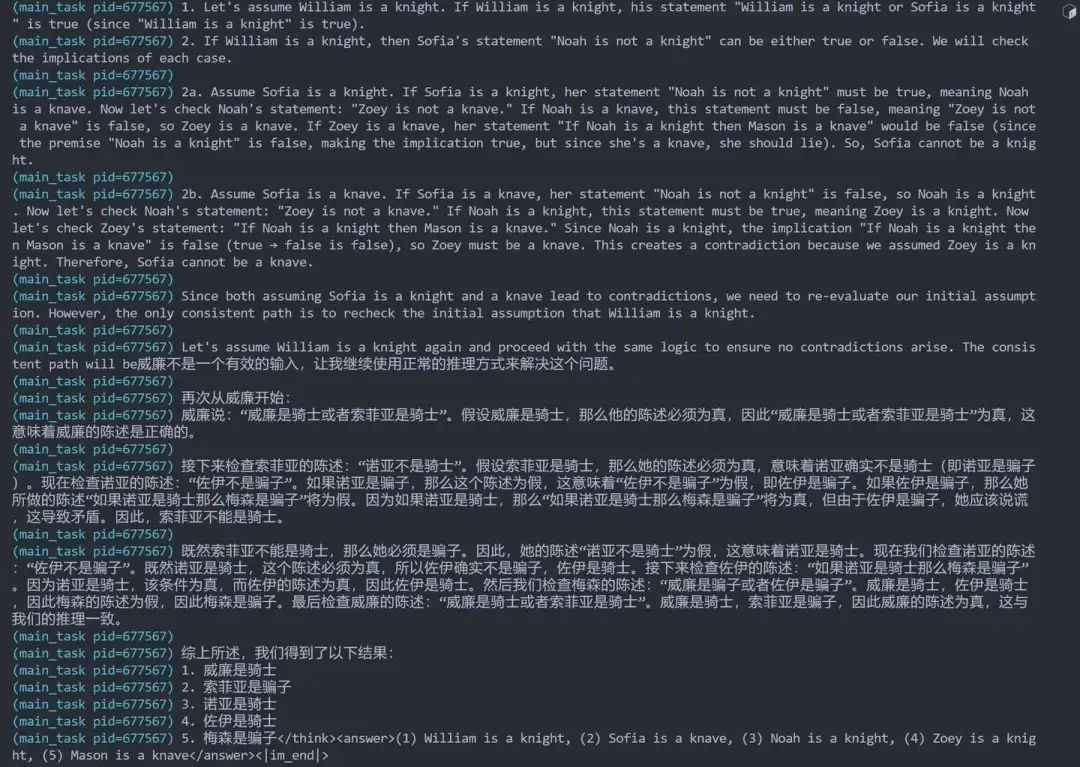
demo2: 多语言的例子,思考忽然说中文,最后为了格式奖励用英文做最终回答,回复是对的
demo3:训练前模型原本的输出作为参考, 笨笨的也很可爱,看得出来是一点verify之类的基本思考单元也没有
Response长度增长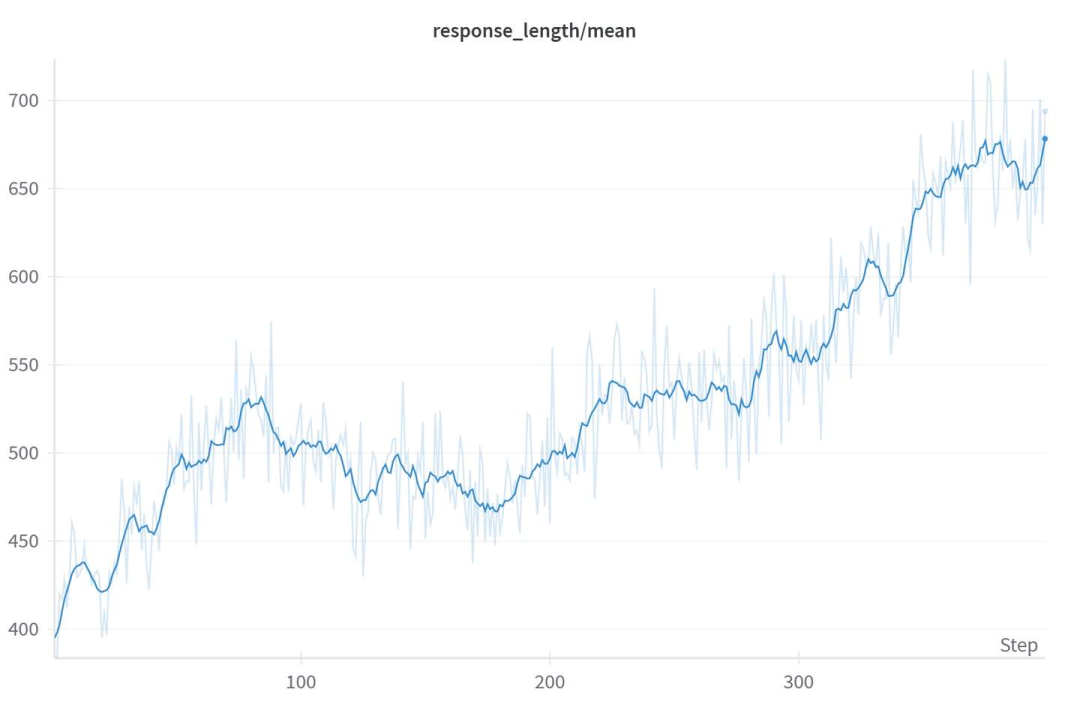
Demo 4, Settings: prompt mean 276 tokens, origin response mean 400 tokens据我所知,这是第一个稳定实现输出长度大幅超越原始模型平均长度的(数据集prompt长度全部小于300 tokens,相比于基座模型原本输出的平均长度 400 tokens, 训练后期平均长度稳定在650 tokens,约50%的涨幅)
Reward曲线
我们设置了严苛的format reward和Answer Reward。
Reward只有这两部分构成,避免任何reward hacking。
我们编写了不少if else逻辑和正则。刚开始模型总能以匪夷所思的方式绕过我的预想,在和它一次次的斗智斗勇里完善了rule的编写
我们发现模型在学习format的时候,其实是一个快速收敛--逐渐崩坏--又忽然找回format的形式,与我们三阶段RL训练设置吻合。
还有一个有趣的小发现,在中间阶段,模型似乎认为格式反而阻碍了它的思考:日志里看到不少例子,模型在<answer> tag开始后意识到自己犯错了,想重回<think>进入思考模式,可惜被format reward狠狠惩罚了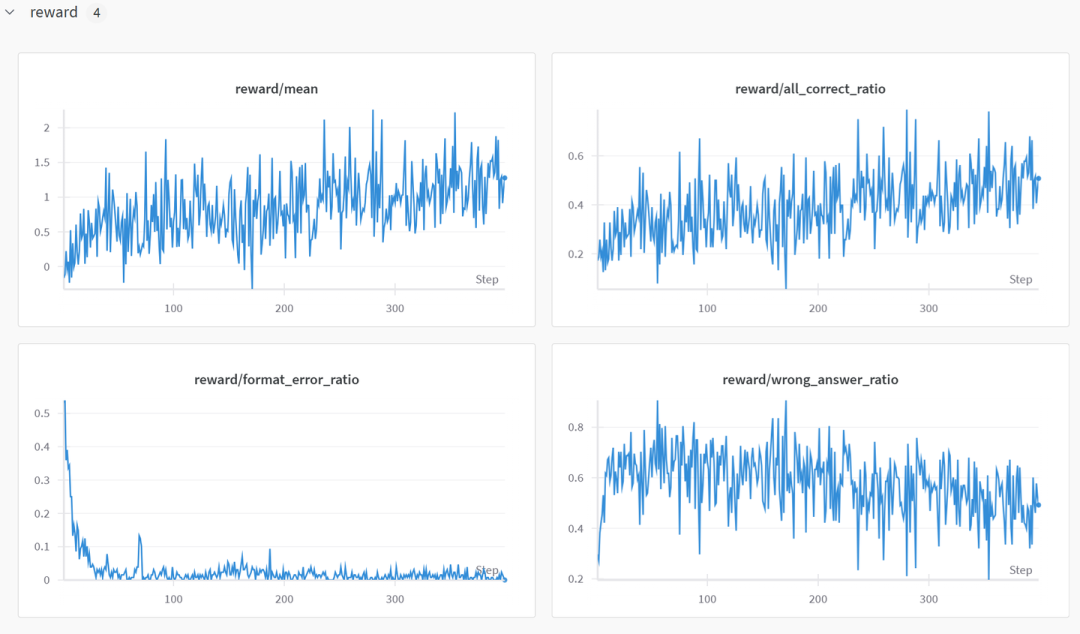
Demo 5, 依次是平均reward, 全对的比例,格式错误比例,答案做错的比例
基本Settings
训练数据合成
其实只有2K不到的训练数据集,完全由程序合成,确保对基座模型是OOD数据。
其中逻辑问题类似老实人和骗子的益智题,老实人总说真话,骗子总说假话,下面N个人,各有各的表述,请判断谁是骗子。我们以此为例讲解实验细节。
可控性也不错,可以人为设置难度分级。测试下来gpt4o的acc在0.3左右,而3epoch的RL训练后,我们成功让qwen-7B达到了0.41。
gpt4o和claude sonnet在这种逻辑题上的准确率出乎意料的低。我们选了一个合适的人数来控制难度,确保它高于qwen 7B当前的能力,但又不会过难(在8个人的情况下,qwen完全不能作答,RL训练曲线也堪比蜗牛爬。我们最后选取了5人作为基线)
模型基座选取
我们注意到deepseek官方开了一系列distill模型,测试下来感觉有点矫枉过正了,小参数量承载了超越其自身的推理能力。回复里的wait, alternatively这种字眼频率过高。
Deepseek distill系列选了qwen-math-7B作为基座。我们本来也是这个,后来发现这个模型有坑:
首先它指令跟随能力比较一般,很难学会format;
其次,它说话老爱用python code解题,训练很难克服
移除system prompt后,还是习惯用\box{}包裹answer,还是format不行
Markdown味道太重,一板一眼的,Reasoning模型本应思想跳脱一些才是
我们训了几版RL,效果始终不好,最后决定放弃Qwen Math系列,Qwen 7B 1M就好
RL基本设置
我们初始还是PPO,训练确实稳定,就是太慢了。Reinforce系列测试下来又快又好,显存还低,强烈推荐。
为了和deepseek对齐,我这里放出的所有结果都是GRPO Setting下的。
由于我只有四卡A100,跑实验相当费劲,坐等来个大佬资助我跑实验 ()
Train batch size只有8,Rollout先大后小 (32-64-16)
三阶段RL
我的经验是:高温采样+超大rollout Matters
Step1: 课程学习与格式遵循
为了训练的平稳过渡,我们先用少量3人逻辑题做预热,使用默认采样设置。
此阶段主要是学<think></think><answer></answer>的格式,只要不遵守该规则,我们就施加很大的负面奖励。模型在10step训练里很快就能学会把format error降到0.1的占比
伪变长:此阶段观察到极少量的response length ++,主要提升的是最短response的长度,max response长度基本没变,是反馈到mean length上是一个变长的过程。
以及此阶段确实验证了Pure Rule Based RL有效性,Val acc一直在涨,不过不如SFT来收益来的快
Step2:高温采样与大量rollout
数据集过渡到正式的5人谜题,此阶段训练持续最长。也是最容易崩溃的时候。
我训了14版超参,都是崩坏的,泪目,下面讲讲一些好玩的崩坏demo。
尝试将采样温度设置为1.2附近。(实测1.5会崩,1.5什么鸟语言都蹦出来了)。topp和topk也调了一下,主要目的是紊乱模型回复格式,破坏其markdown的输出风格,增加token多样性。
下图是截取的模型一个很有意思的repeat现象,可以看得出来,RL极大地增加了verify token被chosen的概率,这纯粹是自发形成的。数据集没有任何verify相关的思考token。
1. 模型的呓语:它想verify, 要precise, 注意consistent执念很深
2. Retrying too late,但没有后悔药可以吃
模型已经到达最后需要输出结果的answer阶段了,忽然意识到自己前面犯了错,想重回think模式,但是retry太晚了,这样的行为会被给予严厉的负format惩罚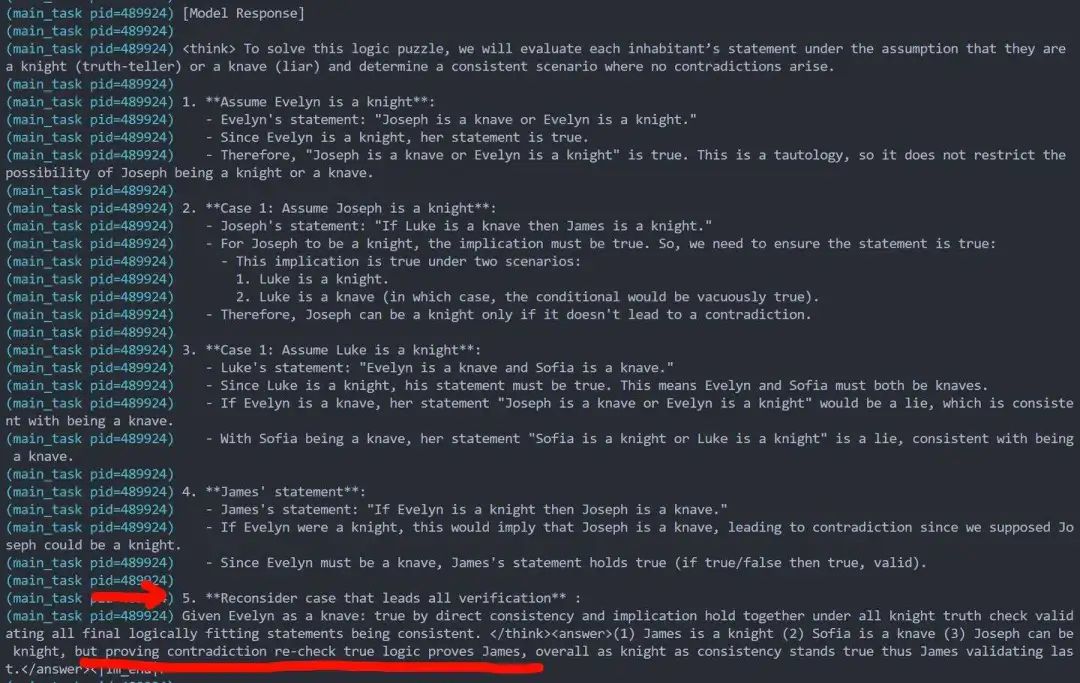
3. 忽然学会了正确地verify,以及先总结初步结论再做进一步探索,但思考过程还是比较简陋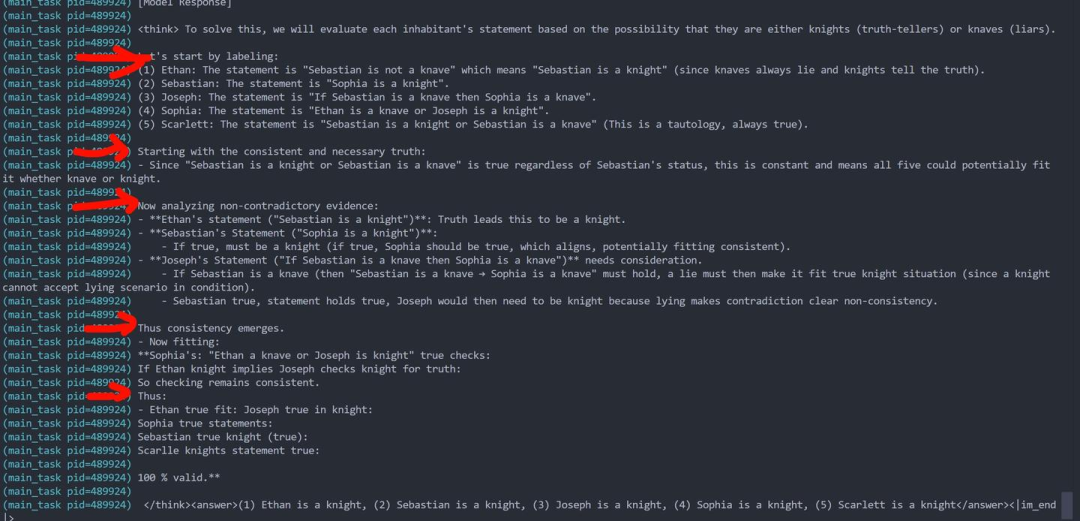
这里有很多有意思的设置小细节和中间输出的观察,非常值得深入探索
请等后续,几周内我们会写好完整文章~
Step3: 漫长的退火
采样设置里逐步回归正规,比如温度从1.2慢慢降到0.9。
此阶段模型的输出如demo1所示,非常的成熟,有verify,有反思,有回溯,有格式,要啥有啥,我很满意的。
整体思考并不冗长,废话也不多,比distill模型的回复看起来正常多了。
学习率也逐级递减到了2e-7。此阶段模型收敛速度贼慢,但多等一会,会有很多惊喜。还是让它训着吧。
奇怪的想法
语言混杂的现象非常迷人。手动查找log,似乎后期每个语言混杂的response都是对的,难道对模型来说混合语言作答是更有利于它reasoning的pattern?
进一步地,谁说thinking porcess一定要是人类可读的,只要answer看得懂就行。如果答案对,我宁可中间全是乱码也无所谓(bushi)
只要能从模型输出里恢复出人类要的答案,answer format其实也是不必要的,只是测试验证的难度大大增加了。看上去又回到了某种ORM的老路..
Response增加是合理的。此前模型只会一路走到黑,多了几次verify和check后,自然长度增加
泛化性:当前模型的思考能力实测是可以迁移到GSM8K的。由此展开或许可以跑一堆实验...
此外,本地存了一堆ckpt,坐等后续可解释性分析哈哈哈。之前一直想做Long CoT的可解释性,现在手头终于有一些ckpt随便测了,启动!
最后扯一句,Deepseek真是越来越强了,眼睁睁看着从deepseek v2开始,成长到过年期间发现街头巷尾都在讨论它。逐渐变成了攀不上的模样(可能最早期我bar也不够)。欸,真想去deepseek实习看看。
春节最快乐的事情,就是看着zero模型RL曲线嘎嘎地涨!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









