






论文:SurveyX: Academic Survey Automation via Large Language Models
地址:https://huggingface.co/papers/2502.14776
Github:https://github.com/IAAR-Shanghai/SurveyX
网站:www.surveyx.cn (Demo Paper)
单位:中国人民大学,东北大学,上海算法创新研究院,悉尼大学

SurveyX,只需给定希望生成的综述论文标题,就能够自动调研文献并生成与人类专家撰写水平相当的综述论文。
结果展示



以上论文页面中,不仅有逻辑清晰叙述严谨的文字,有对方法进行不同纬度对比的表格,而且还有精巧美观的图片。这些,并不是来自于科研人员手工撰写的综述论文,而是来自SurveyX生成的,完全自动化由机器生产的综述论文!
背景介绍
近年来,计算机科学领域的技术发展迅速,文献数量呈指数级增长,研究者难以全面了解细分领域的技术演进路径。尽管综述论文对梳理研究现状至关重要,但手动撰写的工作量大更新周期长。
大型语言模型(LLMs)为自动化生成综述提供了可能,但仍面临技术层面(如知识更新滞后、上下文窗口限制)和应用层面(如缺乏统一评估指标、文献检索效率低)的挑战。
针对这些问题,SurveyX诞生了,通过高效的文献检索和预处理算法,结合RAG技术,生成结构清晰、内容准确的综述,并丰富了表达形式(如图片、表格)。
方法介绍
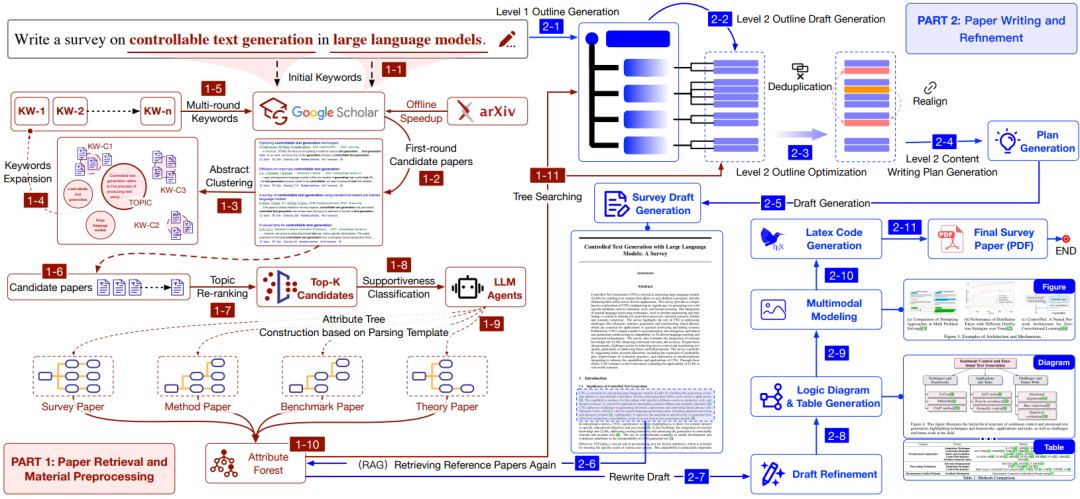
上图展示了SurveyX的整个工作流程。
SurveyX主要分为两个部分:准备阶段和生成阶段。
准备阶段,SurveyX通过高效的检索算法初步检索文献,后利用属性树模板对文献信息进行抽取总结,充分模仿了人类专家的文献材料准备流程。具体来讲:
SurveyX先通过Keyword Expansion算法尽可能的保证不遗漏任何与话题相关的文献,后通过粗粒度+细粒度的语义过滤方法及可能的去除掉与话题不相关的文献。从而获得高质量的综述撰写参考文献
SurveyX模仿人类专家的阅读思路,利用属性树算法,基于多种模板对论文文章信息进行提取,从而保证能够归纳总结生成综述所需的所有信息。不仅显著提高了检索材料的信息密度,而且能高效利用LLM的下文窗口,为高质量综述的撰写奠定了更坚实的基础。
生成阶段,SurveyX通过大纲生成,正文生成和后处理优化保证了生成的综述论文的高质量和结构化。
SurvyX先结合属性树中的信息,归纳总结一个可以系统的整理所有文献的框架,而后根据此框架,生成综述论文的一级大纲和二级大纲。考虑到LLM生成的二级大纲存在一定的冗余,SurveyX又通过分离一二级大纲后去冗余+重新排列的方法实现了二级大纲的优化,使得全文大纲逻辑结构性更强。
在生成正文内容时,SurveyX先基于所有的属性树生成正文撰写思路,而后根据撰写思路与属性树的具体内容顺序地生成正文内容。
在后处理阶段,SurveyX首先通过RAG的方法对属性森林进行检索,确保文章中所有引用语句的正确性。其次,SurveyX通过章节重写提升文章的行文流畅性与章节之间的一致性。最后,SurveyX利用多模态大模型对参考文献中的图片进行检索,生成综述的部分图片;同时,SurveyX利用LLM对正文提取关键信息,结合图片和表格的代码模板生成图片和表格的代码,生成丰富的图表,丰富了文章的表现形式,提高了文章易读性和内容质量。
总结
SurveyX的主旨在于充分模仿人类专家在撰写综述论文时的思路。读者可以通过访问项目地址www.surveyx.cn来查看更多生成案例并深入了解其工作流程。同时,也可以在https://github.com/IAAR-Shanghai/SurveyX中提出issue,只需要给定综述标题和关键词,就可以获得您定制的专属综述文献!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









