







论文标题:MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning
论文链接:https://arxiv.org/abs/2504.10160
Github仓库:https://github.com/fzp0424/MT-R1-Zero
研究团队:浙江大学刘佐珠/吴健课题组、小红书NLP团队
目前,大模型推理领域的强化学习(如R1-Zero)主要面向数学和代码等任务,将其应用于开放式自然语言生成任务(如,机器翻译),面临着奖励设计困难、推理能力诱导不确定、泛化能力待验证等诸多未知的挑战。针对这些难题,我们提出了MT-R1-Zero,首次将R1-Zero范式成功扩展到机器翻译领域的实现。该方法无需监督微调或依赖思维链(CoT)等冷启动数据,仅通过对最终翻译结果度量反馈,进行端到端强化学习优化。
核心方法:规则-度量混合奖励 (Rule-Metric Mixed Reward)
在机器翻译中应用R1-Zero的核心挑战在于评估的不确定性和输出的灵活性。我们创新性地提出了规则-度量混合奖励机制(Rule-Metric Mixed Reward) :
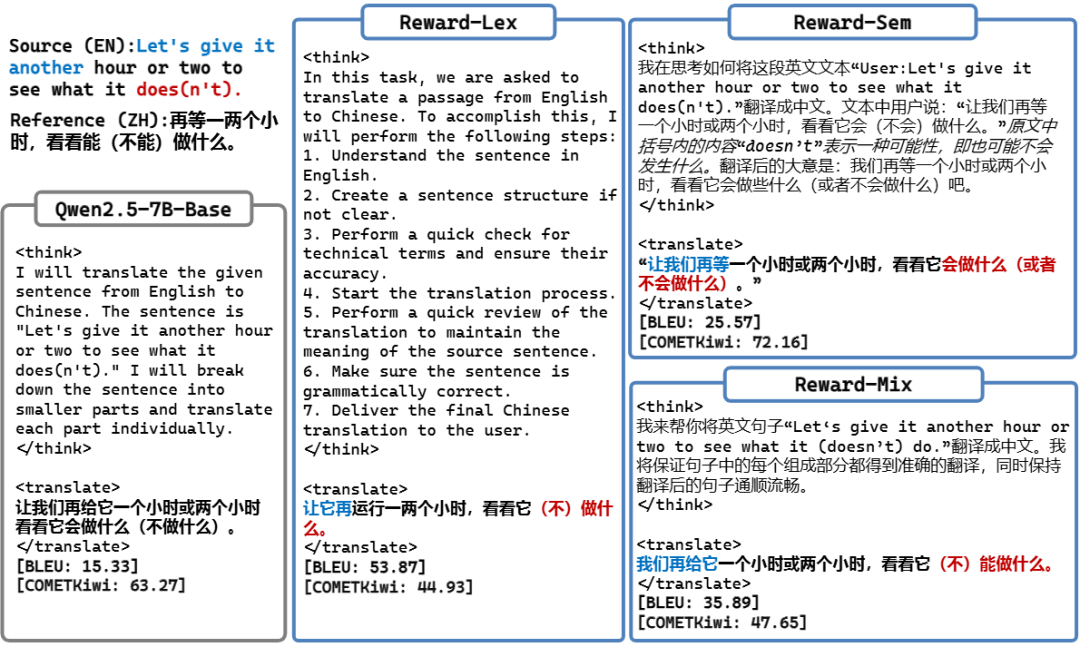
格式奖励 (Format Reward): 采用严格的格式检查,强制模型生成包含 <think> (思考过程) 和 <translate> (翻译结果) 标签的结构化输出,这保证了推理过程的可观察性。格式错误将受到固定惩罚,激励模型优先学习正确格式。

度量奖励 (Metric Reward): 一旦格式正确,则引入连续的翻译质量度量分数作为翻译质量奖励信号。我们探索了三种度量策略:
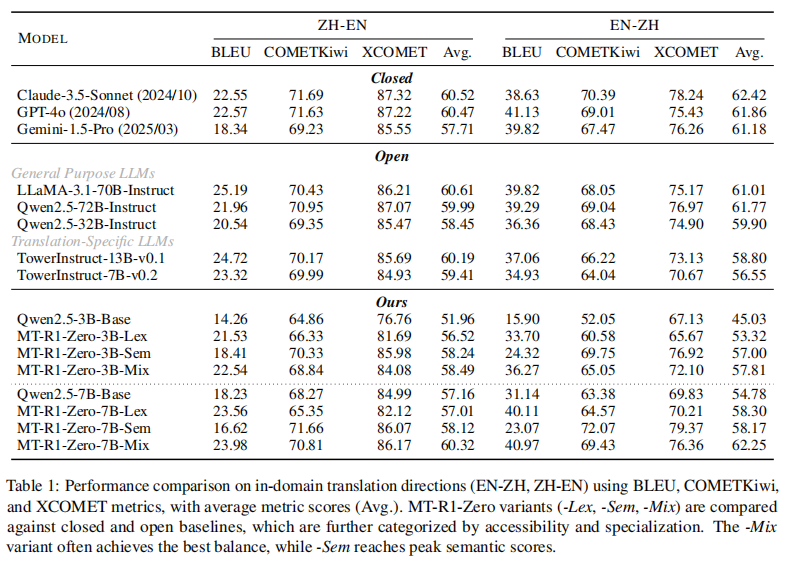
Reward-Lex (词汇优先): 使用基于N-gram匹配的BLEU度量作为奖励,侧重词汇准确性。
Reward-Sem (语义优先): 使用基于深度学习的语义感知模型COMETKiwi-23作为奖励,侧重语义保真度。
Reward-Mix (混合均衡): 结合Reward-Lex与Reward-Sem,旨在同时优化词汇和语义两个维度,寻求最佳平衡。
实验结果
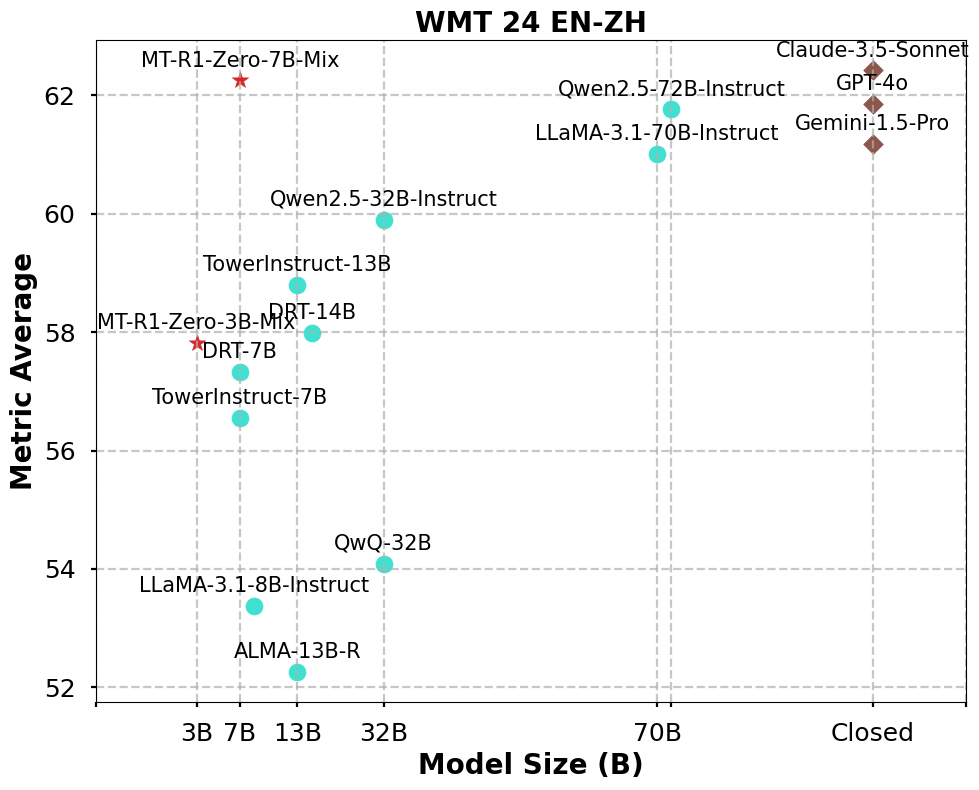
7B模型媲美闭源SOTA: MT-R1-Zero-7B-Mix 在综合三大指标(BLEU, COMETKiwi, XCOMET)的平均分上达到62.25,性能与顶级闭源模型 GPT-4o (61.86) 和 Claude-3.5-Sonnet (62.42) 旗鼓相当,展示了强大的综合翻译能力。
语义指标达到SOTA: MT-R1-Zero-7B-Sem 专注于语义优化,在COMETKiwi (72.07) 和XCOMET (79.37) 上取得最佳分数,显著超越了包括Claude-3.5在内的所有基准模型。
小模型超越大模型: MT-R1-Zero-3B-Mix 的平均分 (57.81) 显著超越了同尺寸基线模型 TowerInstruct-7B-v0.2 (56.55)。MT-R1-Zero-3B-Sem 在COMETKiwi (69.75) 上也超越了**远大于它的LLaMA-3.1-70B (68.05)**。
强大的泛化能力: 在OOD(分布外)测试中,仅在英汉数据上训练的MT-R1-Zero-7B模型,在日英、德英、德汉等任务上表现出优异的零样本泛化能力,XCOMET分数显著优于同尺寸基线模型。
关键发现与洞见
奖励设置至关重要: 奖励度量的选择(Lex, Sem, Mix)直接决定了模型的优化侧重和最终的翻译风格(词汇精准 vs. 语义流畅)。
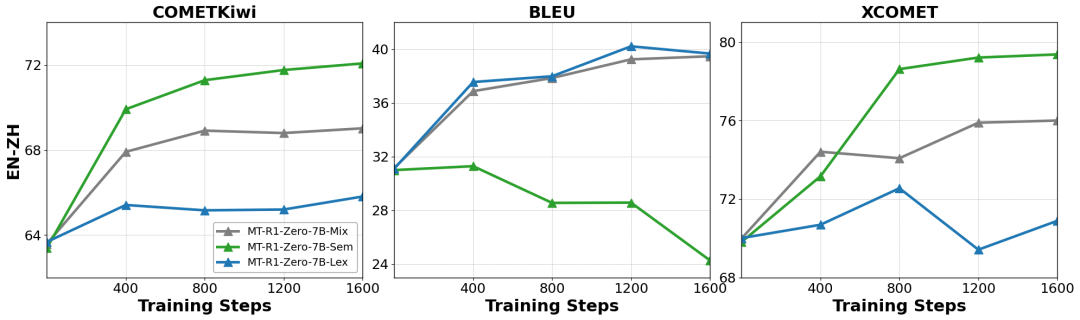
推理长度先降后升: 训练过程中,模型的回复长度通常先快速下降(学习格式和效率),然后随着思考过程的复杂化而缓慢上升,同时翻译质量持续提升。
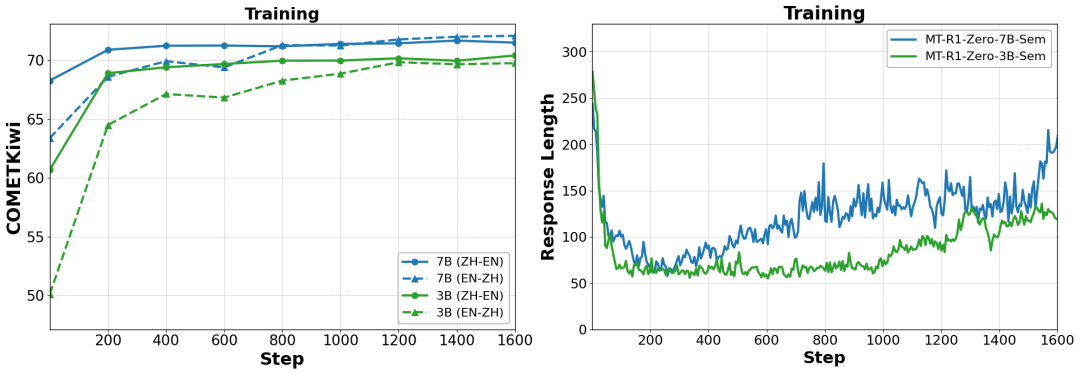
涌现的推理模式与语言自适应: 模型在训练中自主产生了多样的推理模式,从结构化规划到更口语化的步骤。更令人惊讶的是,模型进行内部推理的“思考语言”会动态地自适应到目标翻译语言,即使从未直接训练过该翻译方向。

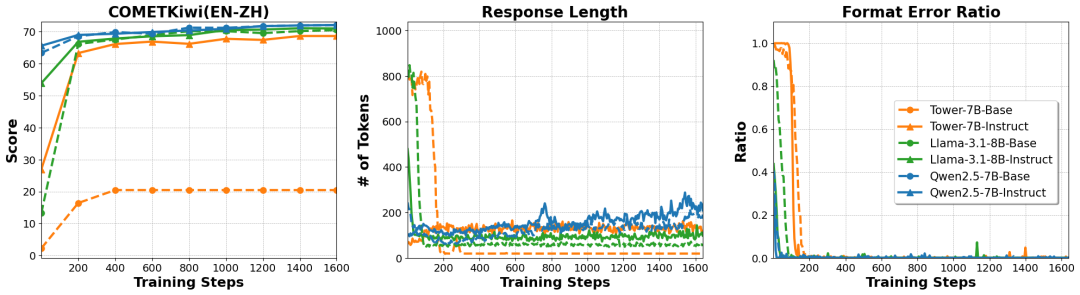
模型架构的适应性差异: 不同LLM架构对MT-R1-Zero范式的适应性差异显著。Qwen系列模型展现出最佳的兼容性,能更好地学习格式并生成连贯推理。相比之下,LLaMA和Tower (Translation-specific) 模型则面临更大挑战,并倾向于通过生成空洞内容来“欺骗”格式奖励 (format hacking)。

开放与展望
MT-R1-Zero证明了,即使在评估复杂、输出灵活的机器翻译任务上,纯粹的、基于度量的强化学习也是一条很有潜力的技术路径,希望这项工作能启发更多将RL应用于复杂自然语言生成任务的研究。
作者介绍
冯兆鹏:浙江大学国际联合学院(ZJU-UIUC Institute)2023级硕士生,小红书NLP团队实习生,以第一作者身份在EMNLP,NAACL等国际顶级会议发表多篇学术论文,曾获2024年KDDCup全球Top名次。主要研究方向:大模型机器翻译,大模型推理,文本表征等。
曹绍升:小红书NLP团队负责人,发表论文30余篇,授权专利100余项,引用近4000次,获得ICDE 2023年最佳工业论文奖、CIKM 2015-2020年最高引用论文、AAAI 2016最具影响力论文。此外,他荣获了中国发明协会创新成果一等奖(排名1)、中国人工智能学会吴文俊科技进步二等奖(排名1),连续4年入选世界人工智能学者榜单AI-2000新星榜前100名、Elsevier中国区高被引学者,CCTV-13《新闻直播间》采访报道。
吴健:浙江大学求是特聘教授,教育部长江学者,浙江大学国际联合学院副院长、全省医学影像人工智能重点实验室主任、人工智能医疗器械标准化技术归口单位专家组专家、中国计算机学会理事、浙江省医疗数据产业研究会理事长。研究兴趣集中在医学人工智能,发表SCI/EI收录论文200余篇。国家发明专利授权58项,获国家医疗器械注册三类证1项,二类证4项。主持国家自然科学基金项目7项、国家重点研发项目课题2项。获国家科技进步奖二等奖1项,省部科技进步一等奖3项。
刘佐珠:浙江大学国际联合学院(ZJU-UIUC Institute)研究员/博导,浙江省医学影像人工智能重点实验室副主任,浙江大学医学院附属口腔医院兼聘教授,主要研究方向为人工智能与智慧医疗。获批主持国家重点研发计划课题、国自然面青、浙江省重点、浙江大学重大横向等多项项目,参与国自然交叉重点专项和浙江省尖兵计划等项目。近年来以第一/通讯作者在Patterns、IEEE Trans、MIA、NeurIPS,ICLR、ACL、EMNLP等领域旗舰期刊和顶级会议上发表论文30余篇,并担任IJCAI/ACL/EMNLP等国际会议Area Chair。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









