







本文提出了轻量化多模态大模型LLaVA-MoD,通过集成稀疏专家混合(MoE)架构来优化小模型的网络结构,并设计了Dense-to-Sparse蒸馏框架,结合模仿蒸馏和偏好蒸馏的两阶段策略,实现全面的知识迁移。该方案仅使用0.3%的数据和23%的激活参数,即可使2B的小模型的综合性能超过7B的大模型8.8%,并在幻觉检测任务中超越教师模型。我们的研究思路与Deepseek-R1相似,均聚焦于Dense与Sparse MoE之间的知识蒸馏架构,但LLaVA-MoD在此基础上创新性地采用了逆向路径(Dense-to-Sparse),使参数效率提高了3.2倍,训练数据消耗减少了99.7%。该方法在动态平衡模型效率与表达能力的同时,为智能终端、边缘计算等应用场景提供了高性价比的解决方案,相关代码已开源。
题目:LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
机构:阿里巴巴、港中文
Paper:https://openreview.net/pdf?id=uWtLOy35WD
Code:https://github.com/shufangxun/LLaVA-MoD
引言
多模态大型语言模型(MLLM)通过将视觉编码器整合入大型语言模型(LLM)中,在多模态任务上取得了显著成效。然而,这些大型模型由于其庞大的规模和广泛的训练数据,面临着重大的计算挑战。例如,LLaVA-NeXT的最大版本利用Qwen-1.5-110B为基础,在128个H800 GPU上训练了18小时。此外,庞大的参数需求需要高性能硬件支持,导致推理速度缓慢,这使得在现实世界中,特别是在移动设备上进行部署变得更加困难。因此,探索一种在性能与效率之间实现平衡的小型多模态语言模型(s-MLLM)成为当前的重要研究课题。
s-MLLM的研究主要集中在数据收集和过滤机制上,以确保训练数据的高质量。尽管这些方法有效,但本质上限制了模型的容量。随着开源MLLM的增多,利用大型MLLM(l-MLLM)作为教师通过蒸馏其丰富的知识到s-MLLM,成为一种可行的研究方向。然而,在MLLM中实施知识蒸馏是一项全新的尝试。本文将重点关注两个主要挑战:首先,如何设计一个轻量级架构,以保持强大的学习和表达能力,从而使学生模型能够有效吸收教师模型中的复杂知识;其次,如何高效且全面地将这种知识从教师模型转移到学生模型。
方案
本文提出了 LLaVA-MoD,通过混合专家(MoE)和知识蒸馏(KD)来应对这些挑战,包括两个主要组成部分:
s-MLLM架构设计:如图1所示,设计了一个稀疏的s-MLLM以平衡性能和参数,能够高效学习多样性复杂知识。
蒸馏机制:如图2所示,设计了一个渐进式蒸馏框架,用于将知识从l-MLLM传递给稀疏的s-MLLM,包含两个阶段:模仿蒸馏和偏好蒸馏。
稀疏架构设计
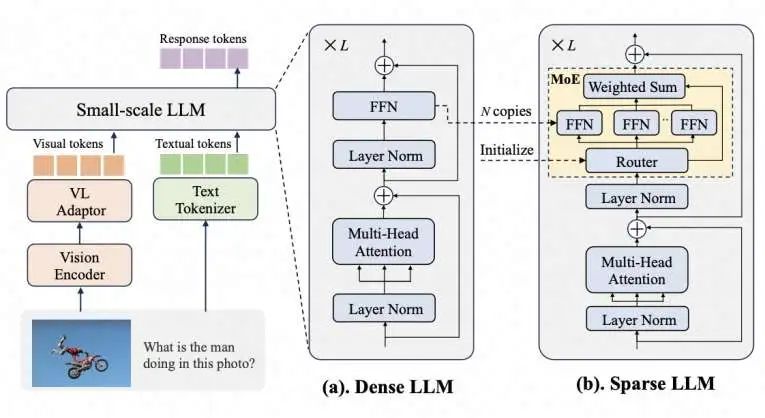
如图1所示,s-MLLM包含三个主要组件:视觉编码器(Vision Encoder)、大型语言模型(LLM)和视觉语言适配器(VL Adaptor)。构建s-MLLM的原则是保持Vision Encoder和VL Adaptor不变,同时引入混合专家(MoE)架构,将LLM从稠密型转化为稀疏型。具体而言,我们通过稀疏升采样(sparse upcycling)将多个前馈网络(FFN)复制为专家模块。此外,增加了一个线性层作为路由器,以动态预测专家分配的概率,从而激活合适的专家。在训练和推理阶段,专家模块能够以动态和稀疏的方式被激活,从而在增加模型容量的同时实现高效的训练和推理过程。
渐进式蒸馏
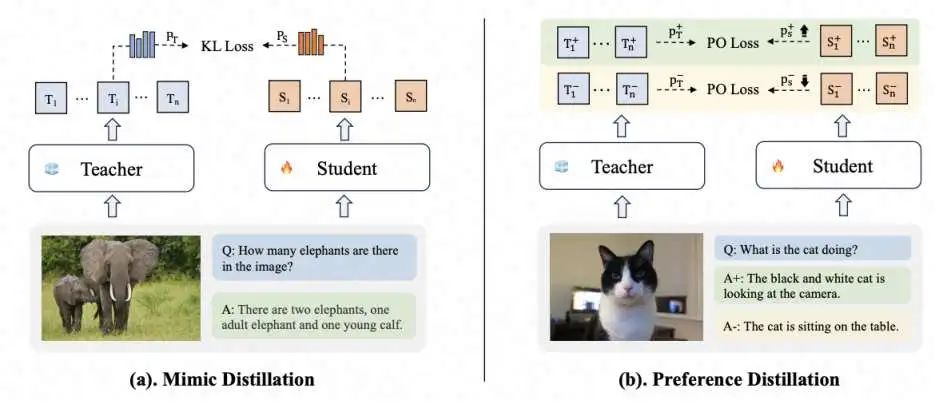
渐进蒸馏包括两个不同的阶段,如图2,即模拟蒸馏和偏好蒸馏。在模仿蒸馏阶段,学生MLLM 模拟教师MLLM 的通用和专家知识。在偏好蒸馏阶段,学生MLLM基于教师MLLM的偏好知识,以进一步优化其输出并减少幻觉。
模仿蒸馏
由于教师MLLM的知识丰富且复杂,学生MLLM难以一步掌握,因此我们将知识分解为通用知识和专业知识,分别进行密集到密集蒸馏和密集到稀疏蒸馏,以将这两个方面的知识传递给学生MLLM。
密集到密集蒸馏:在这一阶段,核心目标是学习教师MLLM的通用知识。通用知识至关重要,因为它为多个领域提供了广泛的基础和共同理解,使学生MLLM能够建立适用于多种场景的基本框架。这个基础支持学生在进入特定任务之前,拥有更全面和灵活的理解。具体而言,我们利用通用的图像-标题对和对话数据来更新LLM和VL Adaptor。
密集到稀疏蒸馏:在这一阶段,通过引入混合专家(MoE)结构,学生MLLM能够针对不同任务和输入选择性地激活最相关的专家,从而在模拟教师的专业知识方面获得显著优势。具体来说,在训练过程中,我们利用多任务数据,采用Top-k路由策略选择专家,仅更新这些专家和VL Adaptor。
偏好蒸馏
在这一阶段,我们基于教师MLLM中的偏好知识,指导学生MLLM生成不仅准确而且合理的响应,这对于减少幻觉至关重要。偏好蒸馏受到离散描述偏好优化(DPO)进展的启发,将教师MLLM视为参考模型,发挥关键作用,因为它提供了“好”和“坏”的见解,从而为学生模型建立一个基本参考。具体而言,训练目标是优化学生模型,使其在区分正面和负面响应时,为正面响应分配比教师模型更高的概率,同时为负面响应分配比教师模型更低的概率。
实验结果
我们采用了成熟的"ViT-MLP-LLM"架构来证明LLaVA-MoD的有效性。在模拟蒸馏中,使用2.4M通用captioning和对话样本来学习教师MLLM的通用知识,以及1.4M多任务数据,包括VQA、文档、科学和OCR,以学习教师MLLM的专业知识。在偏好蒸馏中,使用8W偏好样本来学习教师偏好知识。评估benchmark包括多模态理解、推理和幻觉。
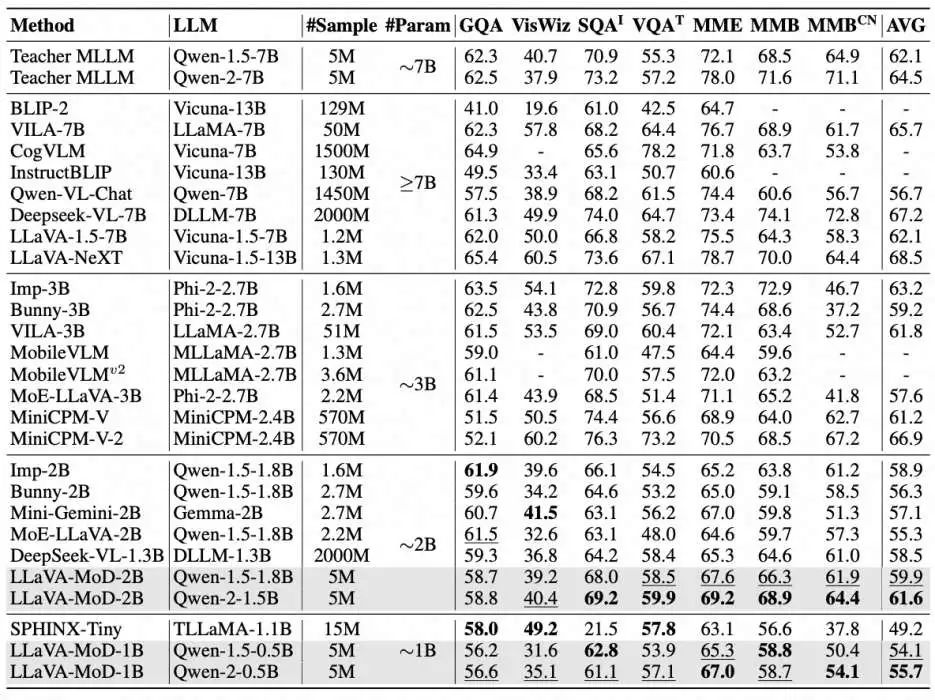
多模态理解和推理:表21表明,LLaVA-MoD在以理解为导向的基准测试上表现出色。在2B规模和1B规模的模型中,它分别取得了最先进的平均结果。
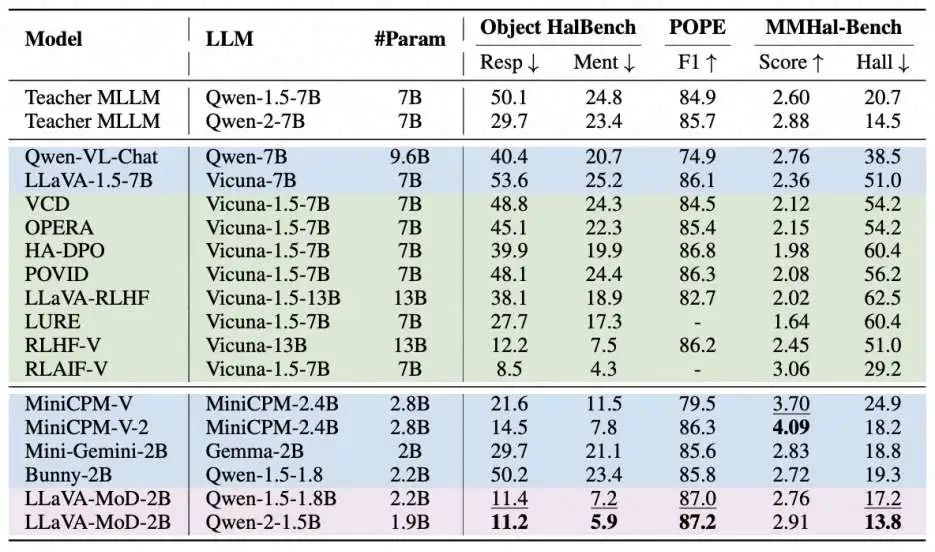
幻觉消除:如表2所示,LLaVA-MoD在减轻幻觉方面表现出色,甚至超过了其教师模型。这可以归因于两个方面:首先,通过为正响应分配更高的概率,偏好蒸馏鼓励学生模型专注于提供正确和相关的信息。其次,通过为负响应分配较低的概率,偏好蒸馏 discourages错误或不实的信息。利用教师模型作为参考调整响应概率,这种优化使学生模型更准确、可靠地处理幻觉问题,从而超过了教师模型。
结论
本文提出了LLaVA-MoD,用于通过知识蒸馏从l-MLLM中高效训练s-MLLM。该框架解决了MLLM蒸馏的两个关键挑战:使用MoE设计增强s-MLLM架构的效率和表达能力平衡,并实现了一种渐进式知识转移策略。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









