







MobileNetv4
轻量化之王MobileNetV4,手机推理速度3.8ms,在移动CPU、DSP、GPU以及苹果M处理器和谷歌Pixel Edge TPU全都高性能。
论文
MobileNetV4 - Universal Models for the Mobile Ecosystem
模型结构
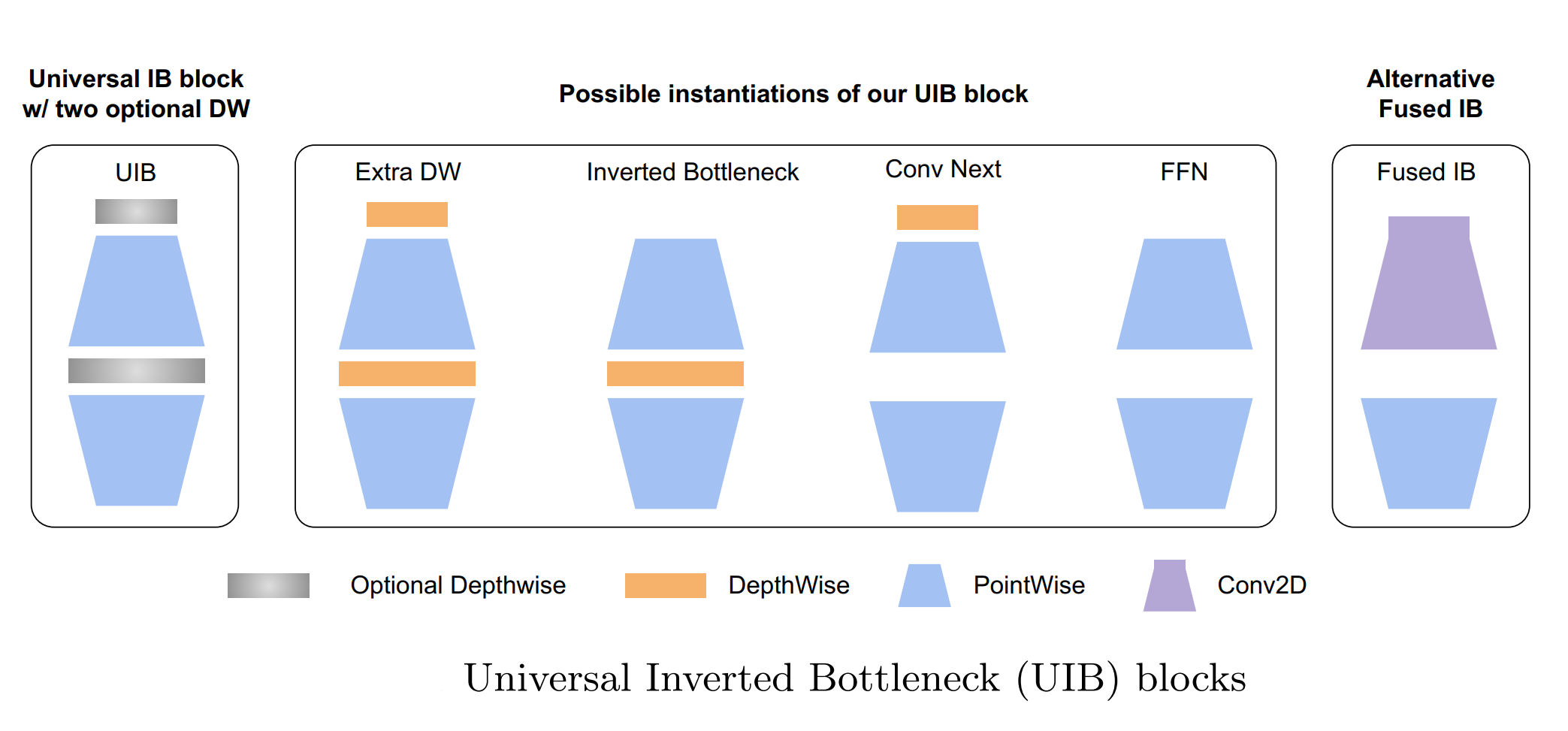
通用UIB块在倒瓶颈块中引入两个可选的DW,一个在扩展层之前,另一个在扩展层和投影层之间,很好地统一了几个重要现有块,包括原始的IB块、ConvNext块以及ViT中的FFN块。此外,UIB还引入了一种新的变体:额外的深度卷积IB(ExtraDW)块;MobileMQA一个专为加速器优化的新型注意力块,它能提供超过39%的推理速度提升。
算法原理
利用标准组件引入新的通用反转瓶颈UIB和移动MQA层,并结合改进的神经架构搜索(NAS)方法改进mobilenet,然后将这些与一种新颖的、最先进的蒸馏方法相结合。
环境配置
mv mobilenetv4_pytorch MobileNetv4 # 去框架名后缀
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3842
3842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











