







UMT5
注:执行下游任务是需要使用进行预训练, 训练代码参考train_model.py。

论文
模型结构
umT5:T5 的多语言版本,具备 T5 模型大部分的多功能性,在多语言通用爬虫语料库 mC4 上预训练,覆盖 101 种语言;Encoder-Decoder架构,编码层和解码层都是12层,一共有220M个参数,大概是bert-base 的两倍。
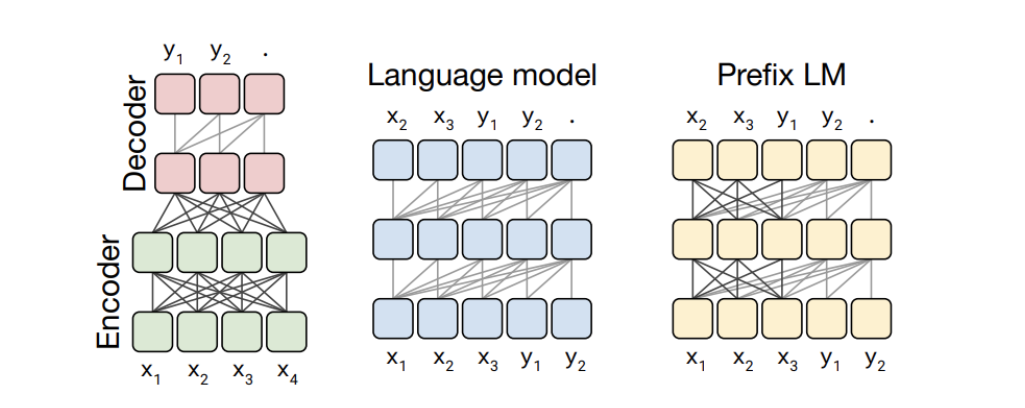
算法原理
总的来说,mT5 跟 T5 一脉相承的,整体基本一样,但在模型结构方面,mT5 用的是 T5.1.1方案,在此对它做个基本的介绍。
它主要的改动来自论文GLU Variants Improve Transformer,主要是借用了Language Modeling with Gated Convolutional Networks 的GLU(Gated Linear Unit)来增强 FFN 部分的效果。具体来说,原来 T5 的 FFN 为(T5 没有 Bias):

改为:

T5 Transformer
环境配置
Docker(方法一)
光源拉取docker镜像的地址与使用步骤
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu22.04-dtk23.10.1-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name umt5 <your imageID> bash
cd /path/your_code_data/umt5
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
Dockerfile(方法二)
cd /path/your_code_data/umt5/docker
docker build --no-cache -t umt5:latest .
docker run --shm-size=64G --name umt5 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it umt5 bash
Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
DTK驱动:dtk23.10
python:python3.10
torch:2.1.0
torchvision:0.16.0
deepspeed:0.12.3
Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
conda create -n umt5 python=3.10
conda activate umt5
cd /path/your_code_data/umt5
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
数据集
我们选择大规模中文短文本摘要语料库LCSTS 作为数据集,该语料基于新浪微博短新闻构建,规模超过 200 万。
数据处理以包含在model_train.py和model_test.py中不用单独运行数据处理代码。
项目中已提供用于试验训练的迷你数据集,训练数据目录结构如下,用于正常训练的完整数据集请按此目录结构进行制备:
── dataset
│ ├── lcsts_tsv
│ ├── data1.tsv
│ ├── data2.tsv
│ └── data3.tsv
│——————————
训练
单机多卡
python multi_dcu_train.py
单机单卡
python multi_dcu_test.py
推理
推理前需要进行预训练
单机多卡
python multi_dcu_test.py
摘要任务
要进行摘要任务需先进行模型训练,从hf-mirror或者huggingface下载umt5-base模型后,使用multi_dcu_train.py进行训练,保存训练权重后,加载权重进行摘要处理。同理,若要处理阅读理解,语言翻译任务时也需要做类似操作。
python umt5_summary.py
result

精度
测试数据:LCSTS,使用的加速卡:V100S/K100。
根据测试结果情况填写表格:
| device | Rougue 1 | Rougue 2 | Rougue L |
|---|---|---|---|
| V100s | 26.12 | 14.81 | 23.62 |
| K100 | 26.94 | 15.38 | 24.24 |
应用场景
算法类别
文本摘要
热点应用行业
金融,教育,政府,科研,制造,能源,广媒
















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











