






在机器学习众多算法中,集成学习技术以其卓越的预测性能和稳健性熠熠生辉。CatBoost、XGBoost和LightGBM,被誉为“集成学习三剑客”,以其独特的优势在众多模型中脱颖而出。本文将带您一探究竟,如何充分利用这三款明星模型的GPU加速能力、样本权重调整技巧以及自定义评估函数的实现,让您的模型训练事半功倍。
🌠 为何钟爱这三款模型?
XGBoost:性能与灵活性的典范
- 性能卓越:XGBoost以其优秀的性能和灵活性著称,支持自定义损失函数和评估指标,使其在各种机器学习任务中都能大放异彩。
LightGBM:速度与效率的先锋
- 速度与效率:由微软推出的LightGBM强调高速度和低内存使用,采用独创的Gradient-based One-Side Sampling (GOSS)技术,使其在处理大规模数据集时更加得心应手。
CatBoost:类别变量的克星
- 类别变量处理:CatBoost来自俄罗斯的Yandex公司,特别擅长处理类别变量,无需手动编码,大大简化了数据预处理的工作。
💼 GPU版本的优势
加速训练:GPU并行计算的威力
- 加速训练:相比CPU,GPU的并行计算能力更强,能够大幅缩短模型训练时间。
处理大数据:GPU内存的优势
- 大数据集的最佳伴侣:GPU适合处理大规模数据集,能够充分发挥其内存优势。
🔍 样本权重的定义与应用
调整样本重要性
- 样本权重:样本权重用于调整训练过程中每个样本的重要性,尤其适用于处理样本不均衡或特定样本更关键的场景。
传入样本权重
- CatBoost:
catboost_reg.fit(X, y, sample_weight=sample_weight) - XGBoost:
xgb.DMatrix(X, y, weight=sample_weight) - LightGBM:
lgb.Dataset(X, label=y, weight=sample_weight)
🎯 自定义评估函数的实现
精准评估模型性能
- 自定义R²评估函数:为了更好地评估模型性能,我们为每个模型实现了自定义的R²评估函数。
实现方法
- CatBoost:通过继承CatBoost的Metric类来定义
r2_cbt。 - XGBoost:通过
feval参数传入自定义函数r2_xgb。 - LightGBM:通过
feval参数传入自定义函数r2_lgb。
🛠️ 代码实现与示例
CatBoost训练函数
注意:目前catboost自定义评估函数是不能在GPU上运行的,使用过程中需要2选一
def train_run_catboost_model(X, y, params, sample_weight=None):
# 参数设置
params_catboost = {
'iterations': params['iterations'],
'learning_rate': params['learning_rate'],
'depth': params['depth'],
'eval_metric': r2_cbt(), # 自定义评估函数
'random_seed': 42,
#'task_type': "GPU",
"bootstrap_type": 'No'
}
catboost_reg = CatBoostRegressor(**params_catboost)
catboost_reg.fit(X, y, sample_weight=sample_weight)
return catboost_regXGBoost训练函数
def train_run_xgboost_model(X, y, params, sample_weight=None):
# 参数设置
params_xgb = {
'eta': params['learning_rate'],
'max_depth': params['depth'],
'objective': 'reg:squarederror',
'tree_method': 'gpu_hist',
'seed': 42
}
xgb_trn = xgb.DMatrix(X, y, weight=sample_weight)
xgb_reg = xgb.train(params=params_xgb, dtrain=xgb_trn,
feval=lambda preds, dtrain: r2_xgb(dtrain.get_label(), preds, dtrain.get_weight()),
evals=[(xgb_trn, 'train')])
return xgb_regLightGBM训练函数
def train_run_lightgbm_model(X, y, params, sample_weight=None):
num_rounds, learning_rate, max_depth, num_leaves = params['iterations'], params['learning_rate'], params['depth'], \
params['num_leaves']
params_lgb = {
'objective': 'regression',
'metric': 'rmse',
'boosting_type': 'gbdt',
'num_leaves': num_leaves,
'learning_rate': learning_rate,
'max_depth': max_depth,
'device': 'gpu',
'seed': 42
}
# 自定义回调函数
def print_info(env):
if env.iteration % 500 == 0:
print(f"Iteration {env.iteration}, Training's RMSE: {env.evaluation_result_list[0][2]}")
train_data = lgb.Dataset(X, label=y, weight=sample_weight)
lgb_reg = lgb.train(
params=params_lgb,
train_set=train_data,
feval=lambda preds, dtrain: r2_lgb(dtrain.get_label(), preds, dtrain.get_weight()),
valid_sets=[train_data, train_data],
callbacks=[print_info]
# verbose_eval=20
)
return lgb_reg自定义损失函数
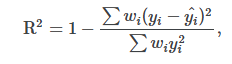
该段代码,参考
Jane Street Real-Time Market Data Forecasting Baseline模型分享-CSDN博客
def r2_xgb(y_true, y_pred, sample_weight):
r2 = 1 - np.average((y_pred - y_true) ** 2, weights=sample_weight) / (np.average((y_true) ** 2, weights=sample_weight) + 1e-38)
return -r2
# Custom R2 metric for LightGBM
def r2_lgb(y_true, y_pred, sample_weight):
r2 = 1 - np.average((y_pred - y_true) ** 2, weights=sample_weight) / (np.average((y_true) ** 2, weights=sample_weight) + 1e-38)
return 'r2', r2, True
# Custom R2 metric for CatBoost
class r2_cbt(object):
def get_final_error(self, error, weight):
return 1 - error / (weight + 1e-38)
def is_max_optimal(self):
return True
def evaluate(self, approxes, target, weight):
assert len(approxes) == 1
assert len(target) == len(approxes[0])
approx = approxes[0]
error_sum = 0.0
weight_sum = 0.0
for i in range(len(approx)):
w = 1.0 if weight is None else weight[i]
weight_sum += w * (target[i] ** 2)
error_sum += w * ((approx[i] - target[i]) ** 2)
return error_sum, weight_sum模型调用示例
model_dict={}
# 使用CatBoost
cat_param_one = {"depth": 10, "iterations": 4000, "learning_rate": 0.06}
cat_model = train_run_catboost_model(X_train, y_train, cat_param_one, sample_weight=w_train)
model_dict['cat'] = cat_model
# 使用XGBoost
xgb_param_one = {"depth": 11, "iterations": 400, "learning_rate": 0.06}
xgb_model = train_run_xgboost_model(X_train, y_train, xgb_param_one, sample_weight=w_train)
model_dict['xgb'] = xgb_model
# 使用LightGBM
lgb_param_one = {'depth': 8, 'learning_rate': 0.065, 'iterations': 3500, 'num_leaves': 40}
lgb_model = train_run_lightgbm_model(X_train, y_train, lgb_param_one, sample_weight=w_train)
model_dict['lgb'] = lgb_model模型保存
model_path = 'path/to/save/models'
now_model_path = os.path.join(model_path, 'model.pkl')
with gzip.open(now_model_path, 'wb', compresslevel=3) as f:
pickle.dump(model_dict, f)🏁 注意
catboost在GPU模式下不支持自定义评估函数

















 3762
3762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









