







前期准备
数据集准备:
1、图像准备:首先获取所研究的目标的游戏的道具截图:
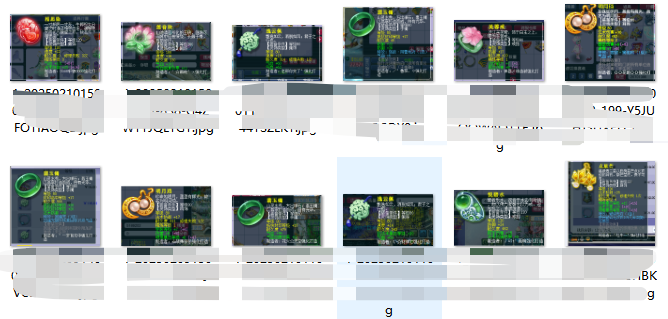
2、标签准备
由于没有标准的标签数据,为了快速制作数据集标签,借助Qwen2-VL-2B-OCR"https://huggingface.co/JackChew/Qwen2-VL-2B-OCR/tree/main"模型对图像进行初步识别,将识别的结果作为标签,为了微调的效果,需要对表标签质量进行把关,针对你的应用场景,归纳出目标游戏道具的一些固定字段,特殊字段,字段的组合,字段的取值范围,等等知识结合起来,对有错误的标签进行修正,直到标签全部正确。

按照qwen2vl需要的训练数据格式对数据进行预处理,对应的函数如下:
# 获取数据
instruction = "识别图像中的文字内容,并按照顺序输出结果"
from PIL import Image
def convert_to_conversation(sample):
conversation = [
{ "role": "user",
"content" : [
{"type" : "text", "text" : instruction},
{"type" : "image", "image" : Image.open(sample['conversations'][0]['value'].split('/')[-1]).convert("RGB")} ]
},
{ "role" : "assistant",
"content" : [
{"type" : "text", "text" : sample['conversations'][1]['value']} ]
},
]
return { "messages" : conversation }
pass对图像,进行缩放,二值化,等等一系列操纵,最终获得数据集6W条
环境安装
由于显卡资源的限制,以及训练时间的成本控制,也借鉴其他人的微调经验,最后选择了使用unsloth框架进行微调,框架安装请按照unsloth官网进行(过程很曲折,请自行解决)
微调开始
- 导入需要的库
from unsloth import FastLanguageModel
import os
# 设置缓存路径到D盘
os.environ["HF_DATASETS_CACHE"] = "D:/huggingface/datasets"
os.environ["TRANSFORMERS_CACHE"] = "D:/huggingface/transformers"
from unsloth import FastVisionModel # FastLanguageModel for LLMs
import torch
import json- 加载模型
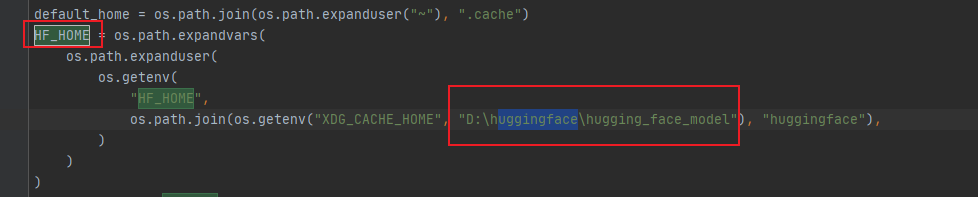
这里需要注意的上,当选择了下载到本地的模型之后。load_in_4bit需要设置成False,应为Qwen2-VL-2B-Instruct数据16bit模型,若未设置成False,会自动下载模型到C盘,造成资源浪费
model, tokenizer = FastVisionModel.from_pretrained(
# "unsloth/Qwen2-VL-2B-Instruct",
'D:/model/Qwen2-VL-2B-Instruct',
load_in_4bit = False, # Use 4bit to reduce memory use. False for 16bit LoRA.
use_gradient_checkpointing = "unsloth", # True or "unsloth" for long context
)补充:如果想要修改huggingface模型下载的默认位置,需要找你的虚拟环境xxx\env\rag\Lib\site-packages\huggingface_hub\constants.py文件,将里面的路径修改到你的目标路径
- 配置loar微调
# ===============================================配置Lora微调========================================
model = FastVisionModel.get_peft_model(
# 微调配置:
model,
finetune_vision_layers = True, # 微调视觉部分的层
finetune_language_layers = True, # 微调语言部分的层
finetune_attention_modules = True, # 微调注意力模块
finetune_mlp_modules = True, # 微调多层感知机模块
# Lora参数
r = 16, # 秩。越大,模型表达能力越强,但是可能过拟合。
lora_alpha = 16, # Lora的缩放因子,通常简易alpha==r
lora_dropout = 0, # dropout率,设置为0表述不启用dropout
bias = "none", # 不添加额外的偏置参数
random_state = 3407, # 随机种子,确保试验可以复现
use_rslora = False, # 是否启用rslora(一种改进的LoRA)
loftq_config = None, # 是否使用Loftq(一种量化方法)
# target_modules = "all-linear", # Optional now! Can specify a list if needed
)- 获取数据集
# 获取数据
instruction = "识别图像中的文字内容,并按照顺序输出结果"
from PIL import Image
def convert_to_conversation(sample):
conversation = [
{ "role": "user",
"content" : [
{"type" : "text", "text" : instruction},
{"type" : "image", "image" : Image.open(sample['conversations'][0]['value'].split('/')[-1]).convert("RGB")} ]
},
{ "role" : "assistant",
"content" : [
{"type" : "text", "text" : sample['conversations'][1]['value']} ]
},
]
return { "messages" : conversation }
pass
import json
train_dataset_json_path = r"D:\work\ocr\image_ocr\test\linshi\new_linshi_train.json"
# 读取 JSON 文件并修改路径
with open(train_dataset_json_path, 'r',encoding="utf-8") as f:
train_data = json.load(f)
converted_dataset = [convert_to_conversation(sample) for sample in train_data]
- 配置微调的超参数
from unsloth import is_bf16_supported
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable for training!
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
data_collator = UnslothVisionDataCollator(model, tokenizer), # Must use!
train_dataset = converted_dataset,
args = SFTConfig(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# max_steps = 60,
num_train_epochs = 2, # Set this instead of max_steps for full training runs
learning_rate = 2e-4,
fp16 = not is_bf16_supported(),
bf16 = is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # For Weights and Biases
# You MUST put the below items for vision finetuning:
remove_unused_columns = False,
dataset_text_field = "",
dataset_kwargs = {"skip_prepare_dataset": True},
dataset_num_proc = 4,
max_seq_length = 2048,
),
)- 查看显卡情况
# @title Show current memory stats
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")- 开始训练
trainer_stats = trainer.train()- 保存lora模型
model.save_pretrained("new_lora_model") # Local saving
tokenizer.save_pretrained("new_lora_model")- 模型合并
from transformers import AutoModelForCausalLM, AutoTokenizer, Qwen2VLForConditionalGeneration, AutoProcessor
from peft import PeftModel
import torch
import os
import argparse
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--base_model_name_or_path", type=str,default='D:\\model\\Qwen2-VL-2B-Instruct')
parser.add_argument("--peft_model_path", type=str,default='D:\\work\\ocr\\qwen2_loar\\unsloth_try\\new_lora_model')
parser.add_argument("--output_dir", type=str,default='D:\\work\\ocr\\qwen2_loar\\unsloth_try\\lingshi_qwen2_ocr_new')
parser.add_argument("--device", type=str, default="auto")
parser.add_argument("--push_to_hub", action="store_false")
return parser.parse_args()
def main():
args = get_args()
if args.device == 'auto':
device_arg = { 'device_map': 'auto' }
else:
device_arg = { 'device_map': { "": args.device} }
print(f"Loading base model: {args.base_model_name_or_path}")
base_model = Qwen2VLForConditionalGeneration.from_pretrained(
args.base_model_name_or_path,
return_dict=True,
torch_dtype=torch.float16,
**device_arg
)
print(f"Loading PEFT: {args.peft_model_path}")
model = PeftModel.from_pretrained(base_model, args.peft_model_path, **device_arg)
print(f"Running merge_and_unload")
model = model.merge_and_unload()
tokenizer = AutoProcessor.from_pretrained(args.base_model_name_or_path)
# if args.push_to_hub:
# print(f"Saving to hub ...")
# model.push_to_hub(f"{args.output_dir}", use_temp_dir=False)
# tokenizer.push_to_hub(f"{args.output_dir}", use_temp_dir=False)
# else:
model.save_pretrained(f"{args.output_dir}")
tokenizer.save_pretrained(f"{args.output_dir}")
print(f"Model saved to {args.output_dir}")
if __name__ == "__main__" :
main()参考来源如下:
模型:
https://huggingface.co/JackChew/Qwen2-VL-2B-OCR
https://huggingface.co/unsloth/Qwen2-VL-2B-Instruct
训练代码:
模型合并代码:

















 1704
1704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









