






摘要
微调是利用大型预训练语言模型来执行下游任务时所使用的方法。但是,它修改了语言模型中所有模块的参数,因此需要为每个任务存储全拷贝。在本文中,我们提出了Prefix-Tuning,一种轻量级替代方法,用于对自然语言生成任务进行微调,在使语言模型参数冻结的同时,去优化一个参数量少的 continuous task-specific vector(称为prefix)。Prefix-Tuning方法启发于prompting的灵感,prompting允许子序列字符填加到此前缀后,并把prompting作为“virtual tokens”。 我们将prefix-tuning应用于GPT-2,用于表格到文本的生成,也应用于BART,以进行文本摘要。我们发现,通过学习仅0.1%的参数,prefix-tuning在完整数据配置中获得了与baseline可比的性能,并在低资源情况下优于的baseline,并且,该方法能更好地生成在训练期间没见过的主题。
1.介绍
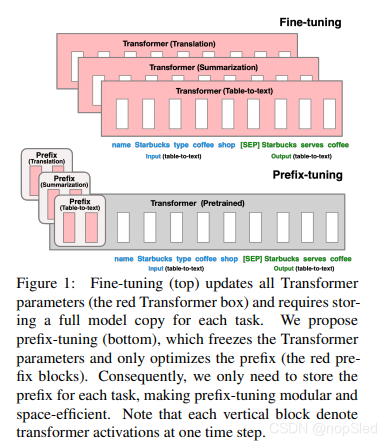
微调是利用大型预训练语言模型(LM)来执行下游任务(例如,摘要)时所使用的方法,但它需要更新和存储LM的所有参数。因此,要构建和部署依赖于预训练语言模型的NLP系统,目前需要单独为每个任务对LM参数修改后的模型进行存储。考虑到LM的大尺寸,这可能会很话费很大的存储空间。例如,GPT-2具有774M参数,GPT-3具有175B参数。
这种问题的一个自然解决方法是轻量级微调,它冻结了大部分预训练模型的参数,并使用一个小训练模块来增强预训练模型。例如,adapter-tuning在预训练语言模型各层之间插入额外的特定任务的层。 Adapter-tuning在自然语言理解和生成基准上,实现了可比的性能,同时仅添加约2-4%的特定任务的参数。
极端情况下,GPT-3甚至不需要任何特定任务的finetune,就可以被使用。或者,用户仅需添加某个自然语言任务指令(例如,摘要任务中的TL;DR)以及少量的输入样例,然后就能从LM生成输出。这种方法被称为in-context learning或prompting。
在本文中,我们提出了Prefix-Tuning,一种轻量级替代方法,可以用于自然语言生成(NLG)任务。考虑生成一个数据表格的文字描述的任务,如图1所示,任务输入是表格的线性表示(例如,“name: Starbucks | type: coffee shop”),输出是文字描述(例如,“Starbucks serves coffee.”)。Prefix-tuning将一系列continuous task-specific的向量序列添加到输入中,我们称之为prefix,如图1下方所示的红色块。Prefix作为子序列字符,Transformer可以把它作为一系列“virtual tokens”进行计算,但与prompting不同,prefix完全由不对应于真实字符的参数组成。与图1上方中的微调相比,Prefix-tuning仅优化prefix参数。因此,我们只需要存储一个大型transformer模型和多个学习的任务特定的prefix参数,这对每个任务仅产生了非常小的开销(例如,表到文本任务仅需要250k参数)。
与微调方法相比,Prefix-Tuning是模块化的:我们训练一个上游prefix,来指导下游未被修改的LM。因此,单个LM可以立即支持许多任务。在对应于不同用户的个性化任务中,我们可以仅在该用户的数据上训练出用户单独的prefix,从而避免数据交叉污染。此外,基于prefix的架构使我们甚至可以在单个batch中处理多用户或多任务数据,而这对其他轻量级fine-tuning方法是不可能的。
我们将prefix-tuning应用于GPT-2,用于表格到文本的生成,也应用于BART,以进行文本摘要。在存储方面,Prefix-tuning存储比微调更少的参数。在性能方面,当在完整数据集上训练时,表格到文本(§6.1)任务上Prefix-tuning与fine-tune相当, 而在摘要(§6.2)任务则略微下降。在低资源配置中,Prefix-tuning在两项任务上均要由于fine-tune(第6.3节)。
2.相关工作
(1)Fine-tuning for natural language generation
目前最好的用于自然语言生成的系统是基于预训练语言模型LM微调的。对于table-to-text 生成,Kale (2020) 微调了一个序列到序列模型(T5)。对于抽取式和生成式摘要,研究人员分别微调了屏蔽语言模型(例如,BERT)和编码器-解码器模型(例如,BART)。对于其他条件NLG任务,如机器翻译和对话生成,微调也是普遍的范式。在本文中,尽管我们专注于在表格到文本任务使用GPT-2,在照样任务中使用BART,但是prefix-tuning仍可以应用于其他生成任务和预训练模型。
(2)Lightweight fine-tuning
轻量级FineTuning冻结了大部分预训练参数,并使用小型训练模块或修改少部分预训练参数。关键挑战是寻找模块高性能架构和调整预训练模型的部分参数。一项研究考虑删除参数:通过训练针对参数的二进制掩码来消除一些模型参数。另一行研究考虑了插入参数。 例如,Zhang et al. (2020a) 训练了一个“side”网络,该网络通过求和与预训练模型融合;adapter-tuning在预训练LM的每层之间插入任务特定的层。与这些调整了LM大约3.6%参数的工作相比,我们的方法在特定任务的参数上减少了30倍,在保持性能可比的同时仅调整0.1%的参数。
(3)Prompting
Prompting是指将指令和一些例子前置到任务输入并从LM生成输出。GPT-3手动设计提示来调整其不同任务的生成,并且此框架被称为in-context learning。但是,由于Transformers只能在有限长度上下文(例如,GPT3的2048个token)上生成,因此in-context learning无法完全利用比上下文窗口更长的训练集。Sun and Lai (2020) 也通过关键字提示来控制生成的句子的情绪或主题。在自然语言理解任务中,在BERT和RoBERTa这样的模型中已经探索了prompt方法。例如,AutoPrompt搜索一系列离散触发词并将其连接到每个输入,以引出来自屏蔽LM的情感或事实知识。与AutoPrompt相比,我们的方法优化了连续前缀,这些前缀是更具表现力的(§7.2);此外,我们专注于语言生成任务。
连续向量已被用于控制语言模型。例如,Subramani et al. (2020) 展示了预训练LSTM语言模型可以通过优化特定于每个句子的连续向量来重建任意句子。相比之下, prefix-tuning优化了任务特定的前缀,并将其应用于该任务的所有输入。因此,与先前的限制句子结构的工作不同,prefix-tuning可以应用于NLG任务。
(4)Controllable generation
可控生成旨在控制预训练语言模型以匹配句子级属性(例如,体育领域的积极情绪或主题)。这种控制可以在模型训练时使用:Keskar et al. (2019) 预训练了以元数据(如keywords或URL)为条件的语言模型(CTRL)。除此之前,通过加权解码(GEDI)或迭代地更新过去的激活(PPLM),可以在解码时刻控制输出。然而,没有直接的方式来应用这些可控生成技术来对生成的内容进行细粒度控制,如table-to-text和摘要等任务所要求的。
3.问题描述

考虑一个条件生成任务,其中输入是上下文
x
x
x,输出
y
y
y是一系列字符。我们专注于两个任务,如图2(右)所示:在table-to-text任务中,
x
x
x对应于线性表示数据表,
y
y
y是文本描述;在摘要任务中,
x
x
x是一篇文章,
y
y
y是简短的摘要。
3.1 Autoregressive LM
假设我们有一个基于Transformer架构(例如,GPT-2)和由
ϕ
\phi
ϕ参数化的自回归语言模型
p
ϕ
(
y
∣
x
)
p_{\phi}(y|x)
pϕ(y∣x)。如图2(上)所示,令
z
=
[
x
;
y
]
z=[x;y]
z=[x;y]是
x
x
x和
y
y
y的串联,
X
i
d
x
\textbf X_{idx}
Xidx表示与
x
x
x对应的索引序列,而
Y
i
d
x
\textbf Y_{idx}
Yidx表示与
y
y
y对应的索引序列。
在时刻
i
i
i的激活表示为
h
i
∈
R
d
h_i∈\mathbb R^d
hi∈Rd,其中
h
i
=
[
h
i
(
1
)
;
⋅
⋅
⋅
;
h
i
(
n
)
]
h_i =[h^{(1)}_i;···;h^{(n)}_i]
hi=[hi(1);⋅⋅⋅;hi(n)]为在此时刻中的所有激活层的拼接,
h
i
(
j
)
h^{(j)}_i
hi(j)在时刻
i
i
i是第
j
j
j个Transformer层的激活。
自回归Transformer模型将左上文的历史激活和
z
i
z_i
zi作为输入来计算
h
i
h_i
hi,如下所示:
h
i
=
L
M
ϕ
(
z
i
,
h
<
i
)
,
(1)
h_i=LM_{\phi}(z_i,h_{\lt i}),\tag{1}
hi=LMϕ(zi,h<i),(1)
其中,最后一层的
h
i
h_i
hi被用来计算下一个字符的概率分布:
p
ϕ
(
z
i
+
1
∣
h
≤
i
)
=
s
o
f
t
m
a
x
(
W
ϕ
h
i
(
n
)
)
p_{\phi}(z_{i+1}|h_{≤i})=softmax(W_{\phi}h^{(n)}_i)
pϕ(zi+1∣h≤i)=softmax(Wϕhi(n)),
W
ϕ
W_{\phi}
Wϕ是将
h
i
(
n
)
h^{(n)}_i
hi(n)映射到词汇分布的预训练矩阵。
3.2 Encoder-Decoder Architecture
我们还可以使用编码器-解码器架构(例如,BART)来建模 p ϕ ( y ∣ x ) p_{\phi}(y|x) pϕ(y∣x),其中 x x x由双向编码器编码,并且解码器自回归地去预测 y y y(在编码的 x x x及其左上文为输入)。我们使用相同的索引和激活表示法,如图2所示(底部)所示。对于 h i , i ∈ X i d x h_i,i∈\textbf X_{idx} hi,i∈Xidx由双向Transformer编码器计算,对于 h i , i ∈ Y i d x h_i,i∈\textbf Y_{idx} hi,i∈Yidx,由自回归解码器使用相同的等式(1)计算。
3.3 Method: Fine-tuning
在微调框架中,我们用预训练参数
ϕ
\phi
ϕ初始化。我们对以下对数似然目标执行梯度更新,其中
p
ϕ
p_{\phi}
pϕ是可训练的语言模型分布:
m
a
x
ϕ
l
o
g
p
ϕ
(
y
∣
x
)
=
∑
i
∈
Y
i
d
x
l
o
g
p
ϕ
(
z
i
∣
h
<
i
)
.
(2)
\mathop{max}\limits_{\phi}\quad log~p_{\phi}(y|x)=\sum_{i\in \textbf Y_{idx}}log~p_{\phi}(z_i|h_{\lt i}).\tag{2}
ϕmaxlog pϕ(y∣x)=i∈Yidx∑log pϕ(zi∣h<i).(2)
4.Prefix-Tuning
我们提出了prefix-tuning来作为条件生成任务中fine-tuning的替代方案。我们首先在§4.1节中描述该方法提出的直觉,然后在§4.2节中正式定义我们的方法。
4.1 Intuition
基于prompting方法的直觉,我们认为具有适当的上下文可以在不改变参数的情况下来引导LM。例如,如果我们希望LM生成一个单词(例如,obama),我们可以将其常见的搭配作为上下文(例如,arback)添加到单词前,这样LM将为所需生成的词分配更高的概率。将这种直觉扩展到生成一个完整上下文的情况,我们想找到一个让LM能够解决NLG任务。直观地,上下文可以通过引导从
x
x
x中提取的内容来影响
x
x
x的编码,并且可以通过控制下一个字符的分布来影响
y
y
y的生成。但是,是否存在这样的上下文,这是不明确的。自然语言任务命令(例如,“summarize the following table in one sentence”)可能会指导专家标注来解决任务,但对大多数的预训练LM是没用的。通过离散指令这种数据驱动的优化方法可能有所帮助,但离散优化在计算效率上具有挑战性的。
我们可以将这一命令作为连续字符嵌入来优化,其影响将向上传播到所有Transformer激活层,并向向右传播给后续字符。 这比一个离散的需要匹配真实词嵌入的提示更严格且更具表现力。同时,这比在所有激活层都插入提示所需表现力要小,这避免了远程依赖性并包括更多可调参数。因此,Prefix-tuning优化了prefix的所有层。
4.2 Method
Prefix-tuning将自回归LM的prefix添加到序列前,以获取
z
=
[
P
R
E
F
I
X
;
x
;
y
]
z=[PREFIX;x;y]
z=[PREFIX;x;y],或者为编码器和编码器都添加prefix,以获取
z
=
[
P
R
E
F
I
X
;
x
;
P
R
E
F
I
X
′
;
y
]
z=[PREFIX;x;PREFIX';y]
z=[PREFIX;x;PREFIX′;y],如图2所示。在这里,我们使用
P
i
d
x
\textbf P_{idx}
Pidx表示前缀索引序列,
∣
P
i
d
x
∣
|\textbf P_{idx}|
∣Pidx∣表示前缀的长度。
我们遵循等式(1)中的循环关系,其中prefix是可训练参数。Prefix-tuning初始化一个维度为
∣
P
i
d
x
∣
×
d
i
m
(
h
i
)
|\textbf P_{idx}|×dim(h_i)
∣Pidx∣×dim(hi)的可训练矩阵
P
θ
P_θ
Pθ(由
θ
θ
θ参数化表示),以存储前缀参数。
h
i
=
{
P
θ
[
i
,
:
]
,
i
f
i
∈
P
i
d
x
,
L
M
ϕ
(
z
i
,
h
<
i
)
,
o
t
h
e
r
w
i
s
e
,
(3)
h_i=\begin{cases} P_{\theta}[i,:], & if~i\in \textbf P_{idx},\\ LM_{\phi}(z_i,h_{\lt i}), & otherwise, \end{cases}\tag{3}
hi={Pθ[i,:],LMϕ(zi,h<i),if i∈Pidx,otherwise,(3)
训练目标与等式(2)相同,但是可训练参数集合发生了变化:语言模型参数
ϕ
\phi
ϕ是固定的,而前缀参数
θ
θ
θ是唯一可训练参数。
4.3 Parametrization of Pθ
经验可知,直接更新 P θ P_{\theta} Pθ参数会导致训练不稳定,并且性能也略有下降。因此,我们通过用大型前馈神经网络( M L P θ MLP_θ MLPθ)组成的较小矩阵( P θ ′ P'_θ Pθ′)来重参数化矩阵 P θ [ i , : ] = M L P θ ( P θ ′ [ i , : ] ) P_θ[i,:]=MLP_θ(P'_θ[i,:]) Pθ[i,:]=MLPθ(Pθ′[i,:])。请注意, P θ P_θ Pθ和 P θ ′ P'_θ Pθ′具有相同的行(即前缀长度),但不同的列。一旦训练完成,可以删除这些重处理参数 P θ ′ P'_θ Pθ′和 M L P θ MLP_θ MLPθ,并且只需要保存前缀参数 P θ P_θ Pθ。

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









