






摘要
生成式大语言模型(LLM)的高计算和内存需求使得它们难以快速,且便宜地部署起来。本文介绍了SpecInfer,这是一种LLM服务系统,通过使用投机推理和token树验证来加速生成式LLM的推理。SpecInfer背后的一个关键思想是结合各种共同boost-tuned的小语言模型,以联合预测LLM的输出。预测是作为token树来组织,其每个节点都代表一个候选token序列。通过LLM使用一种新型的基于树的并行解码机制,验证了由token树表示的所有候选token序列的正确性。SpecInfer使用一个LLM作为token树验证器以代替增量解码器,这大大减少了用于服务的生成式LLM的端到端延迟和计算需求,同时可证明可以保留模型质量。
1.介绍
生成式大语言模型(LLM),例如ChatGPT和GPT-4,已经证明了在各种应用领域中创建自然语言文本的显着能力,这些领域包括摘要,指令遵循和问答。但是,由于它们包含大量参数,以及复杂的网络结构和高计算要求,因此快速,地服部署这些LLM是一个挑战。例如,GPT-3结构具有1750亿个参数,需要超过16个NVIDIA 40GB A100 GPU才能存储在单精度的浮点中,并花几秒钟才能提供单个推理请求。
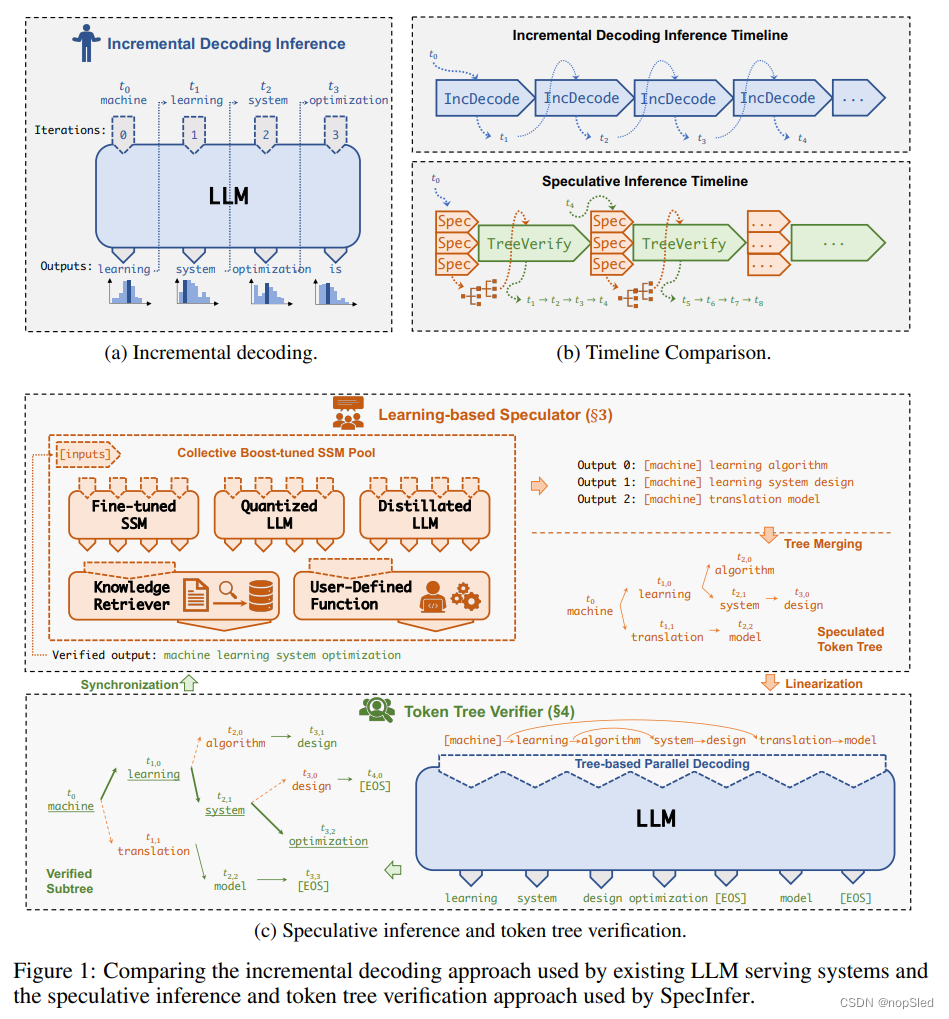
如图1a所示,生成式LLM通常将输入作为一个token序列,称为提示,并一次生成后续token。序列中每个token的生成是以输入提示和先前生成的token为条件,并且不考虑将来的token。该方法也称为自回归解码,因为每个生成的token也被用作未来token的输入。token之间的这种依赖性对于许多需要保留生成token顺序和上下文的NLP任务至关重要,例如文本补全。
现有的LLM系统通常使用增量解码方法来服务请求,其中系统在单个步骤中首先计算所有提示token的激活,然后使用输入提示和所有先前生成的token迭代解码一个新的token。这种方法遵守token间的数据依赖性,但是实现具有次优的运行时性能和有限的GPU利用率,因为每个请求中的并行程度在增量阶段受到极大限制。此外,Transformer的注意力机制需要访问所有先前token的key和value,以计算新token的注意力输出。为了避免重新计算所有上述token的key和value,现有的LLM服务系统使用缓存机制存储其key和value以在将来的迭代中重新使用。对于长序列生成任务(例如,GPT-4在请求中最多支持32Ktoken),缓存key和value引入了重要的内存开销,这阻止了现有系统由于内存的限制,因此无法同时提供大量请求的服务。
本文介绍了SpecInfer,这是一种LLM服务系统,通过使用投机推理和token树验证来提高生成式LLM在推理时的端到端延迟和计算效率。SpecInfer设计背后的一个关键思想是将LLM用作token树验证器而不是增量解码器。对于给定的token序列,SpecInfer使用一个基于学习的speculator,其结合了用户提供的函数(例如文档检索器)和多个共同boost-tuned的小型投机模型(SSM)来共同生成一棵token树,其每个节点都代表一个候选序列。然后,使用新的基于树的并行解码算法,对与LLM原始输出并列的由token树表示的所有token序列的正确性进行验证。只要投机token树与LLM的输出重叠,这种方法允许SpecInfer在单个解码步骤中验证多个token。
与增量解码相比,SpecInfer的投机推理和token树验证在生成和验证投机token树时引入了较小的计算和内存开销。但是,通过最大化可以在单个LLM解码步骤中成功验证的token数量,SpecInfer可以大大减少端到端推理延迟,并提高生成式LLM服务的计算效率。我们在两个LLM系列(即LLaMA和OPT)和五个提示数据集上评估了SpecInfer。我们的评估表明,SpecInfer可以将LLM解码步骤的数量减少4.4倍(平均3.7倍),并将端到端推理延迟降低了2.8倍。
2.Overview

Algorithm 2。SpecInfer使用的投机推理和token树验证算法。SPECULATE将当前token序列
S
\mathcal S
S作为输入,并生成投机token树
N
\mathcal N
N。SpecInfer对LLM的使用与现有系统不同:LLM将token树
N
\mathcal N
N作为输入,并为每个节点
u
∈
N
u∈\mathcal N
u∈N生成一个token
O
(
u
)
\mathcal O(u)
O(u)。请注意,TREEPARALLELDECODE函数可以在单个LLM解码步骤中生成
O
\mathcal O
O中的所有token(请参见第4节)。最后,VERIFY检查与LLM输出
O
\mathcal O
O对应的投机token树
N
\mathcal N
N,并产生一个经过验证的token序列
V
\mathcal V
V,该序列可以直接将其添加到当前token序列
S
\mathcal S
S。

图1C显示了我们方法的概述。SpecInfer包括一个基于学习的speculator,其以一个token序列作为输入,并产生一颗投机token树。speculator的目标是最大化投机token树和LLM使用增量解码生成的token序列间的重叠部分。如图1c的顶部所示,投机器结合了(1)用户提供的函数,这些函数可以根据启发式和/或检索增强的文档来预测未来token,以及(2)多个LLM的蒸馏和/或裁剪版本, 我们称为小型投机模型(SSM)。
有多种方法来准备SSM以进行投机推理。首先,现代LLM通常具有许多较小的结构,这些结构使用相同的数据集进行训练。例如,除了具有1750亿参数的OPT-175B模型外,OPT模型系列还包括OPT-125M和OPT-350M,这是两个分别具有1.25亿和3.5亿参数的变体,使用了与OPT-175B相同的数据集进行了预训练。这些预训练的小型模型可以直接用作SpecInfer中的SSM。其次,除了使用这些预训练的SSM之外,为了最大程度地提高投机token树的覆盖范围,SpecInfer还引入了一种新的微调技术,称为collective boost-tuning,使用adaptive boosting以联合微调一组SSM,以将LLM输出与他们的汇总预测保持对齐。
speculator会自动结合由单个SSM预测的候选token序列以构造一棵token树,如图1c所示。由于SpecInfer并行执行多个SSM,因此使用更多SSM不会直接增加投机推理的延迟。但是,使用大量SSM会导致一棵更大的token树,这需要更多的内存和计算资源才能进行验证。为了应对这一挑战,给定输入token序列,SpecInfer使用基于学习的投机调度器来学习确定使用哪些SSM以及SSM的投机配置(例如,当使用一个基于BeamSearch运行的SSM时,确定搜索宽度和深度 )。
与现有LLM推理系统的增量解码方法相比,SpecInfer的投机推理和token树验证提供了两个关键优势。
Reduced memory accesses to LLM parameters。生成式LLM推理的性能在很大程度上受GPU内存访问的限制。在现有增量解码方法中,生成单个token需要访问LLM的所有参数。对于基于offloading的LLM推理系统而言,问题更加严重了,该系统使用有限的计算资源(例如单个商品GPU),并通过利用CPU DRAM和持久存储来保存模型参数然后将这些参数动态加载到GPU的高带宽内存(HBM)来进行计算。与增量解码方法相比,只要投机token树和LLM的实际输出的重叠不是空的,SpecInfer就会显着降低对LLM参数的访问。减少对GPU设备内存的访问以及GPU和CPU存储器之间的数据传输,会减少能量的消耗,因为访问GPU HBM的能量消耗要比浮点算术操作多两到三个数量级。
Reduced end-to-end inference latency。LLM作为服务会面临较长的端到端的推理延迟。例如,GPT-3结构包括1750亿个参数,需要许多秒才能提供请求。在现有的增量解码方法中,用于生成每个token的计算取决于所有先前生成的token的key和value,这些key,value具有顺序依赖性,并且需要现代的LLM服务系统来为每个请求序列化不同生成的token。在SpecInfer中,LLMs用作验证器,其将投机token树作为输入,并同时检查token树中的所有token。这种方法可以在单个请求中对不同token进行并行化,并减少LLM的端到端推理延迟。
3.Speculative Inference
SpecInfer的主要部分是speculator的设计和实现。一方面,更准确的投机推理会得到具有更长匹配长度的投机token树,从而导致LLM验证步骤较少。另一方面,由于固有的表达方式,句子中的某些短语更容易推测,而其他句子则更具挑战性,采用固定的配置进行投机推理(例如,使用固定的BeamSearch宽度和深度)会导致次优的性能,由于一个很小的推测窗口可能会导致失去匹配更长token序列的机会,而大型推测窗口可能会产生不必要的token。
SpecInfer包括两种关键技术来应对这一挑战。首先,为了提高token树的投机性能,第3.1节介绍了共同boost-tuning技术,这是一种新的微调技术,可利用adaptive boosting将一组SSM的联合预测与LLM的输出保持对齐。其次,为了解决动态推测,第3.2节提出了基于学习的投机调度器,该调度器学会了为给定的输入token序列和一组SSM赊着最佳的投机配置。
3.1 Collective Boost-Tuning
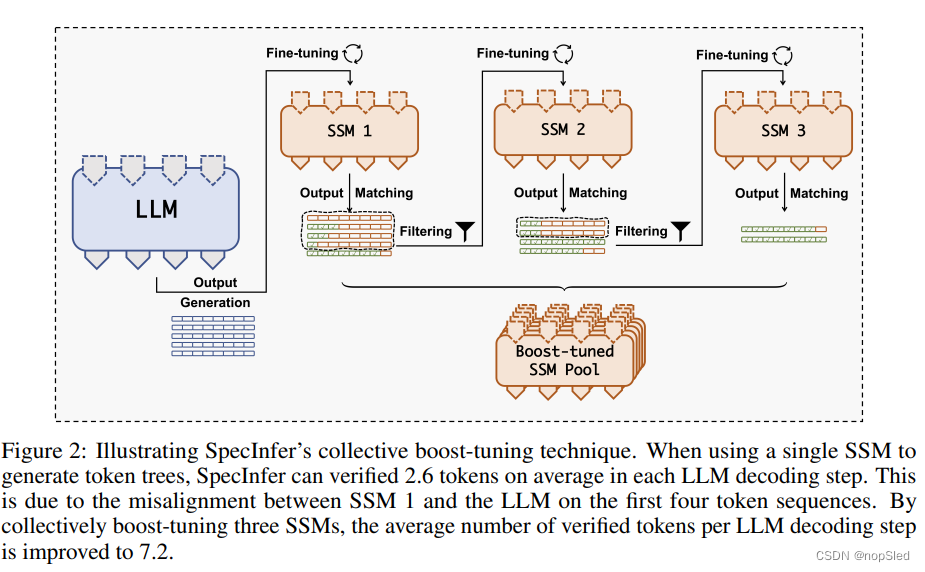
如先前的工作中所述,使用单个SSM进行投机推断的关键限制是,SSM和LLM之间的对齐差距是由两个模型之间的容量差距导致的。我们的初步探索表明,使用较大的SSM模型可实现更好的投机性能,但引入了额外的内存开销和推理延迟。
因此,SpecInfer使用无监督的方法来联合微调SSM池,通过利用自适应增强技术来使其输出与LLM的输出对齐,如图2所示。SpecInfer的SSM用于预测未来几个少数token,这些token由LLM生成,因此SpecInfer使用通用文本数据集(例如,我们的评估中的OpenWebText语料库)以一种完全无监督的方式将多个SSM的汇总输出与LLM自适应对齐。特别是,我们将文本语料库转换为提示样本的集合,并使用LLM为每个提示生成一个token序列。SpecInfer首先一次微调一个SSM,并标记与LLM具有完全相同子序列token所有提示样例。接下来,SpecInfer过滤所有被标记的提示样例,并使用语料库中所有剩余样本来充分微调下一个SSM。通过为池中的每个SSM重复此过程,Specinfer获得了一组多样化的SSM,它们的汇总输出在很大程度上与LLM在训练语料库上的输出重叠。与使用单个SSM相比,所有SSM都具有大致相同的推理延迟,因此在不同的GPU上运行所有SSM并不会增加投机推理的延迟。请注意,使用多个SSM会增加内存开销,以将其参数存储在GPU上。但是,我们的评估表明,SpecInfer可以使用比LLM小40-100倍的SSM来实现显着的性能提高,从而使耗费这些SSM的开销可忽略不计。在我们的评估中,我们在公开可用的数据集上进行离线联合 boost-tuning。
3.2 Learning-based Speculative Scheduler
为了发现一个最佳配置,可以在每个解码步骤启动多个SSM,我们设计了一个基于学习的投机调度器,该调度器学会基于给定的输入token序列确定使用哪些SSM和这些SSM的配置。
调度器包括一个匹配长度预测器和成本模型。匹配长度预测器将来自LLM最后一个隐藏层的最新特征表示作为输入,并输出具有连续数字的向量,向量的每个数字对应于在特定投机配置下的期望匹配长度。SpecInfer使用一个三层MLP作为匹配长度预测器的网络结构,并考虑了每个SSM的集束搜索的配置空间,其中beam宽度为
b
∈
[
1
,
2
,
4
]
b∈[1,2,4]
b∈[1,2,4],深度为
d
∈
[
1
,
2
,
4
,
8
,
16
]
d∈[1, 2,4,8,16]
d∈[1,2,4,8,16],因此,MLP输出15个数字的向量,每个数字代表一个投机配置的预测匹配长度。该预测器还以offload方式对公开数据集进行了训练。请注意,获得预测器的输入特征向量不涉及额外的成本,因为它在SpecInfer的验证器中具有独立的成本(请参见第4节)。
为了实现每单位时间的更高匹配长度,我们定义了以下成本函数:
c
o
s
t
(
b
,
d
∣
h
)
=
f
(
b
,
d
∣
h
)
L
v
e
r
i
f
y
(
b
,
d
)
+
L
s
p
e
c
u
l
a
t
e
(
b
,
d
)
,
(1)
cost(b,d|h)=\frac{f(b,d|h)}{L_{verify}(b,d)+L_{speculate}(b,d)},\tag{1}
cost(b,d∣h)=Lverify(b,d)+Lspeculate(b,d)f(b,d∣h),(1)
其中
b
b
b和
d
d
d是集束搜索宽度和深度,
h
h
h是预测器的输入特征向量,而
f
(
b
,
d
∣
h
)
f(b,d|h)
f(b,d∣h)是给定投机配置
(
b
,
d
)
(b,d)
(b,d)和当前上下文
h
h
h时的预测匹配长度 。
L
v
e
r
i
f
y
(
b
,
d
)
L_{verify}(b,d)
Lverify(b,d)和KaTeX parse error: Expected 'EOF', got '}' at position 19: …speculate}(b,d)}̲分别是验证器和投机器的估计推理延迟,这是通过对SpecInfer的运行时系统进行分析来衡量。使用等式(1)中定义的成本函数,SpecInfer选择了将每个SSM的预期成本最小化的配置:
(
b
,
d
)
=
a
r
g
m
a
x
(
b
,
d
)
c
o
s
t
(
b
,
d
∣
h
)
(2)
(b,d)=arg\mathop{max}\limits_{(b,d)}cost(b,d|h)\tag{2}
(b,d)=arg(b,d)maxcost(b,d∣h)(2)
4.Token Tree Verifier
本节介绍了SpecInfer的token树验证器,该验证器以由投机器生成的输入树作为输入,并验证其token序列与给定LLM的正确性。
Token tree。Specinfer使用一个token树来存储基于学习的投机器的生成结果。每个token树
N
\mathcal N
N是一个树结构,其中每个节点
u
∈
N
u∈\mathcal N
u∈N被标记为token
t
u
t_u
tu,
p
u
p_u
pu表示token树中
u
u
u的父节点。对于每个节点
u
u
u,
S
u
\mathcal S_u
Su表示通过拼接
S
p
u
\mathcal S_{p_u}
Spu和
{
t
u
}
\{t_u\}
{tu}得到的token序列。
SpecInfer接收由不同SSM生成的多个token序列,其中每个序列都可以视为一棵token树(线性树结构)。SpecInfer首先需要将这些token树合并为单个树结构。
Definition 4.1 (Tree Merge)。
M
\mathcal M
M是由
m
m
m个token树
{
N
i
}
(
1
≤
i
≤
m
)
\{\mathcal N_i\}(1≤i≤m)
{Ni}(1≤i≤m)合并后的树,当且仅当
∀
1
≤
i
≤
m
,
∀
u
∈
N
i
,
∃
v
∈
M
∀1≤i≤m,∀u∈\mathcal N_i,∃v∈\mathcal M
∀1≤i≤m,∀u∈Ni,∃v∈M,使得
S
v
=
S
u
\mathcal S_v =\mathcal S_u
Sv=Su,反之亦然。
直观地,每个token树表示一组token序列。合并多个token树会产生一棵新树,其中包括原始树的所有token序列。
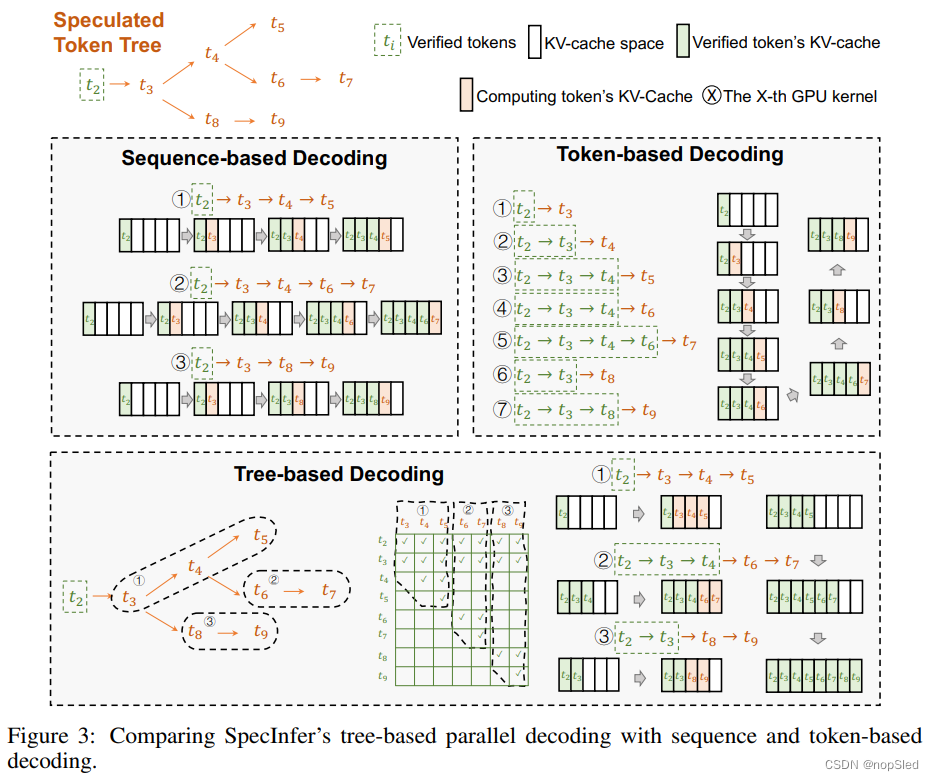
SpecInfer设计背后的一个关键思想是通过单个LLM结构来验证token树的所有序列。token树的验证允许SpecInfer解码多个token(而不是以增量解码方法解码单个token),从而减少对LLM参数的访问。在token树验证中SpecInfer必须解决的挑战是有效地计算token树所有序列的注意力分数。SpecInfer执行树注意力,这是一种快速且便宜的方法,通过为token树执行基于Transformer的注意力计算以及许多重要的系统级优化,以应对这一挑战。
第4.1节描述了树的注意力,第4.2节介绍了SpecInfer用来验证token树与LLM的输出对齐的机制,4.3节提出了SpecInfer的优化,以加速token树验证。
4.1 Tree Attention
4.2 Verification
4.3 Optimizations

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









