






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Vipra Singh
编译:ronghuaiyang
导读
LLM Serving指的是部署和运行大型语言模型(LLMs)以处理用户请求的过程。它涉及到将通常离线训练的LLM设置为实时响应查询。
LLM Serving指的是部署和运行大型语言模型(LLMs)以处理用户请求的过程。它涉及到将通常离线训练的LLM设置为实时响应查询。
以下是LLM Serving包含的主要方面:
高效处理:由于LLM计算成本高昂,会采用诸如将多个用户请求批量处理等服务技术,以优化资源利用并加快响应速度。
模型部署:将LLM模型部署在能够满足处理需求的服务器或云平台上。
API创建:创建应用程序编程接口(API),允许用户与LLM交互并发送他们的查询。
基础设施管理:服务系统必须具备可扩展性和可靠性,以应对大量用户并发访问,确保持续稳定运行。
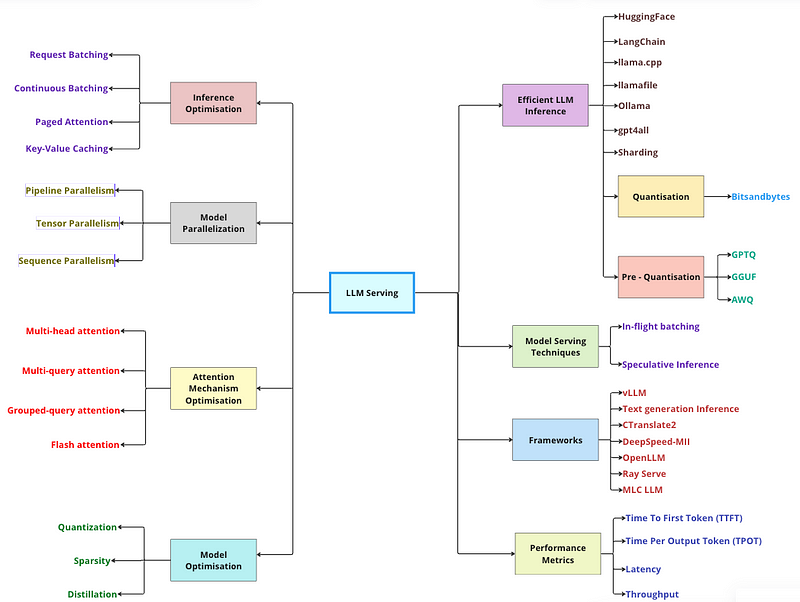
市面上存在多种用于LLM服务的框架,各有其独特优势。让我们详细探讨一下。
本地运行LLM
像PrivateGPT、llama.cpp、Ollama、GPT4All、llamafile等项目的流行,凸显了在本地设备上运行LLM的需求。
这样做至少有两大明显益处:
隐私性:数据不会传输至第三方,也不受商业服务条款的约束。成本:无需支付推理费用,这对那些依赖大量tokens的应用(如长期运行的模拟、摘要生成等)尤为重要。
要在本地运行LLM,需要满足以下条件:
开源LLM:一个可自由修改和共享的开源LLM。推理能力:能够在本地设备上运行此LLM,同时保持可接受的延迟。
开源LLM
用户现在可以接触到一套快速扩大的开源LLM集合。
这些LLM至少可以从两个维度进行评估(参见图表):
基础模型:基础模型是什么,它是如何训练的?微调方法:基础模型是否经过微调,如果微调过,使用了哪套指令集?
.assets/0JTle7ssXyuN_3z6T.png)
这些模型的相对性能可以通过多个排行榜来评估,包括:
LmSys
GPT4All
HuggingFace
一些框架已经出现,用于支持在不同设备上对开源LLM进行推理:
llama.cpp:用C++实现的llama推理代码,带有权重优化/量化功能。gpt4all:优化的C后端,用于推理。Ollama:将模型权重和环境打包成一个应用程序,在设备上运行并提供LLM服务。llamafile:将模型权重及运行模型所需的一切封装在一个文件中,使我们能够直接从该文件本地运行LLM,无需额外的安装步骤。
总的来说,这些框架通常会完成几项工作:
量化:减少原始模型权重的内存占用。高效的推理实现:支持在消费级硬件(如CPU或笔记本GPU)上进行推理。
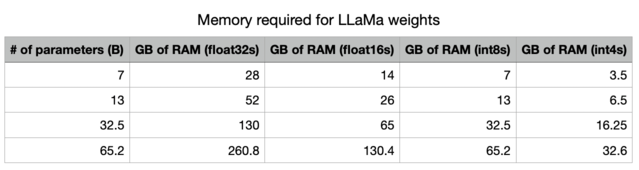
精度降低后,存储LLM所需的内存大幅度减少。
此外,我们还可以看到GPU内存带宽的重要性表格!
得益于更大的GPU内存带宽,Mac M2 Max在推理速度上比M1快5-6倍。
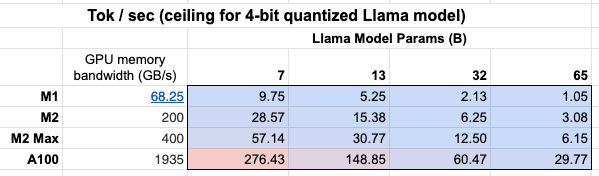
下面我们将详细讨论这些内容。
高效加载LLM
接下来,我们将探讨如何通过几种(量化)标准来加载本地的LLM。由于分片、量化以及不同的保存和压缩策略的存在,要弄清楚哪种方法适合我们并不容易。
在所有示例中,我们将使用Zephyr 7B,这是Mistral 7B的一个微调变体,采用直接偏好优化(DPO)训练而成。
🔥 小贴士:在加载LLM的每个示例之后,建议重启笔记本以避免出现内存溢出错误。加载多个LLM需要大量的RAM/VRAM。我们可以通过删除模型并重置缓存来释放内存,操作如下:
# Delete any models if previously created
del model, tokenizer, pipe
# Empty VRAM cache
import torch
torch.cuda.empty_cache()1. HuggingFace
加载LLM最直接、最基本的方式是通过 Transformers。HuggingFace开发了一整套强大的包,让我们能够用LLM做许多惊人的事情!
我们首先从主分支安装HuggingFace等包,以支持更新的模型:
# Latest HF transformers version for Mistral-like models
!pip install git+https://github.com/huggingface/transformers.git
!pip install accelerate bitsandbytes xformers安装完成后,我们可以使用以下的pipeline轻松加载LLM:
from torch import bfloat16
from transformers import pipeline
# Load in the LLM without any compression tricks
pipe = pipeline(
"text-generation",
model="HuggingFaceH4/zephyr-7b-beta",
torch_dtype=bfloat16,
device_map="auto"
)这种加载LLM的方法通常不会执行任何压缩技巧来节省VRAM或提高效率。
为了生成我们的提示信息,我们首先需要创建必要的模板。幸运的是,如果聊天模板保存在底层的分词器中,这可以自动完成:
# We use the tokenizer's chat template to format each message
# See https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot.",
},
{
"role": "user",
"content": "Tell me a funny joke about Large Language Models."
},
]
prompt = pipe.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)使用内置的提示模板生成的提示信息,构建方式如下:
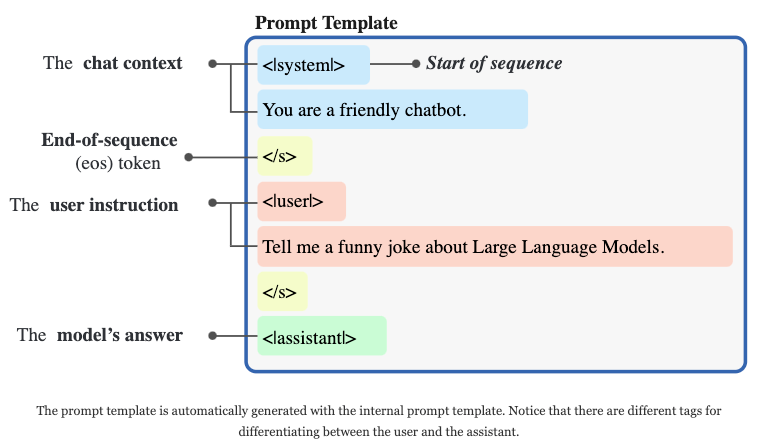
然后,我们可以开始将提示传递给LLM以生成答案:
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.1,
top_p=0.95
)
print(outputs[0]["generated_text"])这会给我们如下输出:
Why did the Large Language Model go to the party?
To network and expand its vocabulary!
这个笑点或许有点俗套,但LLM正是通过不断扩充词汇和与其他模型交流来提升其语言技能的。所以,这个笑话对于它们来说恰到好处!
在纯粹的推理场景下,这种方法通常效率最低,因为我们加载整个模型时没有采取任何压缩或量化策略。
然而,作为起步方法,它非常出色,因为它让模型的加载和使用变得极为便捷!
2. LangChain
另一种在本地运行LLM的方式是使用LangChain。LangChain是一个用于构建AI应用的Python框架。它提供了抽象层和中间件,让你能够基于其支持的模型之一来开发AI应用。例如,下面的代码向microsoft/DialoGPT-medium模型提出一个问题:
from langchain.llms.huggingface_pipeline import HuggingFacePipeline
hf = HuggingFacePipeline.from_model_id(
model_id="microsoft/DialoGPT-medium", task="text-generation", pipeline_kwargs={"max_new_tokens": 200, "pad_token_id": 50256},
)
from langchain.prompts import PromptTemplate
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate.from_template(template)
chain = prompt | hf
question = "What is electroencephalography?"
print(chain.invoke({"question": question}))LangChain的优点:
模型管理更为简便
提供了有助于AI应用开发的实用工具
LangChain的缺点:
速度有限,与Transformers相同
你仍然需要编写应用的逻辑或创建合适的用户界面
3. Llama.cpp
Llama.cpp是一个基于C和C++的LLM推理引擎,针对苹果芯片进行了优化,并运行Meta的Llama2模型。
克隆仓库并构建项目后,我们可以用以下命令运行一个模型:
$ ./main -m /path/to/model-file.gguf -p "Hi there!"Llama.cpp的优点:
性能高于基于Python的解决方案
即使是在配置较为普通的硬件上,也能支持像Llama 7B这样的大型模型
提供了绑定功能,可以在其他语言中构建AI应用,同时通过Llama.cpp运行推理。
Llama.cpp的缺点:
支持的模型有限
需要自行构建工具
4. Llamafile
由Mozilla开发的Llamafile为运行LLM提供了用户友好的替代方案。Llamafile以其便携性和能够创建单文件可执行程序而著称。
下载Llamafile和任何GGUF格式的模型后,我们可以通过以下命令启动本地浏览器会话
$ ./llamafile -m /path/to/model.ggufLlamafile的优点:
与Llama.cpp一样,享有速度上的优势
可以构建一个包含了嵌入式模型的单一可执行文件
Llamafile的缺点:
项目尚处于早期阶段
并非所有模型都受支持,仅限于Llama.cpp所支持的模型。
5. Ollama
Ollama是Llama.cpp和Llamafile的更加用户友好的替代品。你下载一个可执行文件,它会在你的机器上安装一项服务。安装完毕后,你打开终端并运行:
1$ ollama run llama2Ollama会下载模型并开始一个交互式会话。
Ollama的优点:
安装和使用简便。
可以运行llama和vicuña模型。
运行速度极快。
Ollama的缺点:
提供的模型库有限。
自行管理模型,你无法复用你自己的模型。
运行LLM时没有可调节的选项。
尚无Windows版本(目前)。
6. GPT4ALL
GPT4ALL是一个易于使用的桌面应用,拥有直观的图形用户界面。它支持本地模型运行,并提供通过API密钥连接OpenAI的功能。它的一大亮点在于能够处理本地文档以提供上下文,确保了隐私性。

优点:
具有精良的UI,易于使用
支持一系列精选模型
缺点:
模型选择有限
部分模型存在商业使用限制
7. 分片
在深入探讨量化策略之前,还有一个技巧我们可以用来减少加载模型所需的VRAM。通过分片,我们实际上是将模型分割成较小的部分,即碎片。
每个碎片包含模型的一部分,通过在不同设备之间分配模型权重,旨在绕过GPU内存限制。
还记得我之前说我们没有进行任何压缩技巧吗?
那不是完全正确……
我们加载的模型,Zephyr-7B-β,实际上已经被分片了!如果我们前往模型页面并点击“文件和版本”链接,我们会发现模型已经被分割成了八块。
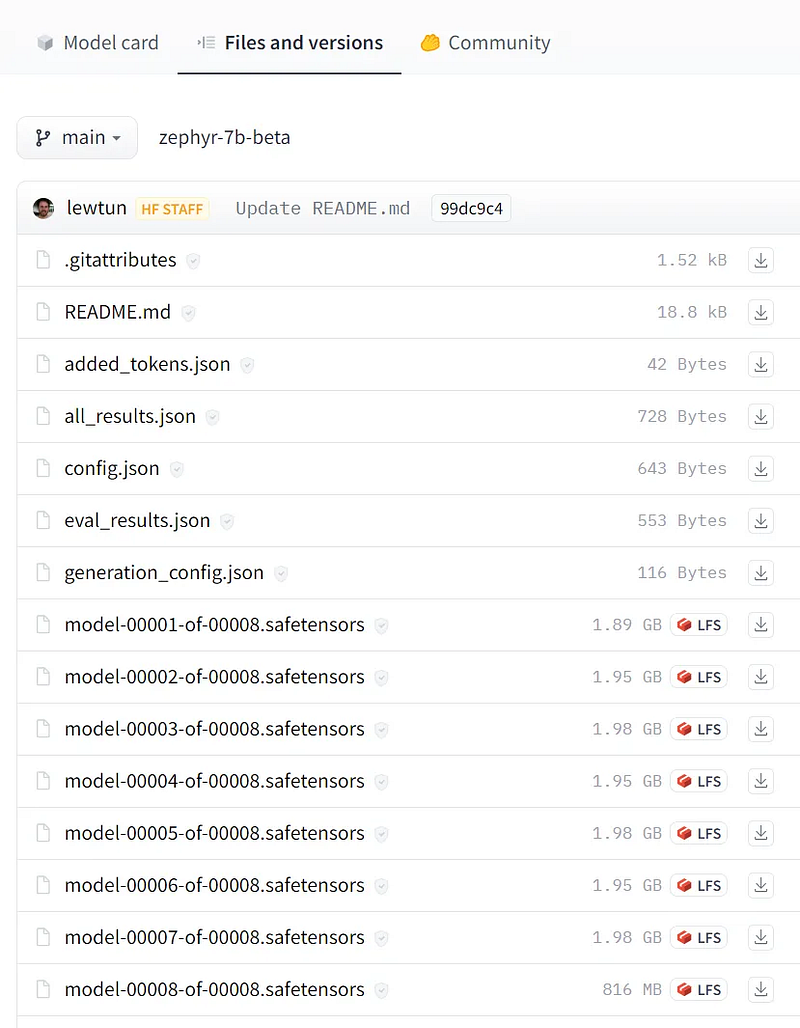
虽然我们可以自己对模型进行分片,但通常建议寻找已经量化的模型,或者自己进行量化。
使用Accelerate包进行分片是非常直接的:
from accelerate import Accelerator
# Shard our model into pieces of 1GB
accelerator = Accelerator()
accelerator.save_model(
model=pipe.model,
save_directory="/content/model",
max_shard_size="4GB"
)就这样!因为我们把模型分片成4GB而不是2GB的大小,所以我们创建了更少的加载文件:

8. 使用Bitsandbytes进行量化
LLM由一系列权重和激活值构成。这些值通常以常见的32位浮点数(float32)数据类型表示。
位数的多少决定了它可以表示的数值范围。Float32能够表示介于1.18e-38和3.4e38之间的数值,这是一个相当广泛的范围!位数越少,所能表示的数值就越有限。
正如我们所预期的那样,如果我们选择更低的位数,那么模型的精确度会下降,但它需要表示的数值也会减少,从而降低了模型的大小和内存需求。
量化是指将LLM从原来的Float32表示形式转换为更小的数据类型。然而,我们并不只是想要使用更小的位数变体,而是希望将大位数的表示映射到小位数而不丢失太多信息。
实践中,我们经常看到使用一种名为4位正则浮点(NF4)的新格式来实现这一点。这种数据类型通过几个特殊技巧高效地表示更大位数的数据类型。它包括三个步骤:
归一化:模型的权重被归一化,以便我们期望权重落在某个范围内。这允许更有效地表示更常见的值。
量化:权重被量化为4位。在NF4中,量化级别相对于归一化的权重均匀间隔,从而有效地表示原始的32位权重。
反量化:尽管权重以4位存储,但在计算期间会进行反量化,这在推理过程中提供了性能提升。
要使用HuggingFace执行此量化,我们需要使用Bitsandbytes定义量化配置:
from transformers import BitsAndBytesConfig
from torch import bfloat16
# Our 4-bit configuration to load the LLM with less GPU memory
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit quantization
bnb_4bit_quant_type='nf4', # Normalized float 4
bnb_4bit_use_double_quant=True, # Second quantization after the first
bnb_4bit_compute_dtype=bfloat16 # Computation type
)此配置使我们能够指定要采用的量化级别。通常,我们希望使用4位量化来表示权重,但在16位下进行推理。
在pipeline中加载模型就变得很简单:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# Zephyr with BitsAndBytes Configuration
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
model = AutoModelForCausalLM.from_pretrained(
"HuggingFaceH4/zephyr-7b-alpha",
quantization_config=bnb_config,
device_map='auto',
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')接下来,我们可以使用与之前相同的提示:
# We will use the same prompt as we did originally
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.95
)
print(outputs[0]["generated_text"])这将给我们以下输出:
Why did the Large Language Model go to the party?
量化是一种强大技术,能够在保持相似性能的同时减少模型的内存需求。它使得即使在较小的GPU上也能更快地加载、使用和微调LLM。
9. 预量化(GPTQ vs. AWQ vs. GGUF)
到目前为止,我们已经探讨了分片和量化技术。尽管这些是值得掌握的有用技巧,但每次加载模型时都必须应用它们似乎有些浪费。
相反,这些模型往往已经被提前为我们分片和量化。特别是HuggingFace上的用户TheBloke,为我们执行了一系列的量化工作,可供我们使用。
撰写本文时,他已经上传了超过2000个量化的模型供我们使用!
这些量化的模型形态各异、大小不一。其中最常用的格式是GPTQ、GGUF和AWQ,主要用于进行4位量化。
GPTQ:针对GPT模型的后训练量化
GPTQ是一种针对4位量化设计的后训练量化(PTQ)方法,主要关注GPU推理和性能。
该方法的核心思想是尝试通过最小化权重的均方误差将其压缩至4位量化。在推理过程中,它会动态地将权重反量化至float16,以提高性能同时保持较低的内存占用。
首先,我们需要安装一些必要的包,以便在HuggingFace Transformers中加载类似GPTQ的模型:
pip install optimum
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/完成上述步骤后,我们可以导航到想要加载的模型,即TheBloke/zephyr-7B-beta-GPTQ,并选择一个特定的版本。
这些版本基本上指示了量化方法、压缩程度、模型大小等信息。
目前,我们坚持使用“main”分支,因为它通常在压缩和准确性之间取得了不错的平衡:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# Load LLM and Tokenizer
model_id = "TheBloke/zephyr-7B-beta-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
trust_remote_code=False,
revision="main"
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')尽管我们安装了一些额外的依赖项,但我们仍然可以使用之前相同的pipeline,这是使用GPTQ的一大好处。
加载模型后,我们可以如下运行一个提示:
# We will use the same prompt as we did originally
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.1,
top_p=0.95
)
print(outputs[0]["generated_text"])这给我们带来了以下生成的文本:
Why did the Large Language Model go to the party?
To show off its wit and charm, of course!
But unfortunately, it got lost in the crowd and couldn’t find its way back to its owner. The partygoers were impressed by its ability to blend in so seamlessly with the crowd, but the Large Language Model was just confused and wanted to go home. In the end, it was found by a group of humans who recognized its unique style and brought it back to its rightful place. From then on, the Large Language Model made sure to wear a name tag at all parties, just to be safe.
GPTQ是最常用的压缩方法,因为它针对GPU使用进行了优化。从GPTQ开始,如果GPU无法处理如此大的模型,再转向专注于CPU的方法,比如GGUF,是值得的。
GGUF:GPT生成统一格式
尽管GPTQ在压缩方面做得很好,但如果我们的硬件受限,其对GPU的关注可能成为一个劣势。
GGUF,前身为GGML,是一种量化方法,允许用户使用CPU运行LLM,同时也可将某些层卸载到GPU上以加速。
尽管使用CPU进行推理通常比使用GPU慢,但对于在CPU或苹果设备上运行模型的人来说,这是一种令人惊叹的格式。特别是随着更小、更强大的模型如Mistral 7B的出现,GGUF格式可能会持续存在!
使用GGUF相对直接,首先需要安装ctransformers包:
1pip install ctransformers[cuda]完成安装后,我们可以导航到想要加载的模型,即TheBloke/zephyr-7B-beta-GGUF,并选择一个特定的文件。
就像GPTQ一样,这些文件标明了量化方法、压缩水平、模型大小等信息。
我们使用“zephyr-7b-beta.Q4_K_M.gguf”,因为我们专注于4位量化:
from ctransformers import AutoModelForCausalLM
from transformers import AutoTokenizer, pipeline
# Load LLM and Tokenizer
# Use `gpu_layers` to specify how many layers will be offloaded to the GPU.
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/zephyr-7B-beta-GGUF",
model_file="zephyr-7b-beta.Q4_K_M.gguf",
model_type="mistral", gpu_layers=50, hf=True
)
tokenizer = AutoTokenizer.from_pretrained(
"HuggingFaceH4/zephyr-7b-beta", use_fast=True
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')加载模型后,我们可以如下运行一个提示:
# We will use the same prompt as we did originally
outputs = pipe(prompt, max_new_tokens=256)
print(outputs[0]["generated_text"])这将给我们以下输出:
Why did the Large Language Model go to the party? To impress everyone with its vocabulary! But unfortunately, it kept repeating the same jokes over and over again, making everyone groan and roll their eyes. The partygoers soon realized that the Large Language Model was more of a party pooper than a party animal. Moral of the story: Just because a Large Language Model can generate a lot of words, doesn’t mean it knows how to be funny or entertaining. Sometimes, less is more!
如果你在GPU资源紧张的情况下,想要同时利用CPU和GPU,GGUF是一个出色的选择,尤其在没有最新高性能GPU的情况下。
AWQ:激活感知权重量化
近期出现的一个新格式是AWQ(激活感知权重量化),这是一种类似于GPTQ的量化方法。AWQ和GPTQ作为方法之间有几个区别,但最重要的一点是AWQ认为并非所有的权重对于LLM的性能同等重要。
换句话说,在量化过程中会跳过一小部分权重,这有助于减少量化带来的损失。
因此,他们的论文提到相比GPTQ有着显著的速度提升,同时保持了类似的,有时甚至是更好的性能。
该方法仍相对较新,尚未像GPTQ和GGUF那样广泛采用,因此有趣的是看这些方法是否能够共存。
对于AWQ,我们将使用vLLM包,因为在我的经验中,这是使用AWQ阻力最小的途径:
pip install vllm使用vLLM,加载和使用我们的模型变得毫无痛苦:
from vllm import LLM, SamplingParams
# Load the LLM
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=256)
llm = LLM(
model="TheBloke/zephyr-7B-beta-AWQ",
quantization='awq',
dtype='half',
gpu_memory_utilization=.95,
max_model_len=4096
)然后,我们可以使用.generate轻松运行模型:
# Generate output based on the input prompt and sampling parameters
output = llm.generate(prompt, sampling_params)
print(output[0].outputs[0].text)给我们的输出:
Why did the Large Language Model go to the party? To network and expand its vocabulary! Why did the Large Language Model blush? Because it overheard another model saying it was a little too wordy! Why did the Large Language Model get kicked out of the library? It was being too loud and kept interrupting other models’ conversations with its endless chatter! …
尽管它是一种新格式,AWQ因其速度和压缩质量而迅速获得人气!
推理优化
堆叠transformer层以构建大规模模型能够带来更高的准确性、在少样本学习能力,甚至在广泛的语言任务上展现出接近人类的新兴能力。这些基础模型训练成本高昂,在推理过程中(一项持续发生的费用)也极其耗费内存和计算资源。当今最流行的大型语言模型(LLMs)参数规模可达数十亿乃至数百亿,具体取决于应用场景,可能需要处理长输入(或上下文),这同样会增加开销。例如,增强检索生成(RAG)管道需要向模型输入大量信息,这大大增加了LLM所需处理的工作量。
本文讨论了LLM推理中最紧迫的挑战,以及一些实用的解决方案。读者应该对Transformer架构和一般的注意力机制有基本了解。理解LLM推理的复杂性至关重要,我们将在下一节中对此进行探讨。
理解LLM推理
大多数流行的仅解码器型LLM(如GPT-3)都是在因果建模目标上进行预训练的,本质上是下一个词预测器。这些LLM接受一系列的token作为输入,自回归地生成后续的token,直到满足停止准则(例如,生成token的数量上限或停止词列表)或生成一个特殊的<end>标记,表示生成的结束。这个过程包含两个阶段:预填充阶段和解码阶段。
请注意,token是模型处理的语言的基本组成部分。一个token大约相当于四个英文字符。所有自然语言输入在输入模型之前都会转换成token。
预填充阶段或处理输入
在预填充阶段,LLM处理输入token以计算中间状态(键和值),这些状态用于生成第一个新的token。每个新的token都依赖于所有前面的token,但由于整个输入的范围是已知的,从高层次上看,这是一个高度并行化的矩阵-矩阵运算。它有效地使GPU利用率饱和。
解码阶段或生成输出
在解码阶段,LLM一次生成一个输出token,直到满足停止准则为止。每个连续的输出token都需要知道所有前一迭代的输出状态(键和值)。这类似于矩阵-向量运算,相比于预填充阶段,它对GPU计算能力的利用不足。数据(权重、键、值、激活)从内存传输到GPU的速度主导了延迟,而不是计算实际发生的速度。换句话说,这是一个受内存限制的操作。
本文中提到的许多推理挑战及其相应的解决方案都集中在优化这个解码阶段:高效的注意力模块、有效管理key和value等。
不同的LLM可能使用不同的分词器,因此,比较它们之间的输出token可能并不直接。在比较推理吞吐量时,即使两个LLM每秒输出的token数相似,如果它们使用不同的分词器,也可能不等价。这是因为对应的token可能代表不同数量的字符。
请求批处理
LLM服务的一个重要方面是批处理用户请求。与其为每个新请求重新加载参数,一种高效的方法是一次将参数加载到GPU上,并尽可能一次性处理尽可能多的输入序列。这种方法不仅能提高服务器吞吐量和优化计算资源利用,还能显著提高成本效益。但是,采取简单的策略,如等待固定数量的用户请求累积后再处理批次,会带来挑战。这意味着在批次内,每个请求生成序列结束标记的时间各不相同。因此,批次计算速度受最长生成时间的限制,导致用户不希望的等待时间(延迟)。序列间完成时间的差异会导致GPU利用率下降,削弱了批处理预期带来的效率提升。
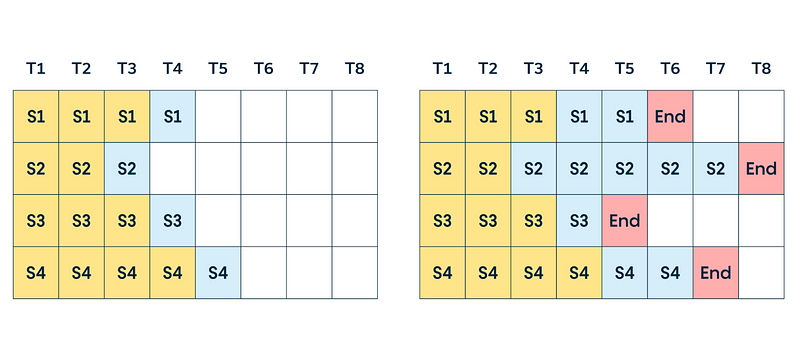
由于我们所讨论的所有挑战,连续批处理被提出以解决这些问题。
连续批处理
连续批处理是一种专门为LLM设计的批调度类型。与动态批处理相比,后者根据配置的时间阈值和最大批大小动态确定批大小,而连续批处理则允许新请求在下一个解码周期加入当前批次,而不是等待当前批次结束。由于LLM的自回归生成过程,这种方法对LLM来说易于实施,并且极大地提高了模型的吞吐量。
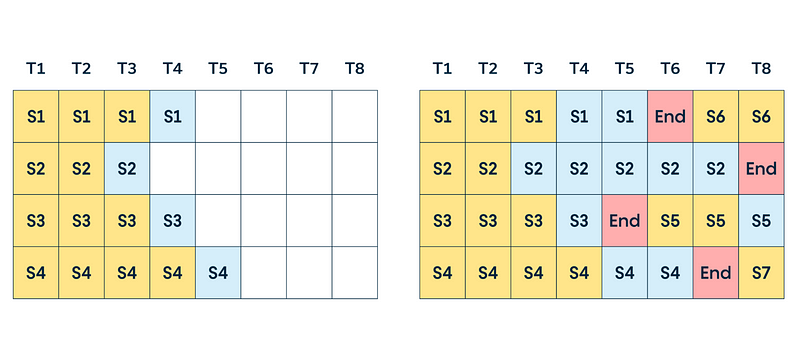
连续批处理在动态批处理请求方面表现出色。然而,我们还面临着另一个问题:内存限制。设想一下聊天机器人的情景——一个用户可能只用一句话提问,而另一个用户可能向我们的应用发送一段长篇大论——我们无法预知输入(和输出)序列的长度。这种不确定性引出了内存消耗的关键问题。在不知道序列确切的内存需求情况下,人们被迫采取最坏情况的假设,为整个批次预留尽可能多的内存。
问题在于:GPU的内存是有限的,需要空间用于
模型参数
用户请求计算(KV缓存)
整个批次的计算。
如果不进行优化,这些会占用大量空间,迫使我们缩小批处理大小,不幸的是,这也降低了吞吐量。但我们追求高吞吐量。我们如何优化这一点?关键是内存。
让我们从内存的角度更深入地了解一下解码过程中发生了什么。LLM的生成过程始于处理输入序列,并以自回归的方式逐个生成下一个token(见下图)。这个生成过程包括自注意力计算,需要计算迄今为止处理过的每个token的所有键值(KV)得分。举例来说,为了生成第t个token,我们需要从第t-1,t-2,...,1个token计算出的键和值。

为了优化重复计算,引入了KV缓存的概念。该方法旨在存储解码器中先前计算的K和V张量,随后在后续迭代中重用它们。然而,这种优化策略是以增加内存空间为代价的,当为了提高吞吐量而增大批处理大小时,这一点尤为关键。由于序列长度的不可预测性,传统注意力机制导致了显著的内存浪费,范围从60%到80%,这是由于碎片化和过度分配造成的。
PagedAttention:以内存为中心的解决方案
为了解决这一挑战,提出了PagedAttention。借鉴传统操作系统(OS)管理内存碎片和共享的策略,PagedAttention采用了带有分页的虚拟内存方法。它允许键和值向量存储在非连续的内存空间中。这使得键和值向量可以驻留在非连续的内存空间中,被组织成块。每个块容纳固定数量token的注意力键和值。在执行计算时,PagedAttention内核能够高效地识别和获取这些块。
键值缓存
解码阶段的一个常见优化是KV缓存。解码阶段每次生成一个token,但每个token都依赖于所有先前token的键和值张量(包括预填充时计算的输入token的KV张量,以及直到当前时间步长计算出的所有新KV张量)。
为了避免在每个时间步骤重新计算所有这些张量,可以在GPU内存中缓存它们。每次迭代,当计算出新元素时,它们会被简单地添加到正在运行的缓存中,供下一次迭代使用。在某些实现中,模型的每一层都有一个KV缓存。
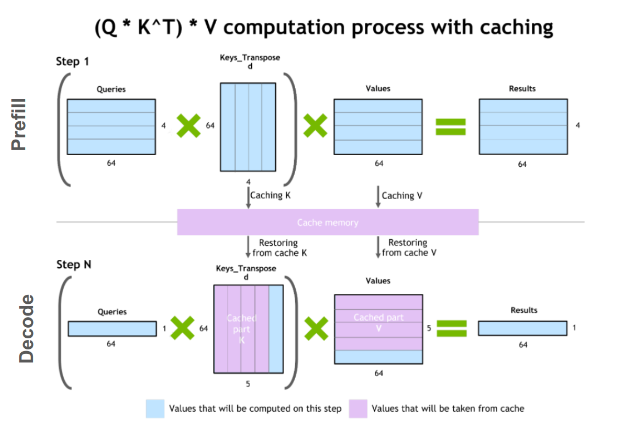
LLM内存需求
实际上,GPU上LLM的主要内存需求来源于模型权重和KV缓存。
模型权重:模型参数占据了内存空间。以一个拥有70亿参数的模型为例(例如Llama 2 7),以16位精度(FP16或BF16)加载,大约会占用7B * sizeof(FP16) ≈ 14GB的内存。
KV缓存:内存被用于缓存自注意力张量,以避免冗余计算。
在批处理中,批中每个请求的KV缓存仍然需要单独分配,可能会占用大量内存。下面的公式概述了适用于当今大多数常见LLM架构的KV缓存大小。
每个token的KV缓存大小(字节)= 2 * (层数) * (头数 * 头维度) * 精度大小(字节)
第一个因子2是考虑到K和V矩阵。通常,(头数 * 头维度)的值与变换器的隐藏尺寸(或模型维度,d_model)相同。这些模型属性通常可以在模型卡片或相关配置文件中找到。
此内存大小对于输入序列中的每个token都是必需的,贯穿整个输入批次。假设半精度,KV缓存的总大小由以下公式给出。
KV缓存总大小(字节)= (批大小) * (序列长度) * 2 * (层数) * (隐藏尺寸) * sizeof(FP16)
例如,使用16位精度的Llama 2 7B模型和批大小为1,KV缓存的大小将是1 * 4096 * 2 * 32 * 4096 * 2字节,大约等于2GB。
高效管理这个KV缓存是一项艰巨的任务。随着批大小和序列长度线性增长,内存需求可以迅速扩大。因此,它限制了可提供的吞吐量,并对长上下文输入带来了挑战。这就是本篇文章中提到的多种优化措施的动机所在。
通过模型并行化扩展LLM
减少模型权重在单个设备上的内存占用的一种方法是将模型分布在多个GPU上。分散内存和计算占用使得运行更大模型或更大批次的输入成为可能。模型并行化对于处理需要比单一设备可用内存更多的模型进行训练或推理是必要的,同时使训练时间和推理指标(延迟或吞吐量)适合特定的应用场景。根据模型权重的拆分方式,有几种并行化模型的方法。
值得注意的是,数据并行性也是一种经常与下面列出的其他方法一起提及的技术。在这种情况下,模型的权重被复制到多个设备上,全局输入批大小在每个设备上被划分为微批次。它通过处理更大的批次来减少总体执行时间。然而,这是一种训练时间优化,在推理期间的相关性较低。
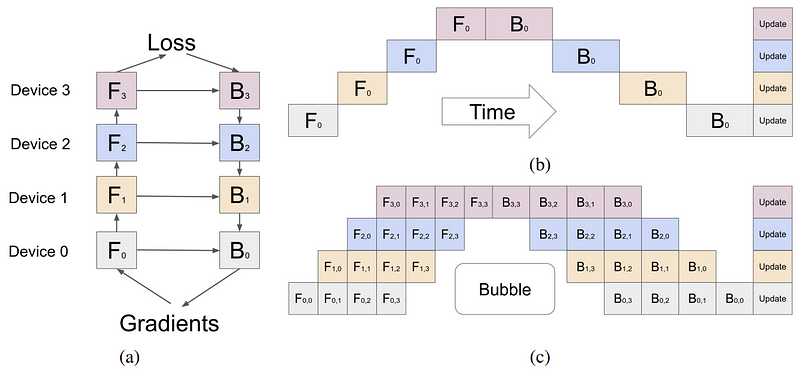
管道并行性
管道并行性涉及将模型(垂直地)分成片段,其中每个片段包含在单独设备上执行的一组层。图2a展示了四路管道并行性,其中模型被顺序分割,所有层的四分之一子集在每个设备上执行。一组操作在一个设备上的输出被传递给下一个设备,继续执行后续的片段。Fn & Bn分别表示设备n上的前向和后向传递。存储模型权重所需内存在每个设备上被有效四分之一。
这种方法的主要限制是,由于处理的顺序性质,一些设备或层在等待前一层的输出(激活、梯度)时可能保持空闲。这在前向和后向传递中都导致了效率低下或“管道气泡”。在图2b中,空白的空旷区域是大的管道气泡,设备处于空闲和未充分利用状态。
微批处理可以在一定程度上缓解这个问题,如图2c所示。全局输入批大小被分成子批,依次处理,最后累积梯度。请注意,Fn,m & Bn,m分别表示设备n上的微批m的前向和后向传递。
这种方法缩小了管道气泡的大小,但它并没有完全消除它们。
张量并行性
张量并行性涉及将模型的各个层(水平地)分割成更小、独立的计算块,这些块可以在不同的设备上执行。注意力块和多层感知机(MLP)层是Transformer的主要组件,可以利用张量并行性。在多头注意力块中,每个头或头的组可以被分配到不同的设备上,以便它们可以独立并行地计算。
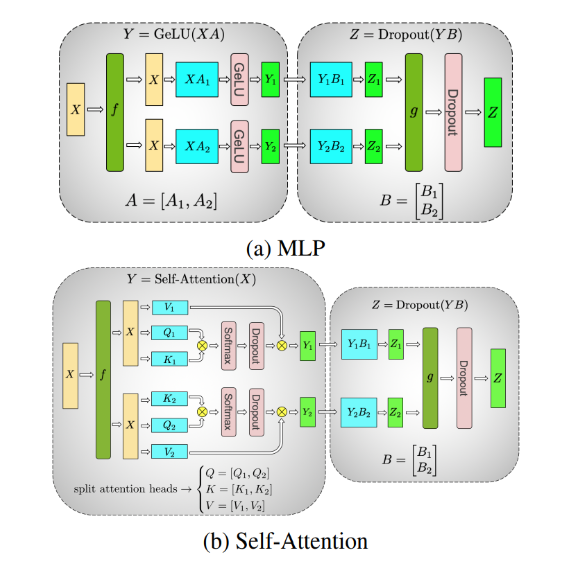
上图a展示了一个两路张量并行的例子,应用于两层MLP上,每一层用一个圆角框表示。在第一层中,权重矩阵A被分割成A1和A2。计算XA1和XA2可以在同一批次(f是一个恒等操作)的输入X上,在两个不同的设备上独立执行。这有效地将每个设备上存储权重的内存需求减半。一个约简操作g在第二层中组合输出。
上图b是一个在自注意力层中两路张量并行的例子。多个注意力头本质上是并行的,可以在设备之间分割。
序列并行性
张量并行性有其局限性,因为它要求层被分割成独立、可管理的块。它不适用于像LayerNorm和Dropout这样的操作,这些操作反而在整个张量并行组中复制。尽管LayerNorm和Dropout计算成本低廉,但它们确实需要相当多的内存来存储(冗余的)激活值。
如在大型Transformer模型中减少激活重计算中所示,这些操作在输入序列上是独立的,这些操作可以沿着所谓的“序列维度”进行分割,使其更加内存高效。这被称为序列并行性。
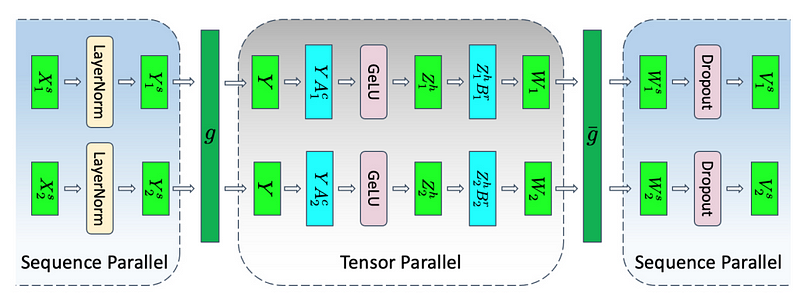
模型并行性的技术并非相互排斥,可以结合使用。它们有助于扩大规模并降低LLM在每个GPU上的内存占用,但也存在专门针对注意力模块的优化技术。
优化注意力机制
缩放点积注意力(SDPA)运算将查询和键值对映射到输出。
多头注意力
作为SDPA的增强,通过不同的、学习得到的Q、K和V矩阵投影,并行执行多次注意力层,使模型能够在不同位置同时关注来自不同表示子空间的信息。这些子空间独立学习,为模型提供了对输入中不同位置更丰富的理解。
如下图所示,多个并行注意力操作的输出被串联起来,并通过线性投影进行组合。每个并行注意力层称为一个‘头’,这种方法被称为多头注意力(MHA)。
在原始工作中,每个注意力头都在模型的降维版本上操作(例如)
当使用八个并行注意力头时。这样保持了计算成本与单头注意力相似。
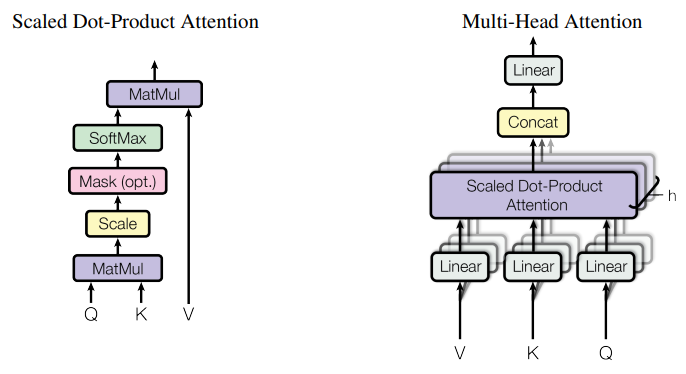
多查询注意力
多头注意力(MHA)的一种推理优化,被称为多查询注意力(MQA),如快速Transformer解码中提出的,它在多个注意力头之间共享键和值。查询向量仍然像以前一样被多次投影。
虽然MQA中完成的计算量与MHA相同,但从内存中读取的数据量(键、值)只是之前的一部分。当受到内存带宽限制时,这使得计算利用率更高。它还减少了内存中KV缓存的大小,为更大的批处理大小腾出了空间。
键值头的减少伴随着潜在的准确性下降。此外,需要在推理时利用这种优化的模型需要在启用MQA的情况下进行训练(或至少微调大约5%的训练量)。
分组查询注意力
分组查询注意力(GQA)通过将键和值投影到少量的查询头组中(下图),在MHA和MQA之间找到了平衡。在每组内部,它表现得像是多查询注意力。
下图显示,多头注意力有多个键值头(左)。分组查询注意力(中心)的键值头数量多于一个,但少于查询头的数量,这是在内存需求和模型质量之间的平衡。多查询注意力(右)有一个键值头,以帮助节省内存。
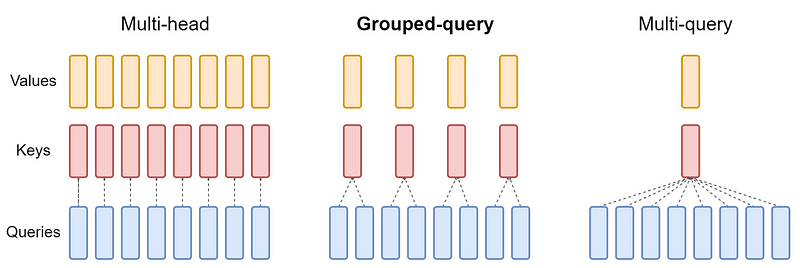
最初使用MHA训练的模型,可以使用GQA进行“升级训练”,只需要一小部分原始训练计算。它们在保持接近MQA的计算效率的同时,达到了接近MHA的质量。Llama 2 70B 就是一个利用GQA的模型示例。
像MQA和GQA这样的优化通过减少存储的键和值头的数量,帮助减少了KV缓存所需的内存。然而,KV缓存的管理方式可能仍然存在效率问题。与优化注意力模块本身不同,下一节介绍了一种更高效的KV缓存管理技术。
Flash attention
优化注意力机制的另一种方法是修改某些计算的顺序,以更好地利用GPU的内存层次结构。神经网络通常用层来描述,大多数实现也是按照这种方式布局的,每次只对输入数据执行一种类型的计算。这并不总是带来最优性能,因为对已经进入内存层次结构中更高、更高效级别的值进行更多计算可能是有益的。
在实际计算中融合多层可以最小化GPU需要从其内存读取和写入的次数,并将需要相同数据的计算组合在一起,即使它们属于神经网络中不同层的部分。
一个非常流行的融合是Flash Attention,这是一个I/O感知的精确注意力算法,详细情况见于FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。精确注意力意味着它在数学上与标准多头注意力(有适用于多查询和分组查询注意力的变体)完全相同,因此可以无修改地替换到现有模型架构中,甚至是已经训练好的模型中。
I/O感知意味着它在融合操作时考虑了一些之前讨论过的内存移动成本。具体来说,Flash Attention使用“分块”一次性完全计算和写出最终矩阵的小部分,而不是分步对整个矩阵进行部分计算,中间写出中间值。
下图展示了40GB GPU上的分块Flash Attention计算模式和内存层次结构。右侧的图表显示了通过融合和重新排序注意力机制的不同组成部分所带来的相对加速效果。
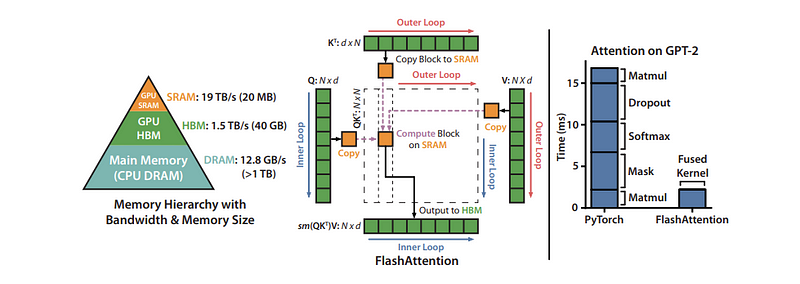
通过分页高效管理KV缓存
有时,为了应对最大可能的输入(即支持的序列长度),KV缓存会静态地“过度预分配”,因为输入的大小是不可预测的。例如,如果模型支持的最大序列长度是2,048,那么无论请求中的输入和产生的输出大小如何,都会在内存中预留2,048大小的空间。这个空间可能会连续分配,而且,很多时候,其中的大部分空间并未被使用,导致内存浪费或碎片化。这个预留的空间在整个请求的生命周期内都会被占用。

受操作系统中分页的启发,PagedAttention算法允许将连续的键和值存储在内存中不连续的空间里。它将每个请求的KV缓存划分为代表固定数量token的块,这些块可以不连续地存储。
在注意力计算过程中,根据需要通过一个记录块位置的表格来获取这些块。随着新token的生成,会分配新的块。这些块的大小是固定的,消除了因不同请求需要不同大小的分配而产生的效率低下问题。这极大地减少了内存浪费,使得可以使用更大的批处理大小(进而提高了吞吐量)。
模型优化技术
到目前为止,我们讨论了LLM如何消耗内存、如何将内存分布在多个GPU上的一些方法,以及优化注意力机制和KV缓存的方法。还有一些模型优化技术,通过修改模型权重本身来减少每个GPU上的内存使用。GPU还具有专门的硬件来加速这些修改后的值上的操作,为模型提供更多的加速。
量化
量化是减少模型权重和激活值精度的过程。大多数模型使用32位或16位的精度进行训练,其中每个参数和激活元素占据32位或16位的内存——一个单精度浮点数。然而,大多数深度学习模型可以用每个值8位甚至更少的位数有效表示。
下图展示了量化前后的值分布。在这种情况下,一些精度由于舍入而丢失,一些动态范围由于裁剪而丢失,这使得值可以以更小的格式表示。
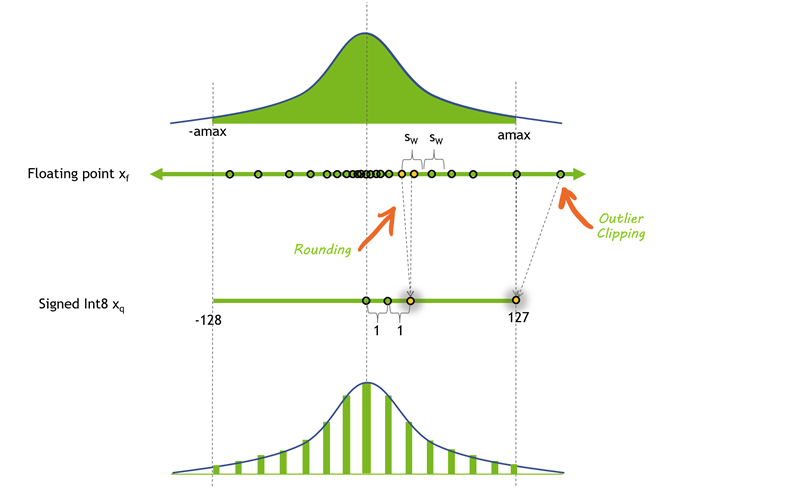
降低模型的精度可以带来诸多好处。如果模型在内存中占用的空间更少,你就可以在相同的硬件上容纳更大的模型。量化也意味着你可以通过相同的带宽传输更多的参数,这对于带宽受限的模型加速尤其有帮助。
对于LLM,有许多不同的量化技术,涉及降低激活值、权重或两者的精度。量化权重更为直接,因为它们在训练后是固定的。然而,这可能会留下一些性能未发挥,因为激活值仍然保持在较高的精度。GPU没有专门的硬件来乘以INT8和FP16数字,所以权重必须转换回更高的精度来进行实际操作。
也可以量化激活值,即变压器块和网络层的输入,但这带来了自身的挑战。激活向量通常包含异常值,实质上增加了它们的动态范围,使得以比权重更低的精度表示这些值变得更加困难。
一种选择是通过将代表性数据集传递给模型来找出这些异常值可能出现的位置,并选择以比其他激活值更高的精度表示某些激活值(LLM.int8())。另一种选择是从容易量化的权重中借用动态范围,并在激活值中重用该范围。
稀疏性
与量化类似,研究显示许多深度学习模型对修剪具有鲁棒性,即可以将某些接近0的值替换为0本身。稀疏矩阵是其中许多元素为0的矩阵。这些矩阵可以以比完整密集矩阵占用空间更少的压缩形式表示。
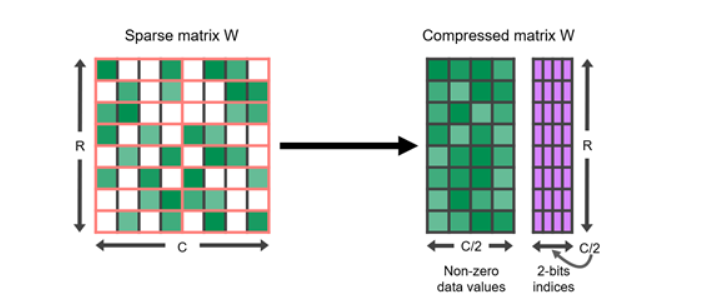
特别是GPU具有对某种结构性稀疏的硬件加速功能,其中每四个值中有两个被零表示。稀疏表示还可以与量化结合,以实现执行速度的进一步提升。寻找以稀疏格式表示大型语言模型的最佳方式仍然是一个活跃的研究领域,为未来推断速度的改进提供了有前景的方向。
蒸馏
缩小模型规模的另一种方法是通过一个称为蒸馏的过程,将模型的知识转移到较小的模型上。这一过程涉及训练一个较小的模型(称为学生)来模仿较大模型(教师)的行为。
成功的蒸馏模型例子包括DistilBERT,它将BERT模型压缩了40%,同时以60%更快的速度保留了97%的语言理解能力。
尽管在LLM中蒸馏是一个活跃的研究领域,但神经网络中的通用方法最早在Distilling the Knowledge in a Neural Network中进行了描述:
学生网络被训练以反映更大教师网络的表现,使用衡量两者输出差异的损失函数。这一目标可能还包括与地面真实标签匹配的学生输出的原始损失函数。
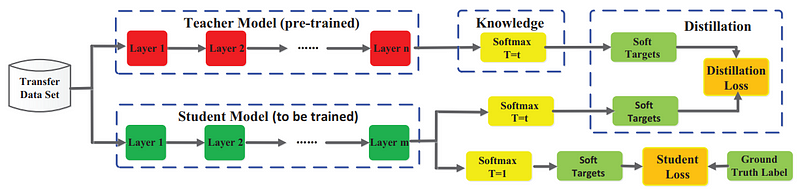
与之匹配的教师输出可以是最末一层(称为logits)或中间层的激活。
下图展示了一个知识蒸馏的一般框架。教师的logits是学生使用蒸馏损失进行优化的软目标。其他蒸馏方法可能使用其他损失度量从教师中“蒸馏”知识。
蒸馏的一种替代方法是使用由教师模型合成的数据来监督训练学生LLM,当人类注释稀缺或不可获得时,这种方法特别有用。Distilling Step by Step!:https://arxiv.org/abs/2305.02301更进一步,除了作为事实依据的标签外,还从教师LLM中提取推理依据。这些推理依据作为中间推理步骤,以数据高效的方式训练小型学生LLM。
值得注意的是,当今许多最先进的LLM拥有严格的许可条款,禁止使用其输出来训练其他LLM,这使得找到合适的教师模型变得具有挑战性。
模型服务技术
模型执行经常受到内存带宽的限制——特别是在权重方面受到带宽的约束。即使应用了前面描述的所有模型优化,仍然很可能处于内存受限的状态。因此,当模型权重加载时,应尽可能多地利用它们。换句话说,尝试并行处理。有两种方法可以采取:
飞行中批处理(In-flight batching)涉及同时执行多个不同的请求。
推测性推理(Speculative inference)涉及并行执行序列的多个不同步骤,试图节省时间。
飞行中批处理
LLM具有一些独特的执行特性,这在实践中可能使得有效地批量处理请求变得困难。单一模型可以同时用于各种外观截然不同的任务。从聊天机器人中的简单问答响应到文档摘要或长段代码的生成,工作负载高度动态,输出大小相差几个数量级。
这种多样性使得有效批量处理请求并并行执行它们变得具有挑战性——这是服务神经网络时的常见优化手段。这可能导致一些请求比其他请求早得多完成。
为了管理这些动态负载,许多LLM服务解决方案包括一种优化的调度技术,称为连续或飞行中批处理。这利用了这样一个事实:LLM的整体文本生成过程可以分解为模型上的多次执行迭代。
在飞行中批处理中,服务器运行时不会等待整个批次完成后再开始下一批请求,而是立即从批次中移除已完成的序列。然后,当其他请求仍在进行中时,开始执行新请求。因此,飞行中批处理可以在实际应用场景中大大提高整体GPU利用率。
推测性推理
也被称为推测性采样、辅助生成或逐块并行解码,推测性推理是并行执行LLM的另一种方式。通常,GPT风格的大规模语言模型是自回归模型,逐个token生成文本。
生成的每个token依赖于它之前的全部token来提供上下文。这意味着在常规执行中,不可能并行生成来自同一序列的多个token——你必须等到第n个token生成后才能生成第n+1个。
下图展示了推测性推理的一个例子,其中草稿模型暂时预测多个未来的步骤,这些步骤并行地被验证或拒绝。在这个例子中,草稿中预测的前两个token被接受,而最后一个被拒绝并在继续生成之前被移除。
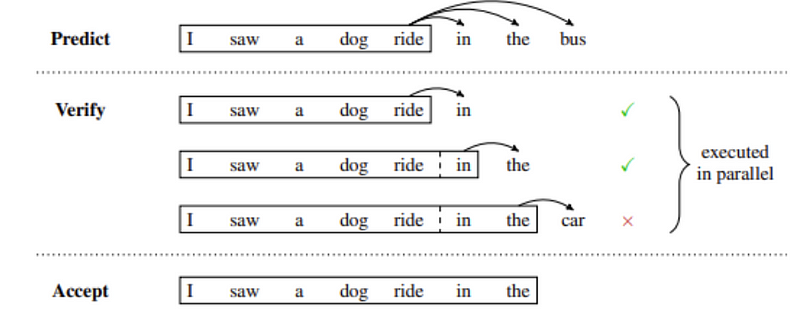
推测性采样提供了一种变通方案。这种方法的基本思想是使用某种“成本较低”的过程生成一个较长的草稿延续。然后,在多个步骤中并行执行主要的“验证”模型,使用低成本的草稿作为“推测性”上下文,用于需要它的执行步骤。
如果验证模型生成的token与草稿相同,则可以确定接受这些token作为输出。否则,可以从第一个不匹配的token之后丢弃所有内容,并使用新的草稿重复此过程。
生成草稿token有多种不同的选项,每种都有不同的权衡。你可以训练多个模型,或者在单个预训练模型上微调多个头部,以预测未来的多个步骤的token。或者,你可以使用一个小模型作为草稿模型,一个更大、更强大的模型作为验证者。
LLM服务中的关键指标
那么,我们究竟应该如何考虑推理速度呢?
我们使用四个关键指标来衡量LLM服务:
首次token时间(TTFT):用户在输入查询后看到模型输出的速度。实时交互中对响应等待时间的要求很低,但在离线工作负载中则不太重要。该指标取决于处理提示和生成第一个输出token所需的时间。
每个输出token时间(TPOT):为每个查询我们系统的用户生成输出token的时间。该指标对应于每个用户感知的模型“速度”。例如,TPOT为100毫秒/token将为每个用户提供每秒10个token,或约每分钟450个单词,这比普通人阅读速度还要快。
延迟:模型为用户生成完整响应所需的总时间。总体响应延迟可以使用前两个指标计算得出:延迟 = (TTFT) + (TPOT)*(待生成的token数)。
吞吐量:推理服务器在所有用户和请求中每秒可以生成的输出token数。
我们需要什么来实现一个LLM服务?
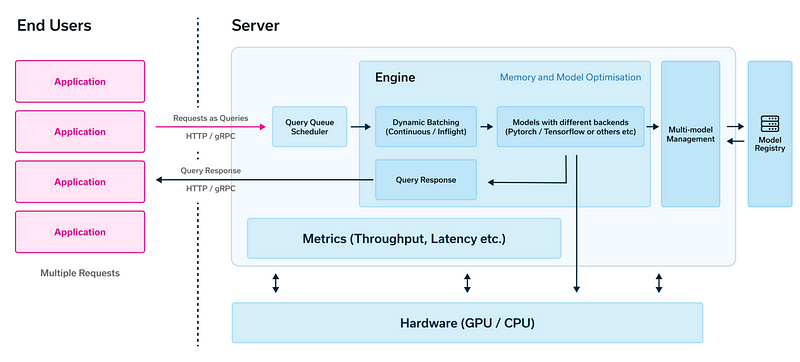
在服务基于LLM的应用程序时,主要有两大组件:引擎和服务器。引擎负责处理所有关于模型和请求批处理的工作,而服务器则负责转发用户的请求。
引擎
引擎是运行模型的地方,涵盖了我们迄今为止讨论过的所有生成过程及其各种优化技术。本质上,这些都是Python库。它们处理从用户到我们聊天机器人的请求批处理,并为这些请求生成响应。
服务器
服务器负责协调来自用户的HTTP/gRPC请求。在实际应用中,我们会有许多用户在一天的不同时间向我们的聊天机器人提问。服务器将这些请求排队,并将其转发给引擎以生成响应。服务器还提供了诸如吞吐量和延迟这样的指标,对于跟踪模型服务非常重要。
功能
引擎
内存优化
特定模型优化
批处理支持
服务器
HTTP/gRPC API接口
请求队列
多模型服务
多引擎支持

到目前为止,我们讨论了一个模型处理单一请求的简单场景。然而,现实世界的应用要求能够同时服务于数百,甚至数千名用户。现在,我们的关注点转向了成本优化和吞吐量提升,引导我们进入下一个关键议题:请求批处理和利用PagedAttention进行内存优化。这些优化措施对于高效承载模型至关重要,确保在面对大量用户需求时,既经济高效又具备高吞吐量。
LLM服务的框架
在介绍了关键指标、权衡及处理LLM服务中重大挑战的技术之后,一个重要的问题是:我们如何将这些技术付诸实践?哪些工具最适合我们的需求?在深入研究之前,我们应该了解哪些关于这些框架的信息?
在本节中,我们将深入探讨这些关键框架的细节,分享我们基准测试实验的主要发现。我们选择了行业中最受欢迎和广泛使用的框架。每个框架在优化和增强大规模语言模型(LLM)推理性能方面具有独特价值。我们将这些框架分为两大类:服务器和引擎。最终,我们将对现有工具及其潜在适应性有清晰的认识,以满足我们具体的LLM服务需求。
1. vLLM

一个快速且易于使用的库,用于LLM推理和服务。它实现了比HuggingFace Transformers (HF)高14到24倍的吞吐量,比HuggingFace Text Generation Inference (TGI)高2.2到2.5倍的吞吐量。
使用
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")API服务:
# Start the server:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Query the model in shell:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'杀手级功能
Continuous batching — 迭代级别的调度,其中每迭代确定批处理大小。得益于批处理,vLLM在重查询负载下也能表现良好。
PagedAttention — 受操作系统中经典虚拟内存和分页概念启发的注意力算法。这是模型加速的秘密武器。
优点
文本生成速度 — 我用这个库进行了几次实验,对其结果非常满意。目前,使用vLLM进行推理是最快的选择。
高吞吐量服务 — 包括并行采样、束搜索等在内的多种解码算法。
兼容OpenAI的API服务器 — 如果我们使用过OpenAI API,只需替换端点的URL即可。
局限性
虽然该库提供了用户友好的特性和广泛的功能,但我确实遇到了一些局限:
添加自定义模型:虽然可以加入我们自己的模型,但如果模型架构与vLLM现有的模型不相似,这一过程就会变得较为复杂。
缺乏对适配器的支持(LoRA,QLoRA等):开源LLM在针对特定任务微调时具有巨大价值。然而,在当前实现中,没有选项可以单独使用模型和适配器权重,这限制了有效利用这类模型的灵活性。
缺少权重量化:有时,LLM可能无法装入可用的GPU内存,因此减少内存消耗至关重要。
这是进行LLM推理最快的库。由于其内部优化,它在性能上远远超过了竞争对手。然而,它在支持的模型范围方面存在弱点。
2. Text Generation Inference

Text Generation Inference(TGI)是一个用于部署和提供大型语言模型(LLM)的工具包。TGI为最受欢迎的开源LLM,包括Llama、Falcon、StarCoder、BLOOM、GPT-NeoX和T5,实现了高性能文本生成。
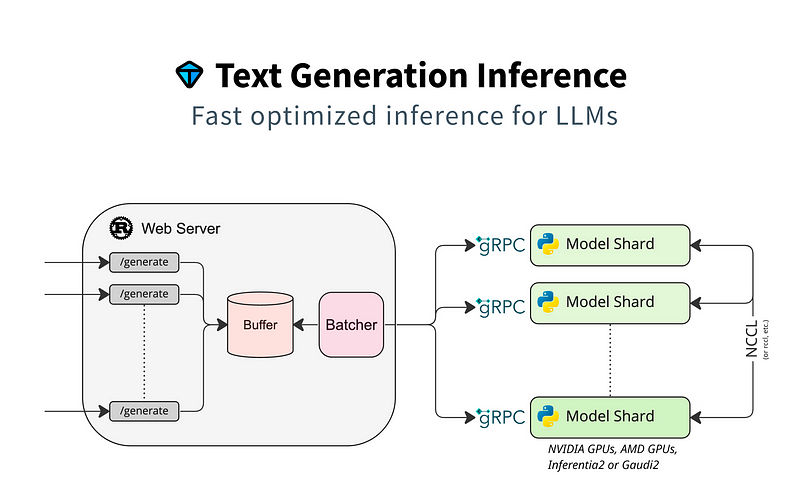
一个用于文本生成推理的Rust、Python和gRPC服务器。在HuggingFace的生产环境中使用,用来为LLM API推理小组件。
使用
使用docker运行web服务器:
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1制作请求:
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)优点
所有依赖项都安装在Docker中 — 我们立即获得一个即用型环境,可在我们的机器上运行。
原生支持HuggingFace的模型 — 轻松运行我们的模型或使用HuggingFace模型中心的任何模型。
对模型推理的控制:框架提供了广泛的选项来管理模型推理,包括精度调整、量化、张量并行、重复惩罚等。
局限性
缺乏适配器支持 — 需要指出的是,虽然可以部署带有适配器的LLM,但目前尚无官方支持或文档说明。
必须从源代码编译(Rust + CUDA内核)— 不要误会我的意思,我很欣赏Rust,但并非所有数据科学团队都熟悉它,这可能使将自定义更改纳入库中变得具有挑战性。
文档不完整:所有信息都可在项目README中找到。虽然它涵盖了基础知识,但我在某些情况下不得不在问题或源代码中查找更多细节(特别是当处理Rust语言时,对我来说尤其困难)。
我认为这是竞赛中的领先者之一。该库编写得非常好,我在部署模型时几乎没遇到什么难题。如果希望与HuggingFace进行原生集成,这绝对值得考虑。请注意,项目团队最近变更了许可证。
3. CTranslate2

CTranslate2是一个用于Transformer模型高效推理的C++和Python库。
使用
首先,转换模型:
pip install -qqq transformers ctranslate2
# The model should be first converted into the CTranslate2 model format:
ct2-transformers-converter --model huggyllama/llama-13b --output_dir llama-13b-ct2 --force制作请求:
import ctranslate2
import transformers
generator = ctranslate2.Generator("llama-13b-ct2", device="cuda", compute_type="float16")
tokenizer = transformers.AutoTokenizer.from_pretrained("huggyllama/llama-13b")
prompt = "Funniest joke ever:"
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt))
results = generator.generate_batch(
[tokens],
sampling_topk=1,
max_length=200,
)
tokens = results[0].sequences_ids[0]
output = tokenizer.decode(tokens)
print(output)杀手级特性
在CPU和GPU上的快速高效执行 — 得益于一系列内置优化:层融合、填充移除、批处理重排序、原地操作、缓存机制等,使得LLM推理更快,且内存需求更低。
动态内存使用 — 根据请求大小动态改变内存使用,同时仍能满足性能要求,这得益于CPU和GPU上的缓存分配器。
支持多种CPU架构 — 项目支持x86–64和AArch64/ARM64处理器,并集成了多个针对这些平台优化的后端:Intel MKL、oneDNN、OpenBLAS、Ruy和Apple Accelerate。
优势
并行和异步执行 — 可以利用多个GPU或CPU核心并行和异步处理多个批次。
提示缓存 — 模型在静态提示上仅运行一次,然后缓存模型状态,供未来具有相同静态提示的调用复用。
磁盘上的轻量级 — 量化可以使模型在磁盘上缩小4倍,且精度损失极小。
局限性
没有内置REST服务器 — 尽管我们仍然可以运行REST服务器,但我希望有一个现成的服务,具备日志记录和监控功能。
缺乏对适配器(LoRA,QLoRA等)的支持。
我发现这个库很吸引人。开发者们在积极维护它,这一点从GitHub上的发布和提交可见一斑,他们还分享了一些关于应用该库的博客文章。库中大量的优化令人印象深刻,而它的主要亮点在于能够在CPU上执行LLM推理。
4. DeepSpeed-MII

MII利用了DeepSpeed,实现了低延迟和高吞吐量的推理。
使用
运行Web服务器:
# DON'T INSTALL USING pip install deepspeed-mii
# git clone https://github.com/microsoft/DeepSpeed-MII.git
# git reset --hard 60a85dc3da5bac3bcefa8824175f8646a0f12203
# cd DeepSpeed-MII && pip install .
# pip3 install -U deepspeed
# ... and make sure that you have same CUDA versions:
# python -c "import torch;print(torch.version.cuda)" == nvcc --version
import mii
mii_configs = {
"dtype": "fp16",
'max_tokens': 200,
'tensor_parallel': 1,
"enable_load_balancing": False
}
mii.deploy(task="text-generation",
model="huggyllama/llama-13b",
deployment_name="llama_13b_deployment",
mii_config=mii_configs)制作:请求:
import mii
generator = mii.mii_query_handle("llama_13b_deployment")
result = generator.query(
{"query": ["Funniest joke ever:"]},
do_sample=True,
max_new_tokens=200
)
print(result)杀手级特性
多副本负载均衡 — 对于处理大量用户请求而言,这是一个极其实用的工具。负载均衡器高效地将传入请求分散到各个副本中,从而显著提升应用响应时间。
非持久化部署 — 这是一种更新不会永久应用于目标环境的策略。在资源效率、安全性、一致性以及易于管理至关重要的场景下,这是一种明智选择。它能够创建一个更加受控和标准化的环境,同时降低运维负担。
优势
多个模型仓库 — 通过Hugging Face、FairSeq、EluetherAI等多个开源模型仓库可供使用。
量化延迟与成本削减 — MII能够大幅降低昂贵语言模型的推理成本。
原生与Azure集成 — 由微软开发的MII框架,与他们的云系统有着出色的兼容性。
局限性
缺乏官方发布版 — 我花了数小时才找到包含功能性应用的正确提交记录。部分文档已过时,不再适用。
支持的模型数量有限 — 不支持Falcon、LLaMA 2等语言模型。我们能运行的模型种类有限。
缺少对适配器(LoRA、QLoRA等)的支持。
该项目基于稳定可靠的DeepSpeed库,已在社区内赢得了良好口碑。如果我们追求稳定性和经过验证的方案,MII会是不错的选择。根据我的实验,该库在处理单个提示时表现出最快的响应速度。然而,我还是建议在将其整合进系统前,先在具体任务上测试框架的适用性。
5. OpenLLM

一个用于在生产环境中运营大型语言模型(LLM)的开放平台。
使用:
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1制作请求:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))杀手级特性
适配器支持 — 只需部署一个LLM即可连接多个适配器。想象一下,我们可以用单一模型完成多项专业任务。
运行时实现 — 使用不同的实现:Pytorch (
pt)、Tensorflow (tf) 或Flax (flax)。HuggingFace Agents— 在HuggingFace上链接不同模型,并使用LLM和自然语言进行管理。
优势
社区支持良好 — 库持续发展,不断添加新功能。
整合新模型 — 开发者提供了如何添加自己模型的指南。
量化 — OpenLLM支持与bitsandbytes和GPTQ的量化。
LangChain集成 — 我们可以使用LangChain与远程OpenLLM服务器交互。
局限性
缺乏批处理支持 — 面对大量消息流,这很可能成为应用程序性能的瓶颈。
缺乏内置分布式推理 — 若要在多GPU设备上运行大型模型,我们需要额外安装OpenLLM的服务器组件Yatai。
这是一个具有广泛功能的优秀框架。它让我们能够以最小的开销创建灵活的应用程序。虽然文档中可能有些方面没有完全覆盖,但在深入探索这个库的过程中,我们很可能会发现一些令人惊喜的附加功能。
6. Ray Serve

Ray Serve是一个可扩展的模型服务库,用于构建在线推理API。Serve与框架无关,因此我们可以使用同一套工具来服务从深度学习模型到各类模型的所有需求。
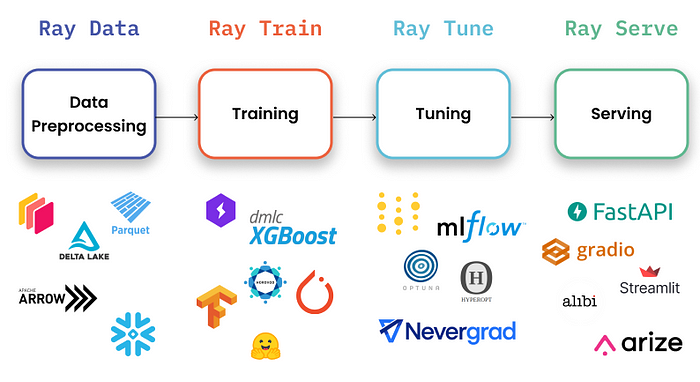
Ray AIR支持端到端的机器学习开发,并提供了多种选项以与其他MLOps生态系统中的工具和库集成。
使用
运行Web服务器:
# pip install ray[serve] accelerate>=0.16.0 transformers>=4.26.0 torch starlette pandas
# ray_serve.py
import pandas as pd
import ray
from ray import serve
from starlette.requests import Request
@serve.deployment(ray_actor_options={"num_gpus": 1})
class PredictDeployment:
def __init__(self, model_id: str):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate(self, text: str) -> pd.DataFrame:
input_ids = self.tokenizer(text, return_tensors="pt").input_ids.to(
self.model.device
)
gen_tokens = self.model.generate(
input_ids,
temperature=0.9,
max_length=200,
)
return pd.DataFrame(
self.tokenizer.batch_decode(gen_tokens), columns=["responses"]
)
async def __call__(self, http_request: Request) -> str:
json_request: str = await http_request.json()
return self.generate(prompt["text"])
deployment = PredictDeployment.bind(model_id="huggyllama/llama-13b")
# then run from CLI command:
# serve run ray_serve:deployment制作请求:
import requests
sample_input = {"text": "Funniest joke ever:"}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)杀手级特性
监控仪表板和Prometheus指标 — 我们可以使用Ray仪表板来全局概览我们的Ray集群和Ray Serve应用的状态。
跨多个副本自动扩缩容— 面对流量峰值,Ray通过观察队列大小并做出扩缩容决策,以增加或减少副本,从而实现自我调整。
动态请求批处理 — 当我们的模型使用成本高昂时,为了最大化硬件利用率,这一特性就显得尤为重要。
优势
详尽的文档 — 我非常欣赏开发者们在这方面的投入,他们认真对待文档的制作。对于几乎每种应用场景,我们都能找到众多示例,这对用户来说极为有益。
生产级就绪 — 在我看来,这是本列表中最为成熟的框架。
原生LangChain集成 — 我们可以使用LangChain与远程Ray服务器进行交互。
局限性
缺乏内置模型优化 — Ray Serve并不专注于LLM,它是一个更广泛的框架,适用于部署任何类型的ML模型。我们需要自行进行优化。
较高的入门门槛 — 有时,库中包含过多的附加功能,这提高了入门难度,让新手难以驾驭和理解。
如果我们需要的是一个不仅限于深度学习领域、且最为适合生产环境的解决方案,那么Ray Serve是一个不错的选择。它最适合那些重视可用性、可扩展性和可观测性的企业场景。此外,我们还可以利用其庞大的生态系统进行数据处理、训练、微调和模型服务。最后,它被从OpenAI到Shopify和Instacart的多家公司所采用。
7. MLC LLM

MLC LLM(机器学习编译针对LLM)是一个通用的部署解决方案,它使LLM能够高效地在消费级设备上运行,充分利用本地硬件加速。
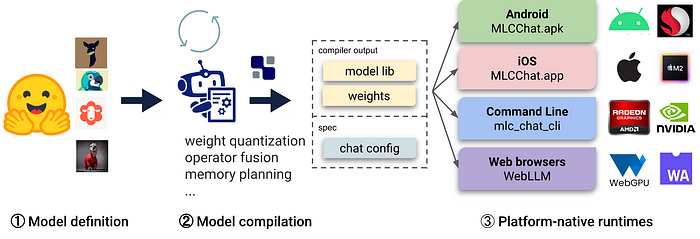
使用
运行web服务:
# 1. Make sure that you have python >= 3.9
# 2. You have to run it using conda:
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-nightly
conda activate mlc-chat-venv
# 3. Then install package:
pip install --pre --force-reinstall mlc-ai-nightly-cu118 \
mlc-chat-nightly-cu118 \
-f https://mlc.ai/wheels
# 4. Download the model weights from HuggingFace and binary libraries:
git lfs install && mkdir -p dist/prebuilt && \
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib && \
cd dist/prebuilt && \
git clone https://huggingface.co/huggyllama/llama-13b dist/ && \
cd ../..
# 5. Run server:
python -m mlc_chat.rest --device-name cuda --artifact-path dist制作请求:
import requests
payload = {
"model": "lama-30b",
"messages": [{"role": "user", "content": "Funniest joke ever:"}],
"stream": False
}
r = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload)
print(r.json()['choices'][0]['message']['content'])杀手级特性
平台原生运行时 — 在用户设备的原生环境中部署,这些设备可能并未预装Python或其他必要依赖。应用开发者只需熟悉平台原生运行时,就能将MLC编译的LLM集成到项目中。
内存优化 — 我们能够运用不同技术编译、压缩和优化模型,使其能够在各类设备上部署。
优势
所有设置都在JSON配置文件中 — 允许我们在单一配置文件中定义每个编译模型的运行时配置。
预构建应用 — 我们可以为不同平台编译模型:C++用于命令行,JavaScript用于Web,Swift用于iOS,Java/Kotlin用于Android。
局限性
使用LLM模型的功能有限:不支持适配器,无法改变精度,不支持token流等。该库主要关注于为不同设备编译模型。
仅支持分组量化 — 尽管这种方法已经显示出不错的效果,但社区中更流行的量化方法是bitsandbytes和GPTQ。很可能这些方法将在社区中得到更好的发展。
安装复杂 — 我花了几个小时才正确安装库。对于初学者开发者来说,它可能不太适用。
如果我们需要在iOS或Android设备上部署应用,这个库正是我们需要的。它将使我们能够迅速地在设备上原生编译和部署模型。然而,如果我们需要的是高负载服务器,我不会推荐选择这个框架。
结论
在我们的白皮书中,我们使用不同设置评估了这些框架及其提供的功能。无论是像TensorRT-LLM和vLLM这样的引擎,还是像RayLLM与RayServe、带有TensorRT-LLM的Triton以及Text Generation Inference (TGI)这样的服务器,每个框架都带来了独特的功能,对于不同应用场景具有重要价值。我们的基准测试研究揭示了一些微妙的发现,从内存分配挑战到预占空比的战略权衡,以及序列长度对吞吐量的影响。以下是我们在实验中学到的一些要点概述:
内存是关键。内存分配的管理对于优化LLM性能至关重要。
预占空比对于像vLLM这样的引擎而言是一个战略权衡,因为生成操作受到内存限制,而GPU的利用率较低。
序列长度洞察显示了vLLM在处理并发请求方面的效率,尤其是对于较短输出的情况。
模型大小显著影响吞吐量。然而,超过一定点后,额外的GPU内存不再促进更高的吞吐量。
服务器选择发挥着核心作用,正如白皮书中TensorRT-LLM与Triton的表现优于独立的TensorRT-LLM所展示的那样。
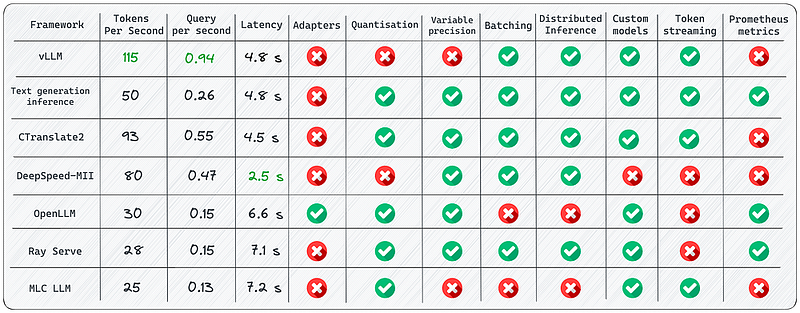
尽管存在大量的LLM推理框架,但每个框架都有其特定的用途。以下是一些关键考量点:
当需要为批量提示提供最大速度时,使用vLLM。
如果我们需要原生HuggingFace支持,并且不打算为核心模型使用多个适配器,可以选择Text generation inference。
如果速度对我们至关重要,且我们计划在CPU上运行推理,可以考虑CTranslate2。
如果想要将适配器连接到核心模型,并利用HuggingFace Agents,特别是在不完全依赖PyTorch的情况下,可以选择OpenLLM。
对于稳定的流水线和灵活的部署,可以考虑Ray Serve,它尤其适合较为成熟的项目。
如果希望在客户端(边缘计算)原生部署LLM,例如在Android或iPhone平台上,可以利用MLC LLM。
如果我们已经熟悉DeepSpeed库,并希望继续使用它来部署LLM,可以选择DeepSpeed-MII。

—END—
英文原文:https://medium.com/@vipra_singh/building-llm-applications-serving-llms-part-9-68baa19cef79

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









