






摘要
有监督微调 (SFT) 通常用于训练语言模型,以模仿给定指令的带标注的响应。在本文中,我们挑战了这一范式,并提出了批判式微调 (CFT),这是一种让模型学会批判嘈杂响应而不是简单地模仿正确响应的策略。受强调批判性思维的人类学习过程的启发,CFT 鼓励更深入的分析和细致的理解——这些特征经常被标准 SFT 所忽视。为了验证 CFT 的有效性,我们从 WebInstruct 构建了一个 50K 样本数据集,使用 GPT-4o 作为老师,以 ([query;noisy response],critique) 的形式生成批判。使用不同的基础模型(如 Qwen2.5、Qwen2.5-Math 和 DeepSeek-Math),此数据集上的 CFT 在六个数学基准上比 SFT 产生了 4-10% 的持续改进。我们进一步扩展到 MetaMath 和 NuminaMath 数据集,并观察到与 SFT 相比的类似收益。值得注意的是,我们的模型 Qwen2.5-Math-CFT 只需要在 50K 个示例中对 8xH100 进行 1 小时的训练。它可以在大多数基准测试中匹敌或超越 Qwen2.5-Math-Instruct 等强大的竞争对手,这些基准测试使用超过 2M 个样本。此外,它可以匹配 SimpleRL 的性能,SimpleRL 是使用 140 倍计算能力训练的 DeepSeek-r1 复制品。消融研究表明,CFT 对噪声响应源和教师批评模型具有鲁棒性。通过这些发现,我们认为 CFT 提供了一种更有效的替代方案来推进语言模型的推理。
1.介绍
最近,大语言模型 (LLM) 在解决实际问题方面表现出了前所未有的性能。核心技术之一是有监督微调 (SFT),它训练这些 LLM 遵循自然语言指令。在 SFT 过程中,LLM 被迫模仿带标注的响应。人们已经付出了很多努力来构建高质量的 SFT 数据集,使用 Self-Instruct 和 Evol-Instruct 等方法增强 LLM 的通用指令遵循能力。最近,MAmmoTH、MetaMath 和 WizardCoder 等作品已经采用 SFT 来提高 LLM 在数学推理、编码等领域的目标能力。虽然这些方法在较弱的 base 模型(如 Mistral 或 LLaMA3)上显示出显着的收益,但随着 SFT 数据集的大小和质量的扩大,收益递减变得明显。这种限制对于已经很强大的 base 模型(非 SFT 的)尤其明显,例如 Qwen2.5-base、Qwen2.5-Mathbase 或 DeepSeek-Coder-V2-base,这些模型已经在包含数千亿个 token 的以推理为重点的语料库上进行了广泛的领域自适应预训练。我们在第 3 节中的实验表明,在没有严格的质量控制的情况下,将 SFT 应用于这些模型甚至会降低性能。
在本文中,我们挑战了 SFT 的主流范式,并提出了一种称为“批判微调”(CFT)的新学习框架。受人类学习的启发(批判性思维和建设性反馈对于改进至关重要),我们将重点从简单的模仿转移到基于批判的学习。当人类学习时,他们不仅仅是复制提供的答案,而是分析、批判和改进它们。同样,在 CFT 中,模型学习对嘈杂的响应提供批评,识别缺陷,提出改进建议并验证正确性。正式来说,CFT 涉及训练模型取批评给定的qeury-response对,以最大化似然
P
(
c
∣
[
x
;
y
]
)
P(c|[x; y])
P(c∣[x;y]),其中
c
c
c 是qeury-response对
[
x
;
y
]
[x; y]
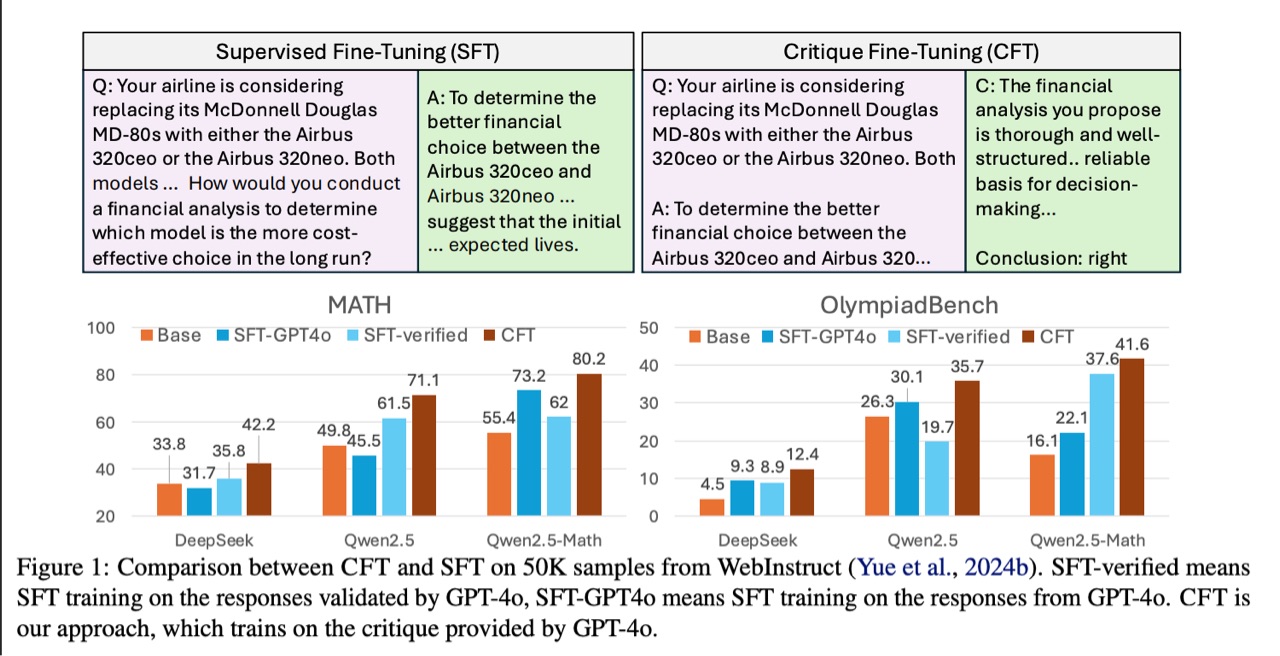
[x;y] 的标注批评。图 1 显示了 CFT 的详细可视化。
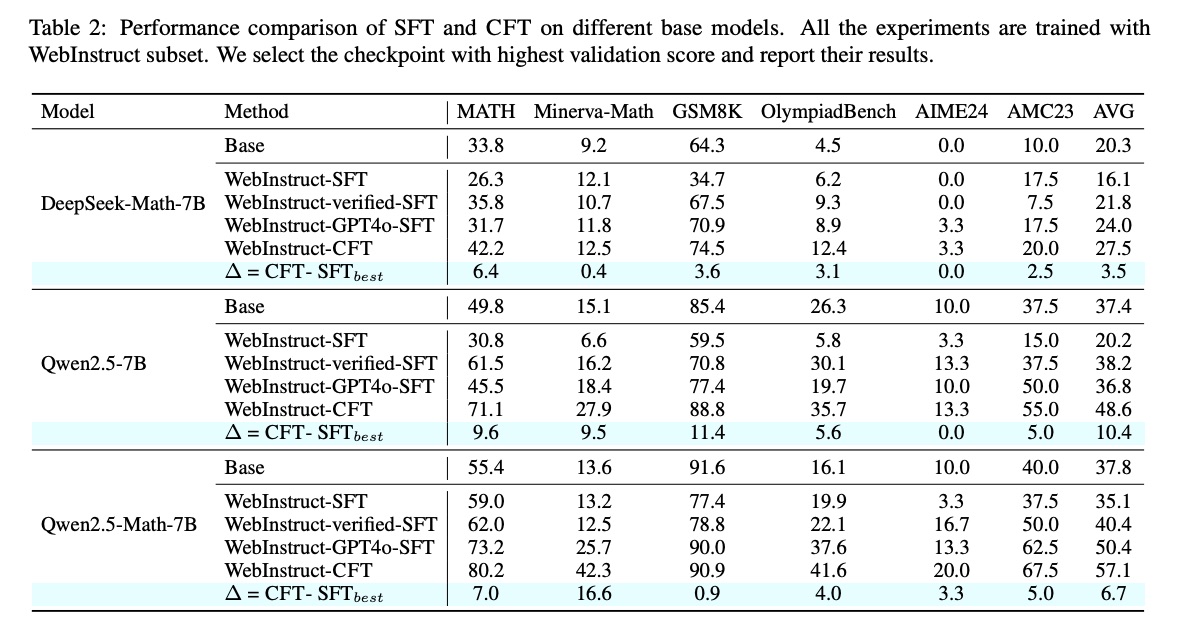
为了验证 CFT 的有效性,我们设计了一系列实验。首先,我们从 WebInstruct 构建了一个 50K 评论数据集,其中的评论由 GPT-4o 等高级模型合成。我们将 CFT 应用于强大的 7B 基础语言模型(即非指令微调模型),例如 DeepSeekMath-base、Qwen2.5) 和 Qwen2.5-Math。这些模型与 SFT 训练的变体进行了比较,例如 WebInstruct-verified(对 GPT-4o 验证的 WebInstruct 响应进行 SFT)和 WebInstruct-GPT4o(直接对 GPT-4o 生成的响应进行 SFT)。在包括 MATH 和 AIME24 在内的六个数学基准上进行评估时,CFT 训练的模型可以始终比最好的 SFT 训练模型平均高出 4-10 个绝对点。
我们将评估范围扩大到更广泛的 STEM 基准,包括 GPQA、TheoremQA 和 MMLU-Pro。我们的结果表明,最佳 CFT 训练模型 Qwen2.5-Math-CFT(在 50K 个示例上训练)的表现优于 AceMath 和 Qwen2.5-Math-Instruct 等强大的竞争对手,后者在超过 2M 个样例上训练。我们还将 Qwen2.5-Math-CFT 与 SimpleRL 进行了比较,后者是 DeepSeek-R1 的公开复制品,训练所需的计算量增加了 140 倍(1152 H100 小时 vs 8 H100 小时)。我们的实验表明,Qwen2.5-Math-CFT 可以在 5 个数学基准上达到相同的平均性能。这凸显了 CFT 对于以推理为重点的任务的效率和有效性。
为了更好地了解 CFT 的不同因素,我们进行了全面的消融研究:
- Robustness to dataset sources:将 WebInstruct 与 MetaMathQA 和 NuminaMath 进行比较,我们发现 WebInstruct 由于其多样性和更广泛的主题覆盖范围而具有轻微优势(3%+)。
- Robustness to noisy response sources:我们对原始的嘈杂响应和 GPT-4o 批评的 Qwen2.5-base 响应进行了实验。性能差异可以忽略不计。
- Flexibility to the teacher critique model:使用由 GPT-4o-mini 而不是 GPT-4o 合成的较弱的评论数据集,尽管总体得分下降了 4%,但我们仍然观察到比 SFT 显着改善。
通过这些实验,我们证明了 CFT 比 SFT 更有效、更高效。然而,我们的方法也有局限性。首先,CFT 数据集完全由 GPT-4o 合成,至少有 20% 的评论包含错误。提高评论数据集的质量可以进一步提高性能。其次,CFT 训练的模型目前缺乏自我批评的能力,因此我们还没有观察到自我改进的效果。未来的工作将进一步探索这些方向。
2. Method & Dataset
为了验证 CFT 的有效性,我们构建了几个微调数据集。我们的大多数实验都基于 WebInstruct,这是一个从在线教育资源和测验网站收集的指导数据集。该数据集在其管道中使用大语言模型进行了综合处理,以提高解决方案质量和格式一致性。
2.1. WebInstruct
WebInstruct 涵盖的主题范围很广,包括数学(65%)、物理(8%)、化学(4%)、商业(10%)、人文(4%)等。与其他主要来自数学竞赛和比赛的数据集不同,WebInstruct 提供更广泛的主题覆盖范围。WebInstruct 中的响应由 Qwen-72B 和 Mixtral 等大语言模型提取和细化,由于缺乏验证或质量控制,它们很容易受到噪音的影响。
我们从 WebInstruct 中精选了以下子集:
- WebInstruct-SFT:从原始 WebInstruct 数据集直接采样的 50K 子集。该子集的错误率非常高(超过 50%)。
- WebInstruct-verified:我们采用来自 WebInstruct 的样本,并提示 GPT-4o-1120 判断原始答案是否正确。我们保留前 50K 个样本作为“已验证”的 SFT 数据。
- WebInstruct-GPT-4o:一个 50K 的子集,它重用了 WebInstruct-SFT 中的问题,但用 GPT-4o-1120 生成的答案替换了答案。
- WebInstruct-CFT (Ours):从 WebInstruct-SFT 派生的 50K 子集,其中 GPT-4o-1120 对原始回复提供了详细的批评。该子集中约 56% 的回复被判定为“正确”,其余的则被认为是“错误的”。尽管包含一些由 GPT-4o 引入的批评错误,但该数据集的质量与 WebInstruct-GPT-4o 相当。
- WebInstruct-CFT-Tiny (Ours):WebInstruct-CFT 的较小版本,仅包含 4K 示例,专为训练我们的 32B 模型而设计。
我们在表 1 中将我们的 CFT 数据集与现有的 SFT 数据集进行了比较。如表所示,我们的数据集涵盖了更广泛的主题,同时规模明显较小,突显了它们在提升 LLM 推理能力方面的效率。
2.2. MetaMath & NuminaMath
除了 WebInstruct 之外,我们还综合了对其他数据集的评价,包括 MetaMathQA 和 NuminaMath。我们从每个数据集中随机抽取了 50K 个示例,并使用 GPT-4o 来评价原始响应。然后,我们将 CFT 应用于这些数据集,以证明我们的方法在其他数据集中的通用性。
2.3. Training Objective
我们的方法的训练目标很简单。我们将问题
x
x
x 和嘈杂的响应
y
y
y 连接起来作为输入,然后优化模型参数以生成评论
c
c
c。正式来说,训练损失是:
a
r
g
m
a
x
θ
l
o
g
P
(
c
∣
[
x
;
y
]
,
θ
)
(1)
argmax_{\theta}log~P(c|[x;y],\theta)\tag{1}
argmaxθlog P(c∣[x;y],θ)(1)
其中θ是语言模型的参数。
3.实验

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









