







引言
我们都知道进行深度学习都需要将数据转换为数字(向量),CV领域,图像都是以矩阵方式存储的,所以一般不需要特别转换,只需要根据网络结构对图片进行resize等预处理操作。
那么对于NLP领域,文字如何处理转换为向量是一个问题。一种是我们可以使用传统的one-hot(独热编码),将每一个词转换为一个编码,如下图,我们有6个名字,我们可以对其使用独热编码,获得如图的独热编码。但是,独热编码有很大的缺点:①向量之间没有相似性,很明显,由线性代数的知识我们可以知道,这些向量之间没有相似性,所以使用独热编码的文字之间也没有相似性。②独热编码在面对庞大的词量时,所需要的空间很大。

所以我们需要一种方法使得词向量之间具有相似性,以及降低数据维度。
这就是word2vec所做的,也是NLP领域的基础。我们这里介绍其中一种方法CBOW模型,提供了我自己的理解,我会以深度学习整体的角度来解释,以抽象容易理解的方向看待这个模型。
1.CBOW模型简介
CBOW(Continuous Bag-of-Words)可以将传统的稀疏的独热编码词向量转化为稠密的词向量。
这个模型的大致思路是,通过神经网络把上下文当成X预测中间词Y,但它有窗口滑动,每个词都是Y,所以它是无监督学习,不需要人工添加标签。
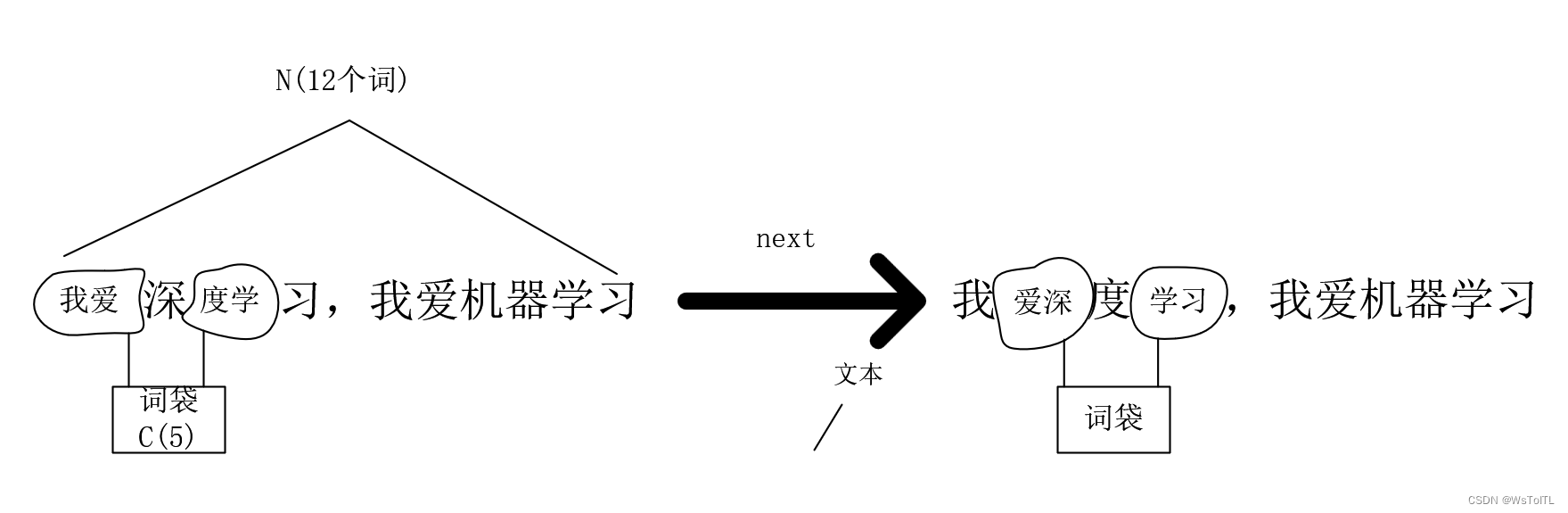
1.1 我们先来看看原文的思路: 首先我们有一个N个词的字典需要训练,我们设定一个C个词大小的窗口(一般为奇数,这样中间词的上下文数量是相同的)这个就是原文所称的词袋,把中间词当成要推理的label,上下文当成数据X放进词袋中,直到遍历整个词典,如图:
1.2 再来看看数学描述:
将每个词都分配一个one-hot编码的向量,维度为词典的长度,所以每个词的向量为(1,N)的向量,这个列向量乘以一个Q矩阵(N,V)V的维度是我们自己定,就会得到一个新的列向量,我们将词袋中上下文作为输入,其对应的独热编码都乘以同一个Q矩阵(这个矩阵就是词嵌入矩阵),得到的向量相加再求平均得到一个新列向量,这个列向量再乘以一个W矩阵,就得到了一个1XN的向量,我们需要的是最后得到的最后这个1XN的向量和原来的独热编码一样(使用MSE损失对整个网络进行反向传播)。 这个就是模型的数学描述,这时候Q矩阵就是我们所需要的词嵌入变换矩阵,当我们的的独热编码列向量乘以这个Q矩阵,就得到了我们所需要的词嵌入向量,降维但拥有句子间联系的,为什么呢?会在下面深度学习方面理解。数学表达式图如下:

1.3 神经网络角度理解:
首先我们看它的网络结构,我们可以将其网络结构分成两部分看,前半部分可以看成是特征提取,前面的全连接层FC1的系数就是我们需要的词嵌入矩阵,经过前面部分的变换后我们可以就能得到词向量。 关键的理解点在于,我们需要把这个网络从全局的角度来看,前半部分就是传统的特征变换,后半部分就是拿变换后的特征进行SoftMax预测,我们需要使SoftMax的结果与中间词的独热编码相近,使用loss函数对整个网络进行反向传播,经过多次叠代后我们能得到理想结果,此时我们输入词经过FC1层后得到的向量就是词向量,具有句子间的相似性。理解完后不得不感叹数学和AI的美。
















 2571
2571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









