







目录
1. EfficientFormer介绍
2. 环境配置和修改文件
3.修改文件
4. 启动
运行环境:Windows10 I7-13700k RTX4080 Cuda11.3
1. 介绍
Transformer和CNN在CV领域广泛使用,CNN和Transformer已经对战多年, 在目标检测中通常是CNN比较常用,因为transfomer参数量大且训练时间长.
最近的一篇论文提出了EfficientFormer是改进的VIT(vision transformer),其在轻量化的同时也能提高精度,并且目标是达到移动设备可以使用的速度。为了水论文,我们可以跑通这个模型,并训练自己的数据集,接下来我将一步步介绍如何训练自己的模型.从官方论文结果来看改进后的参数量和速度提升了很多. 源代码是基于mmdetction框架实现的。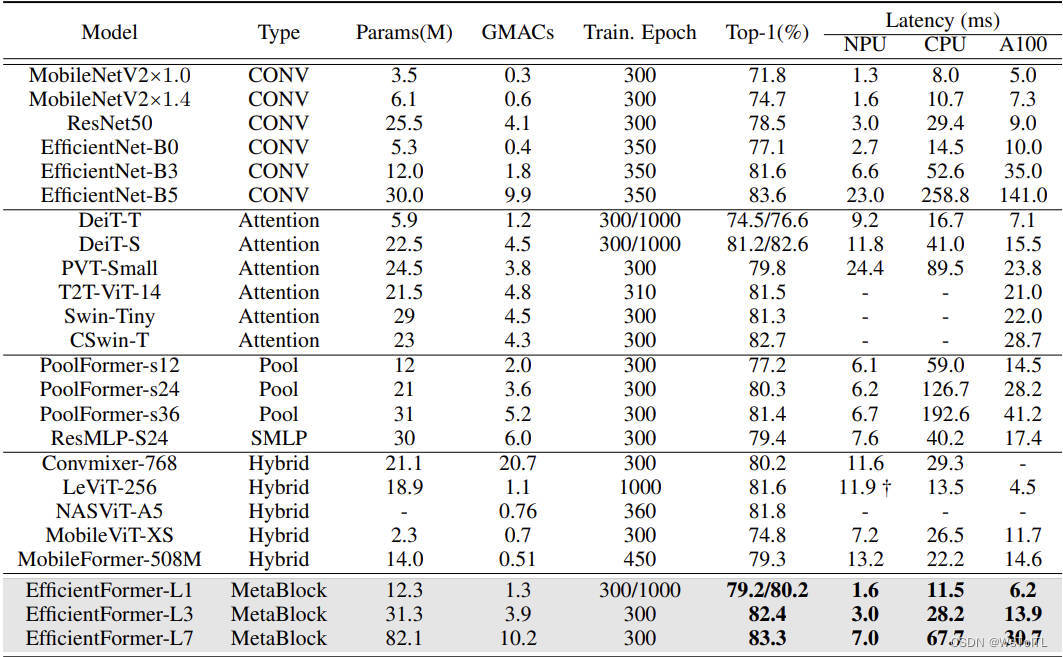
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4494
4494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









