










Lecture 14主要讲解了强化学习的相关知识,主要介绍了马尔科夫决策过程、Q-learning、策略梯度和Actor-Critic Algorithm等。

我们在这里有一个代理,能够在其环境中采取行动,也可以为其行动获得奖励。目标是学会如何采取行动,以最大化获得奖励。
文章目录
What is reinforcement learning?
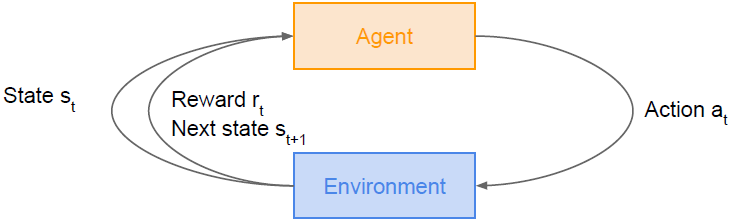
在强化学习中我们有一个代理和一个环境,环境赋予代理一个状态,反过来代理将采取行动,然后环境反馈一个奖励;不断重复这个过程,直到环境给出一个终端状态结束这个环节。
Examples
-
车载立柱问题

-
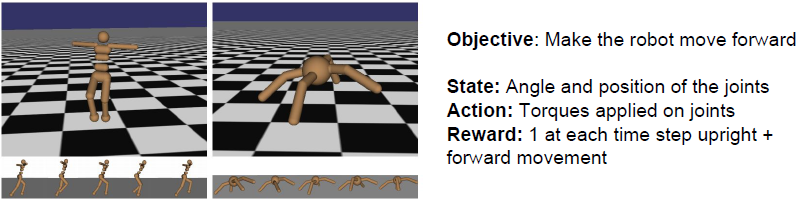
机器人运动
-
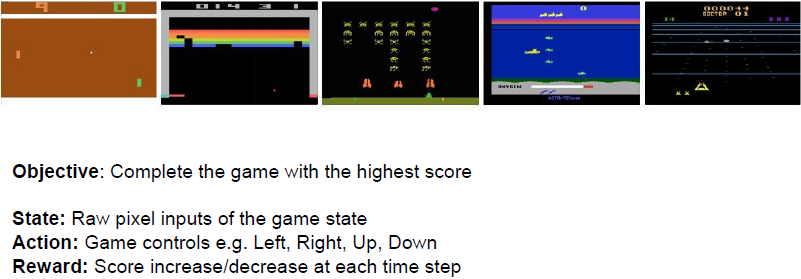
游戏
-
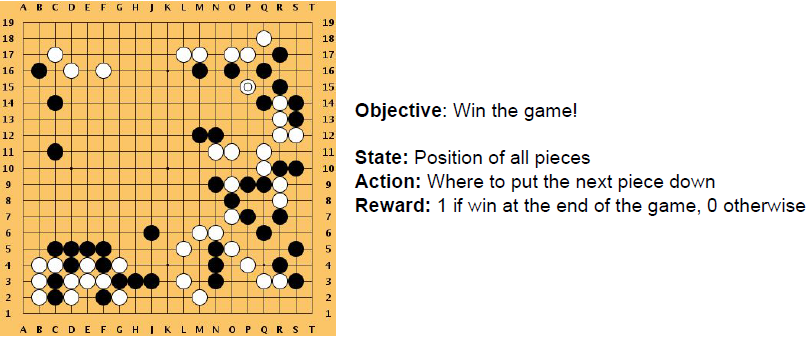
围棋
Markov Decision Process
如何用数学语言来描述强化学习。

马尔科夫决策过程(Markov Decision Process,以下简称MDP)就是强化学习问题的数学表达,马尔科夫决策过程满足Markov性,即当前状态完全刻画了全局状态。
MDP由一组对象定义,这个对象元组中有S,也就是所有可能状态的集合;A是所有行动的集合;R是奖励的分布函数,给定一个状态,一组行动,它就是一个从状态行为到奖励的函数映射;P表示下一个状态的转移概率分布,是给定一个状态-行为组合将采取的行动; γ \gamma γ是折扣因子,它对近期奖励以及远期奖励分配权重。

马尔科夫决策过程的工作方式:令我们的初始时间步骤t=0,然后环境会从初始状态分布P(s)中采样,并将一些初始状态设为0。然后从t=0直到完成,我们将遍历整个循环,代理将选择一个动作
a
t
a_t
at,环境将从这里获得奖励,也就是在给定状态及刚刚采取的行动的条件下所获得的奖励,这也是抽样下一个状态在时间t+1给定的概率分布。然后代理将收到奖励,进入下一个状态。继续整个过程,再次循环,选择下一个动作。
基于上述步骤,我们可以定义一个策略 π \pi π,它是一个从状态到行为的函数,它指定了在每个状态下要采取的行动,这可以是确定的也可以是随机的,现在的目标是找到最佳决策 π ∗ \pi^* π∗,最大限度提高你的配权之后的全部奖励之和。
A simple example:
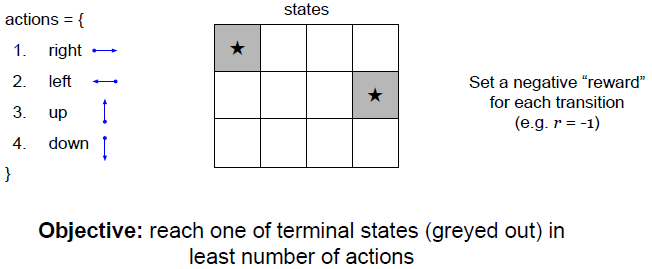
这里有一个网格,里面有网格任务的状态,根据状态采取行动,这些行动都很简单,即向上下左右移动一步,每次行动都会得到一个负奖励,也就是r=-1,目标是用最少的行动到达灰色网格中。

这里有一个随机策略,随机策略包含在每一个单元格中,要做的只是随机抽样将要移动的方向,所有方向都有相同的概率。我们希望拥有最优的策略,采用最少的步骤到达目标单元格。
如何寻找最优策略呢,使用Q-learning方法。
Q-learning
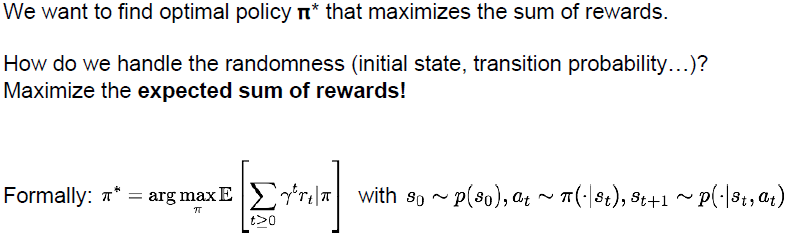
我们的目的是找出最佳策略
π
∗
\pi^*
π∗,最大化策略能够最大化奖励总和。最佳策略
π
∗
\pi^*
π∗所提供的信息是在任意给定的状态下,我们应该采取怎样的行动来最大化我们得到的奖励。
问题是如何处理MDP中的随机性,初始状态的抽样,转移概率分布都是随机的。转移概率分布会给出下一个状态的分布。我们要做的是最大化预期的奖励总和,最优的策略 π ∗ \pi^* π∗是未来奖励决策的预期总和最大化时所取的 π \pi π。我们有初始状态,它采样于状态分布,我们还有行为,这些行为是根据我们的决策和给定的状态采样的,然后我们从转移概率分布中抽取下一个状态。
Value函数和Q-Value函数

当我们遵循某一个策略时,每次迭代都要采样一组行为轨迹,并且我们把初始状态设为
s
0
s_0
s0,
a
0
a_0
a0,
r
0
r_0
r0,
s
1
s_1
s1,
a
1
a_1
a1,
r
1
r_1
r1…这样我们会得到状态、行动和奖励的轨迹。
那么如何评判我们目前所处的状态好坏?状态s的价值函数指的是从当前状态开始,遵循当前策略,所得到的期望累积奖励。
一个状态-行动组合有多好?在状态s时采取行动a有多好?我们用一个Q值函数来定义这个问题,遵循决策的期望累计奖励,这个函数表示在状态s下采取行动a所得到的期望累积奖励。
Bellman equation
在上节我们介绍了Value Function价值函数,所以为了解决增强学习的问题,一个显而易见的做法就是估算Value Function。

Q
∗
Q^*
Q∗为最优Q值函数,这是我们从给定的状态动-作组合下得到的最大期望累积奖励,它的定义如图第一个式子。
Bellman等式(可参考此链接):
这个Q值函数的最优策略
Q
∗
Q^*
Q∗,最优策略
Q
∗
Q^*
Q∗要满足Bellman等式,它的定义是图中第二个式子。
Q
∗
(
s
′
,
a
′
)
Q^*(s',a')
Q∗(s′,a′)是下一时间步的最优值函数,那么最优策略是采取使得
r
+
γ
Q
∗
(
s
′
,
a
′
)
r+\gamma Q^*(s',a')
r+γQ∗(s′,a′)期望最大化的动作。
既然我们知道了最佳决策,也知道要在 s ′ s' s′状态下执行我们能做的最好的行动,那么在状态 s ′ s' s′上的值就会成为我们行动上的最大值, Q ∗ Q^* Q∗在 s ′ s' s′状态下的 a ′ a' a′。然后我们可以得到最佳Q值的表达式。
我们的最优策略是在任何状态下按照具体的 Q ∗ Q^* Q∗采取最好的行动, Q ∗ Q^* Q∗告诉我们采取某一行动会带来最多的奖励。
Solving for the optimal policy
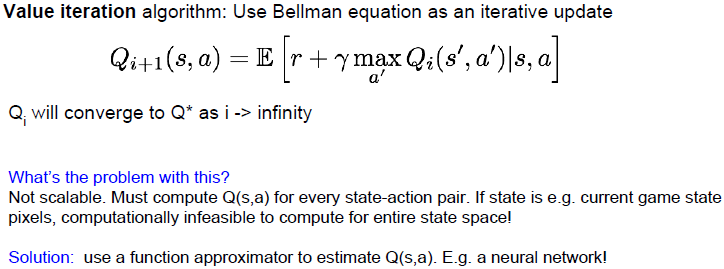
如何求解这个最佳策略?一种常用方法是值迭代算法。我们通过Bellman方程作为迭代更新,在每一步中我们试图强化Bellman方程来改进我们对
Q
∗
Q^*
Q∗的近似。在
i
i
i趋近于无穷时
Q
i
Q_i
Qi将收敛于
Q
∗
Q^*
Q∗。
但这个解决方法不可扩展,我们必须计算每个状态-动作组合的s值,以便进行迭代更新。这就存在一个问题,例如前面提到的游戏,状态是像素,这是一个巨大的状态空间,去计算整个状态空间是不可行的。我们可以使用函数逼近器(例如神经网络)去估计Q(s,a)。
(如前几课一直说的,如果我们要估计一些真正的不知道的复杂函数,那么神经网络就是一个很好的估计方法。)
Q-learning

如上所述,计算整个状态空间不可行,我们可以使用函数逼近器(例如神经网络)去估计Q(s,a)。
我们用函数逼近器来估计我们的动作值函数,这个函数逼近器是深度神经网络,被称为深度Q学习,这是深度强化学习常用的方法。
我们有函数的参数 θ \theta θ,Q值函数由我们神经网络的这些权重 θ \theta θ决定。

给出函数近似,如何求解最优策略?找一个满足Bellman方程的Q函数,我们想强制使这个Bellman方程成立,我们用神经网络逼近Q函数时,可以尝试训练这个损失函数并最小化Bellman方程的误差或s,a离目标的距离。
用这些损失函数的前向传播来最小化这个误差,然后反向传播更新梯度。我们的目标是产生使Q函数更接近我们目标值的效果。
Example
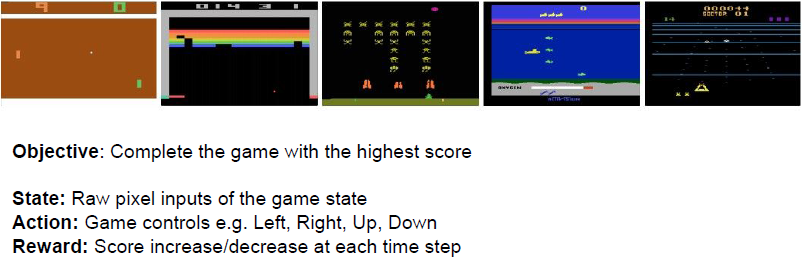
我们的目标是以最高的分数完成游戏,我们的状态是游戏状态的原始像素输入。
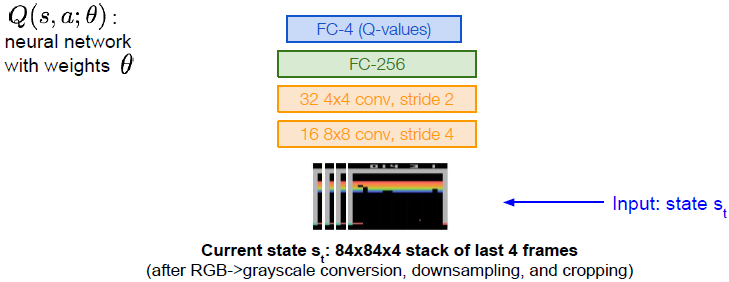
Q函数网络如上图所示,是一种带有权重
θ
\theta
θ的Q网络。输入状态s是现在游戏画面的像素(历史记录中的4帧图像),做灰度转换、下采样及剪切等预处理,最终得到
84
×
84
×
4
84\times84\times4
84×84×4的最后四帧图像作为输入。
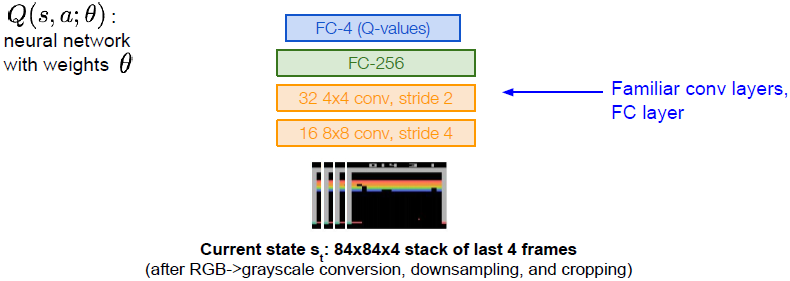
网络中有卷积层,全连接层。
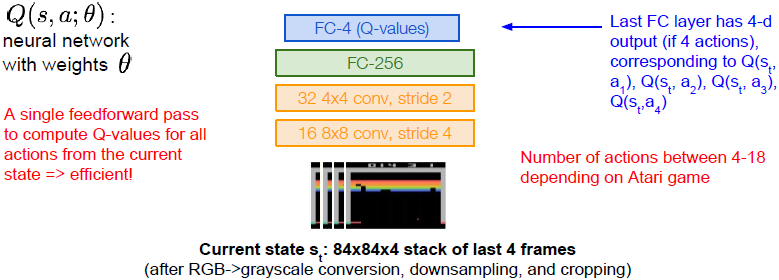
最后一个全连接层有一个输出向量,对应于给定输入状态时每个动作的Q值,对应于当前s的Q及
a
1
、
a
2
、
a
3
、
a
4
a_1、a_2、a_3、a_4
a1、a2、a3、a4(假设有四个动作)。
使用这个网络结构通过一次前向传播就能够根据当前状态计算出所有Q值。基本上我们采用当前的状态,然后将每个动作的输出或每个动作的Q值作为我们的输出层。
Example:training process(Loss function)

训练时我们使用之前的损失函数,试图执行Bellman方程,所以在前向传播中我们反复使用损失函数使Q值达到他的目标值;反向传播直接获取这个损失函数的梯度,采取梯度下降。
Example:training process(Experience Replay)

用刚刚讲的采用两个简单网络的方法从连续样本中学习的效果并不好,因为游戏进行的时候状态、动作、奖励是连续采样的,我们再用这些连续样本训练,所有这些样本都是相关的,这就导致了低效的学习。所以我们现在的Q网络参数决定了我们将要遵循的决策,决策决定了下一个要用于训练的样本,这会导致不好的反馈循环。例如:如果当前最大化的行动是向左,那么这将使所有即将到来的训练样本偏向于向左的样本。解决的方法就是经验重放,这里我们要保持这个状态转换的重放记忆表,如状态、行为、奖励、下一个状态,我们在游戏中不断获得新的转换,当我们有了经验就可以不断更新这个表格。现在我们可以做的是训练Q网络,从回放记忆中取出一个小批量的转移样本,所以现在我们不是使用连续的样本,而是通过这些过渡样本进行样本抽样。这样做的另一个好处是每个状态转移样本都可能对多次权重更新起作用,我们可以从表格中多次进行数据抽样,这样可以带来更高的数据效率。
Deep Q-Learning with Experience Replay

首先将replay记忆初始化,来选择某个容量N,然后利用我们的随机权重或初始化权重初始化Q网络。

接下来会进行M次迭代或者完整的游戏(训练过程)。

接着利用每次游戏开始的画面(预处理后)的像素初始化我们的状态。


然后在游戏进行的每一步,以一个小概率选择一个随机动作,要确保充分探索动作空间,我们要确保抽样状态空间的不同部分,否则将从当前决策的贪婪行为中进行选择,大多数情况下我们会采取贪婪行为(
a
t
=
arg
max
a
Q
∗
(
ϕ
(
s
t
)
,
a
;
θ
)
a_t=\arg\max_aQ^*(\phi(s_t),a;\theta)
at=argmaxaQ∗(ϕ(st),a;θ)),并将它视作下一步行动的较好的策略。

接着采取行动
a
t
a_t
at,观察下一个奖励
r
t
r_t
rt和下一个状态
s
t
+
1
s_{t+1}
st+1。

然后把这个转换存储在我们正在构建的replay内存中。

接着一点点训练网络,我们要执行experience replay,从replay内存中抽取一个随机小批量的过渡样本,然后执行一个梯度下降步骤。(连续玩游戏,抽取小批量,使用经历过的回放来更新我们的Q网络的权重)。
Policy Gradients

Q-learning存在的问题是Q函数非常复杂,我们要学习每个状态-行动组合的值。例如让机器人抓住一个东西,将会有一个非常高维度的状态,此时会拥有所有的关节、关节位置和角度,所以学习每个状态-行动组合的确切的值是很难做到的。但另一个方面,你的策略可能很简单,比如你希望机器人去做的可能仅仅是一个简单的动作(如握手),那么我们能否直接学习这个策略?即从一系列策略中找到最好的策略,而不是通过评估Q值的过程,然后用它来推断策略。

我们定义一类参数化策略,通过权重
θ
\theta
θ进行参数化,对每个策略我们都定义了策略的价值,对于给定的
θ
\theta
θ,
J
J
J就是未来奖励累计总和的期望。我们的目标是找到一个最佳策略
θ
∗
\theta^*
θ∗,使得
J
(
θ
)
J(\theta)
J(θ)的值最大。即我们的目标是找出最佳策略参数,这个策略参数可以得到最好的期望奖励。
如何实现这一想法:对策略参数进行梯度评价,给定一些已有目标,一些可以用于梯度下降和一些可以用来实行梯度上升的参数。
Reinforce Algorithm
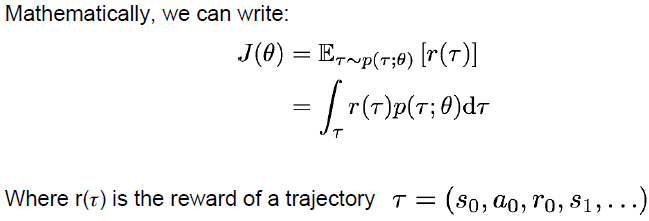
在数学上写出对轨迹的未来奖励的期望,我们要抽取这些经验轨迹,就像我们前面提到的游戏中
s
0
、
a
0
、
r
0
、
s
1
.
.
.
.
.
.
s_0、a_0、r_0、s_1......
s0、a0、r0、s1......,使用
θ
\theta
θ的一些策略
π
\pi
π,然后对每一个轨迹都可以计算该轨迹的奖励,这是我们从这个轨迹获得的累积奖励,这些轨迹是从我们的策略中采样的。

现在来做梯度上升,此时求期望的梯度是困难的,因为p依赖于
θ
\theta
θ。我们想要得到给定
θ
\theta
θ时p和
τ
\tau
τ的梯度,这就要求对
τ
\tau
τ进行积分,很难求解。
技巧:我们想要的梯度p可以转化成对数的梯度,如图所示。然后把式子带入之前的梯度表达式,现在有了 log p \log p logp梯度乘以所有轨迹的概率,然后对 τ \tau τ进行积分,就得到一个对轨迹 τ \tau τ的期望。上述所做的已经对期望值求了梯度,并转化为梯度的期望,现在我们可以用得到的样本轨迹来估计我们的梯度(我们采用蒙特卡洛抽样来做,这是强化学习的核心思想)。

我们可以在不知道转移概率的条件下计算这些量吗?
p ( τ ; θ ) p(\tau;\theta) p(τ;θ):我们可以得到 p ( τ ; θ ) p(\tau;\theta) p(τ;θ)为一个轨迹的概率,这将是所有得到的下一个状态的转移概率和给定状态-行为的乘积,以及在策略 π \pi π下采取行动的概率。把所有这些乘在一起就得到了轨迹的概率。
log ( τ ; θ ) \log(\tau;\theta) log(τ;θ):对 p ( τ ; θ ) p(\tau;\theta) p(τ;θ)取对数,将累乘化为累加。然后 log ( τ ; θ ) \log(\tau;\theta) log(τ;θ)对参数 θ \theta θ进行求导,式子的第二项才有参数 θ \theta θ,我们可以看到这不依赖转换概率,所以我们不需要转换概率来进行梯度估计。
然后对任意给定的轨迹 τ \tau τ进行采样,可以利用这个梯度估算 J ( θ ) J(\theta) J(θ)。式子展示的是单轨迹,也可以在多个轨迹上进行采样以得到期望值。
存在的问题:

给定了这个梯度估计值我们就可以得出,如果我们对轨迹的奖励很高,那就提高这一轨迹中的一系列行动的概率;如果奖励低,那就视为不好的行动,降低概率。给定s,我们有
π
(
a
)
\pi(a)
π(a),这是已经采取行动的似然值,然后缩放这一项,取得导数后得到梯度,梯度告诉我们应该对参数调节多少才能增加行动的似然值,然后我们通过从中得到的奖励来缩放该式子。
如果轨迹是好的我们就可以说它的所有行动都是好的,但从期望的角度它实际是一个平均值,所以这里我们有一个无偏估计量。如果你有很多的样本,我们就可以得到梯度的准确估计,因为我们可以采取求导步骤这有利于改善我们的损失函数,并越来越接近我们的策略参数θ的局部最优解。
但是它也具有大的方差值,这个置信分配很难,我们认为给定奖励即认为所有行动是好的,我们希望分配的行动能是实际上最好的行动,重要的是对时间求平均。我们需要大量样本才能有一个好的估计。我们可以做什么来减少方差提高估计量?
Variance reduction

减少方差是决策梯度一个重要的研究领域,并提出了改进估计量和减少样本数量的方法。
给定梯度估计量:
-
第一个想法是可以通过影响来自该状态的未来奖励来提高行为的概率。现在不用对似然值进行放缩或通过轨迹的总奖励增加行动的似然值。我们来更具体地看一下从时间步骤到最后的奖励总和。通常我们说一个行动有多好,仅仅通过它产生多少未来奖励来确定,这是有道理的;
-
第二个想法是使用折扣因子来忽略延迟效应。折扣因子告诉我们有多关心即将获得的奖励而不是比较晚的奖励。现在评价一个行动好不好更多的关注他在不久的将来产生的状态-行动组合,并降低晚一点发生的行为的权重。-
Variance reduction: Baseline

第三个想法是使用基线来减少方差。仅使用轨迹的原始值存在问题在于这不一定是有意义的。例如奖励都是正的,那么只是不断增加所有行为的可能性,而真正重要的是奖励与你期望的相比更好还是更差。为了解决这个问题我们可以引入一个依赖于状态的基线函数,基线函数告诉我们我们的猜测是什么,我们期望从这个状态得到什么,然后用以增加或降低我们的概率的奖励或缩放因子,等于未来奖励的期望减去基线,所以它是我们预期得到的奖励与真实奖励的相对关系。
How to choose the baseline?
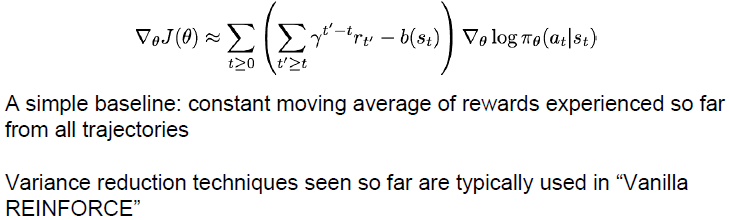
最简单的是获取目前为止所获得的奖励的滑动平均值。

要选择一个好的基线,我们要做的是提高一个已知状态的行动的概率,只要这个行动好于我们应从那个状态得到的期望值。我们对状态的期望值是什么:Q方程和价值函数。我们对一个行动满意,在一个状态s下采取行动,如果在这个状态下采取一个指定行动的Q值的结果比价值函数(从该状态中得到的累积未来奖励)的期望值要高,意味着这个行动比其他行动要好。
如果把我们的行为概率作为想要增加或降低的缩放因子,我们会得到一个估计量,在我们有了累积期望奖励之前,我们有各种减少方差的技术和基准,我们现在插入这种衡量当前行为好坏的差异,这个差异等于我们的Q函数减去该状态下的价值函数。
Actor-Critic Algorithm

到目前为止我们谈论的增强学习算法都不知道Q和V究竟是多少,我们可以学习到Q和V吗?答案时肯定的,使用Q学习。
我们可以通过训练一个角色,结合决策梯度和Q-learning(Q是策略也是评价),Q方程告诉我们我们认为的一个状态有多好及一个状态中的行动有多好。然后角色将决定采取哪一种行动然后评价或Q函数告诉角色其行动怎么样以及如何调整。相对Q-learning而言,这样也减轻了一点评价任务。我们前面提到的Q-learning问题必须有这个学习的每个状态和行动组的Q值,而现在它只需要这个策略产生的状态行动组,它只需知道这对缩放因子的计算很重要。可以将之前所有的Q-learning技巧配合起来。
优势函数:表示给定状态下一个行为有多好。Q(s,a)减去V(s),我们对状态评价的期望值是通过这个优势函数得到的。优势函数是我们从这个动作中得到多少优势,动作比预期好多少。

通过这个算法,我们可以将角色-评价算法集成起来。首先初始化我们的策略参数
θ
\theta
θ,和评价参数
ϕ
\phi
ϕ。然后对每一次训练的迭代我们将在当前策略下采样M个轨迹,将采用我们的策略并得到这些轨迹为
s
0
,
a
0
,
r
0
,
s
1
s_0,a_0,r_0,s_1
s0,a0,r0,s1等。然后我们计算我们想要的梯度,对每一个轨迹和每一个时间步骤我们都将计算其优势函数,接着使用优势函数将它们用于我们之前讨论过的梯度估计并累加起来。然后我们将训练我们的评价参数
ϕ
\phi
ϕ,方法相同,基本上也是增强这个价值函数来学习我们的价值函数,使这个优势函数最小化,这将促使它更接近我们看到的Bellman方程。然后,在学习和优化策略函数间以及评价方程之间进行迭代,接着更新梯度。不断重复这个过程。
Examples
循环聚焦模式

目标是预测图片的类别,通过图片中一系列微景来实现。你会看到图像周围的局部区域,你基本上将有选择地集中在这些部分周围观察来建立信息。我们这么做的原因,首先它是从人类感知中的眼睛运动获得的一些灵感,比如我们在看一张复杂的图像,我们要确定图像中的内容,我们也许可以首先低分辨率地看见它,然后只看图像的某些部分,这些部分线索可以勾勒出这个图的内容。然后,针对局部区域观察,环视这幅图有助于节约计算资源。这也有助于图像分类,因为你可以忽略图片中混乱和一堆不相关的信息。
状态:当前看到的微景;
动作:下一步看向图片的哪一部分(x,y坐标);
奖励:最后的时间步如果分类正确就是1否则为0;
因为得到微景是一个不可导的操作,所以要使用强化学习,学习如何采用这些视觉动作的策略。给定微景状态,RNN对这个状态建模,使用策略参数输出下一个动作。
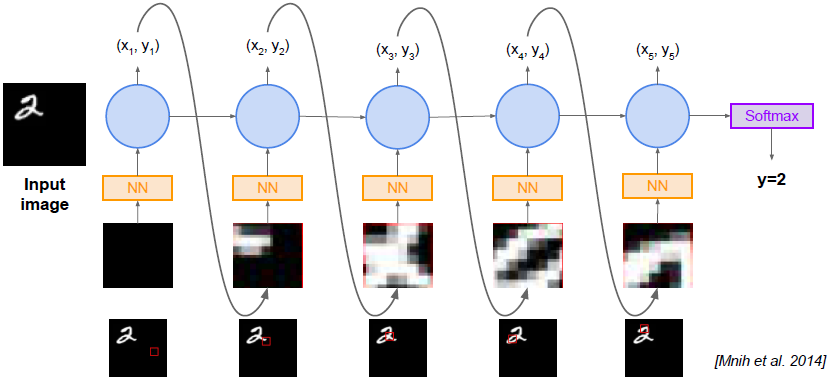
输入一张图片,然后观察,观察位置就是框出来的位置,框内此时观察的值全部为0。然后将看到的传给网络。
传入网络后,我们将结合我们的状态和观察的历史,使用一个循环网络,输出我们下一步观察位置的x,y坐标。我们的输出实际上是一个行动的高斯分布,输出行动的均值和方差。
根据行动的分布,抽取一个特定的x,y坐标采样作为输入,并得到下一个图片中的观察点。利用该输入和之前的隐藏态,循环神经网络得到策略a。然后利用a得到下一个观察位置。
在最后一步,如果是分类问题,会设置softmax层,对每一个类产生一个概率分布,此时推断最大可能是2。
Alpha Go

输入:棋盘上的特征(棋子位置等);
给定状态后开始训练网络,职业棋手监督训练初始化。给定很多比赛棋局,训练一个从当前棋局状态到下一步往哪走的监督图谱。用决策图谱初始化一个决策网络。利用决策梯度训练决策网络,网络与之前随机的棋局对弈,执行强化学习。赢了奖励+1,输了奖励-1。学习一个价值网络,类似于一个评价者。
AlphaGo将决策网络、价值网络、蒙特卡洛搜索结合起来选择下一步的走棋。通过前向搜索来选择下一步走棋。这些集成在一起后,妻子在一个节点的价值和下一步棋一起构成了你的价值方程,并构成了标准蒙特卡洛树搜索计算的输出。
Summary

本博客与https://xuyunkun.com同步更新















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









