







引言
在上篇文章cs231n 2023春季课程理解——lecture_13中,我们简单地介绍了自监督学习,了解了两种实现自监督学习的方式以及这两种方式的实现。在这篇文章中,将对强化学习进行简要地介绍。
强化学习
什么是强化学习
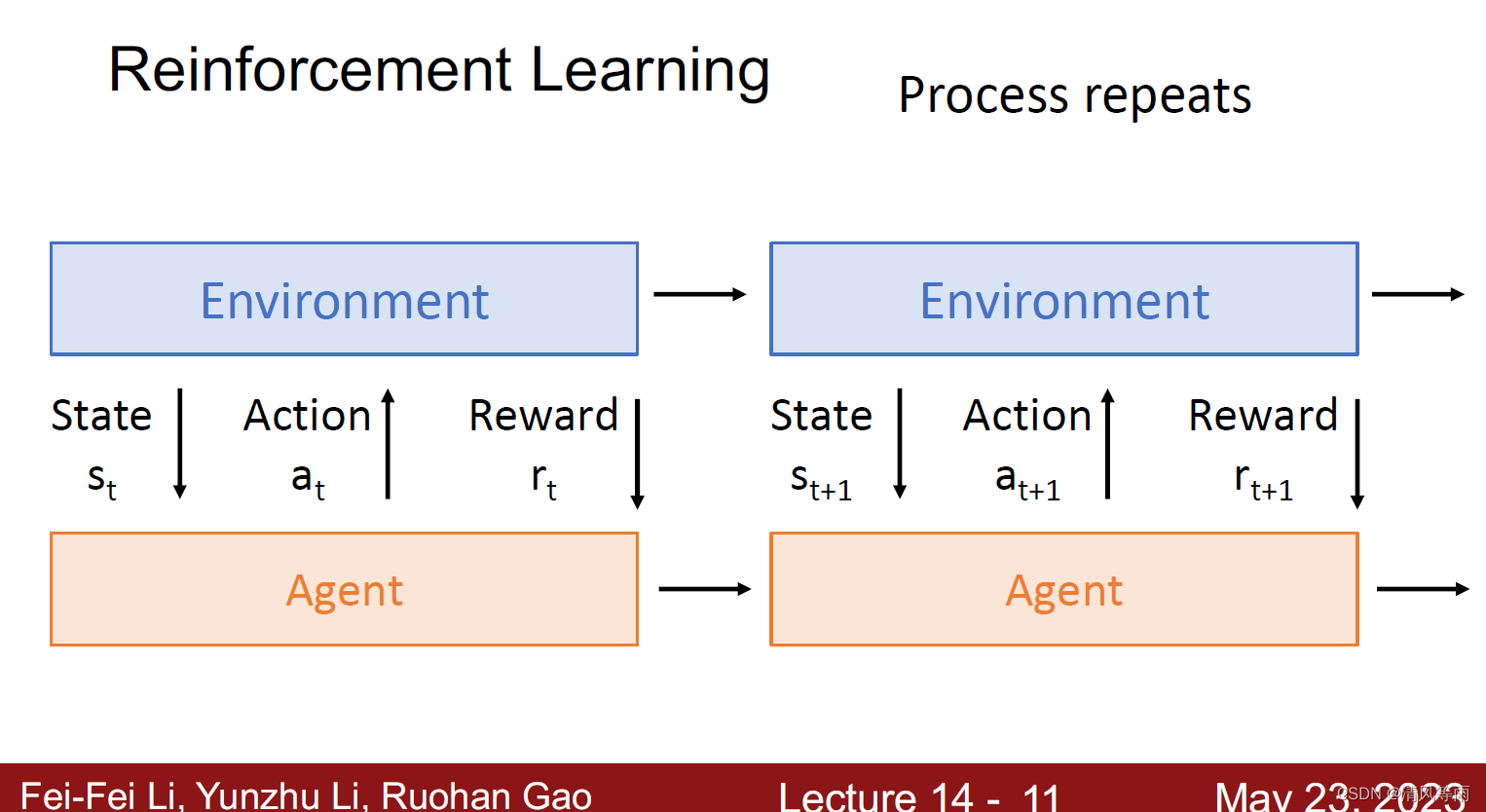
首先,先简单地介绍一下强化学习。强化学习,简单地说,就是一种学习如何从状态映射到行为,以使得获取的奖励最大的学习机制。即它(agent)基于环境的反馈而行动,通过不断与环境的交互、试错,最终完成特定目的或者使得整体行动收益最大化。强化学习不需要训练数据的标签,但是需要根据环境给予的反馈,来指导训练对象每一步该如何决策,采用什么样的行动可以完成特定的目的或者使收益最大化(如下图)。
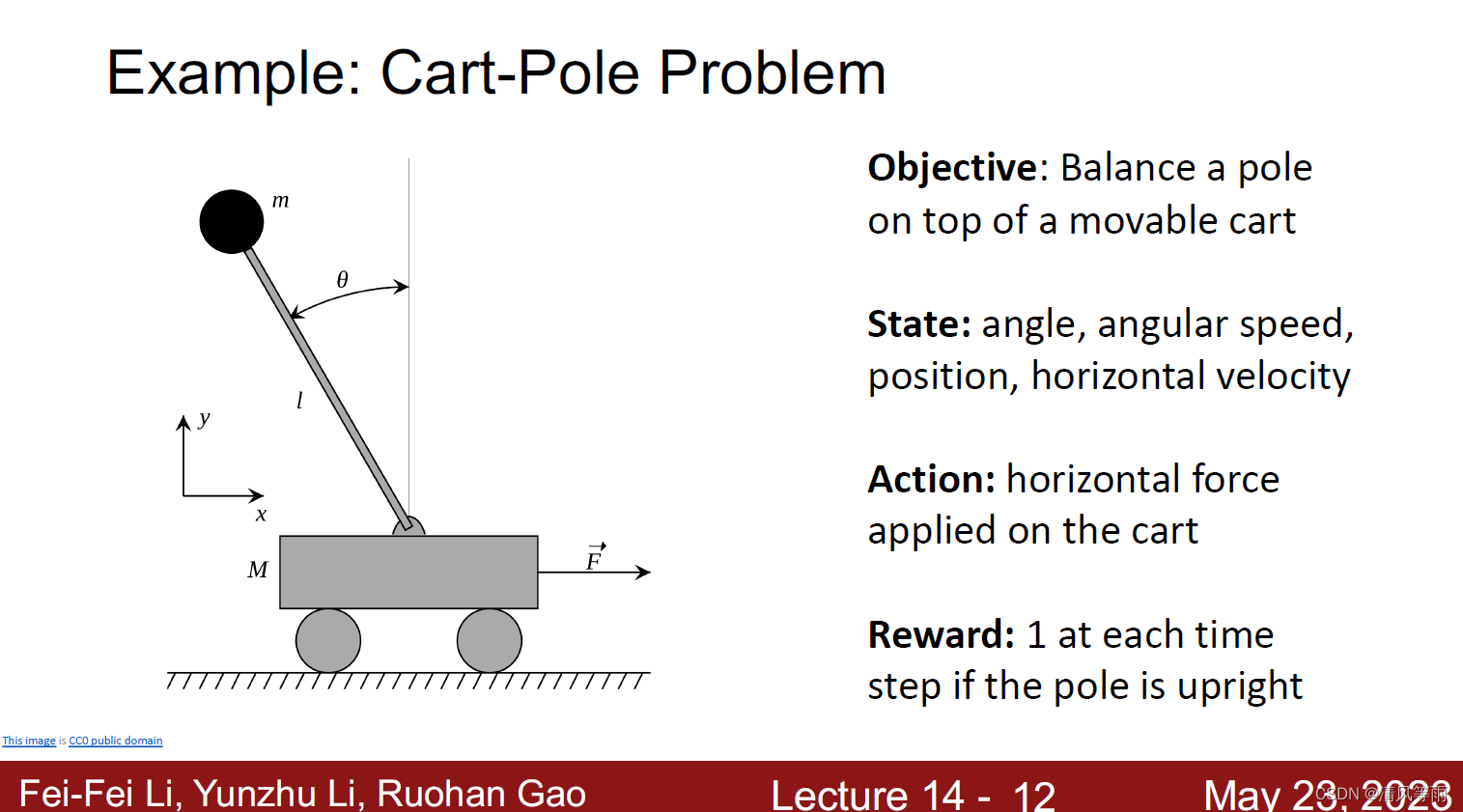
接下来我们来看一些例子,第一个例子为推车杆问题(Cart-Pole Problem),如下图所示。这个问题的目标是让杆在可移动的车子上保持平衡,那么它当前的状态就是对当前系统的一个描述(环境所给的状态),例如,角度,角速度等,可采取的措施是你施加在车上的一个横向力。因此,基本上是通过来回移动小车来保持杆的平衡,只要保持杆平衡(向上),那么每一次都会从环境中得到奖励(1,表示当前杆平衡)。
另一个经典的强化学习的例子是关于机器人运动的,如下图所示。我们的目标是让机器人向前移动,对系统的描述是机器人的各个关节的角度以及位置等(也就是环境给予agent的状态),可执行的动作就是施加到这些关节上的力。这样就可以尝试让机器人向前移动,并得到奖励(奖励是向前移动的距离)。

除了上面的两个强化学习例子之外,还有游戏中也可以应用(比如说之前好像王者荣耀的团队将强化学习成功的应用在王者荣耀里面)、下围棋(著名的例子就是AlphaGo)。
强化学习与监督学习
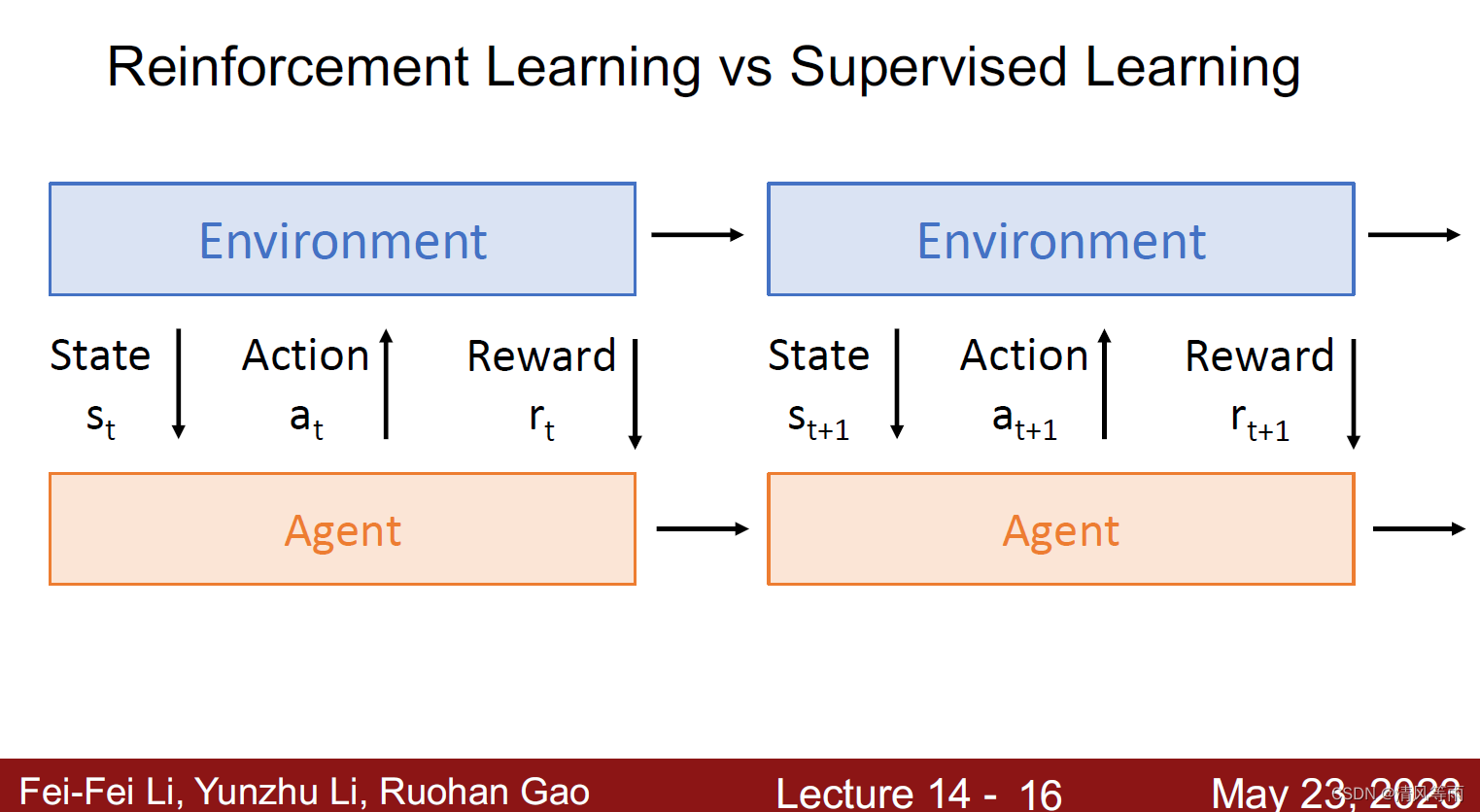
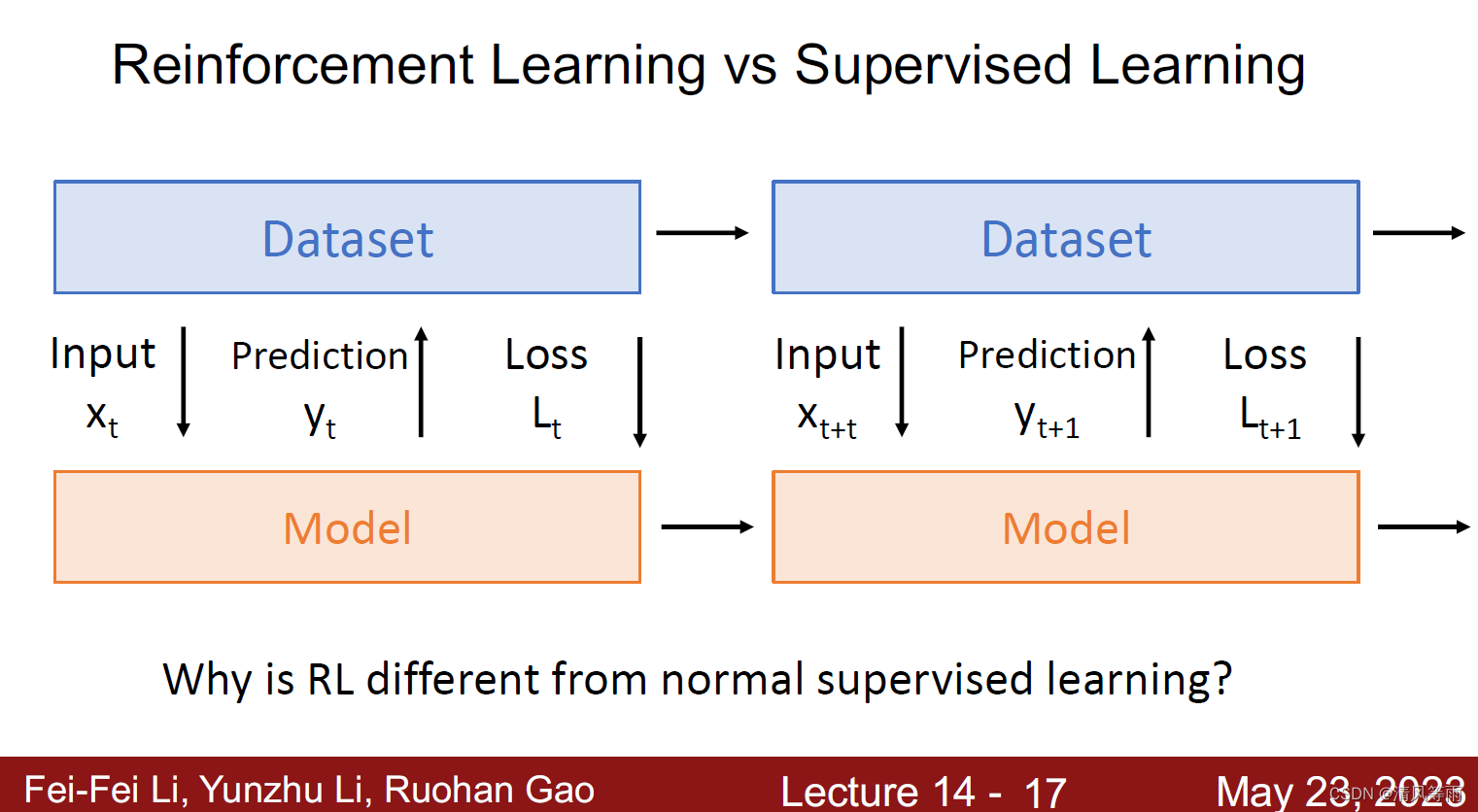
如上面两张图所示,强化学习与一般的监督学习有什么不同呢?首先,在强化学习中,环境给予智体(agent)的状态(也可以认为是对智体的输入)以及奖励是随机的,而监督学习则是在特定的输入。其次,奖励
r
t
r_t
rt可能并不直接依赖于动作
a
t
a_t
at,监督学习中的损失则与输出有直接依赖关系(输出与输入越相近,损失越小)。强化学习是不可微以及不稳定的(智体的表现依赖于它如何进行动作)。
马尔科夫决策过程(Markov Decision Process, MDP)
那么,我们该如何在数学上用公式表示强化学习呢,一个最常用的方式是使用马尔科夫决策过程。马尔科夫决策过程如下图所示,它满足了马尔科夫特性(Markov Property),即当前状态能完全表示世界的状态,奖励和下一个环境状态完仅赖于当前状态,而不是历史状态。MDP有一组对象来定义,这组对象分别为
S
,
A
,
R
,
P
,
γ
S, A, R, P, \gamma
S,A,R,P,γ,其中
S
S
S表示所有可能得状态,
A
A
A表示所有可能得动作,
R
R
R表示奖励的分布(通过状态和动作来确定),
P
P
P表示下一个动作转移分布的概率,
γ
\gamma
γ是折扣因子,用于分配现在和未来的奖励的权重。

MDP的流程如下:首先令初始时间步骤t等于0,此时环境会从初始分布状态p(s)中采样,并将一些初始状态设置为0。然后从t=0开始,一直到完成,将一直循环一些步骤,分别为,智体选择一个动作
a
t
a_t
at,环境将从这个动作中给智体奖励(或者说回馈)
r
t
r_t
rt,环境给智体一个新的状态
s
t
+
1
s_{t+1}
st+1,智体接收奖励
r
t
r_t
rt和新状态
s
t
+
1
s_{t+1}
st+1

Q-Learning
下面将展示价值函数与Q函数的公式(通过这两个函数,就能知道当前状态的最佳决策,从而采取最有利的行动):


上面说到只要寻找到最佳的策略就可以采取最好的行动,那么如何找到最佳的策略呢,一个比较常见的方法就是值迭代法。如下图所示,每一步都试图去强化Bellman函数来改进对Q*的值。但这种方法它不可以扩展,我们必须计算每个(动作,状态)对的值,以便进行迭代更新。但这在复杂情况下是不可行的(如游戏中,一个大分辨率的图像上)。一个解决方法是使用神经网络来近视获得Q的值。

Deep Q-Learning

Deep Q-Learning 如上图所示,通过像原始的Q函数中添加一个权重
θ
\theta
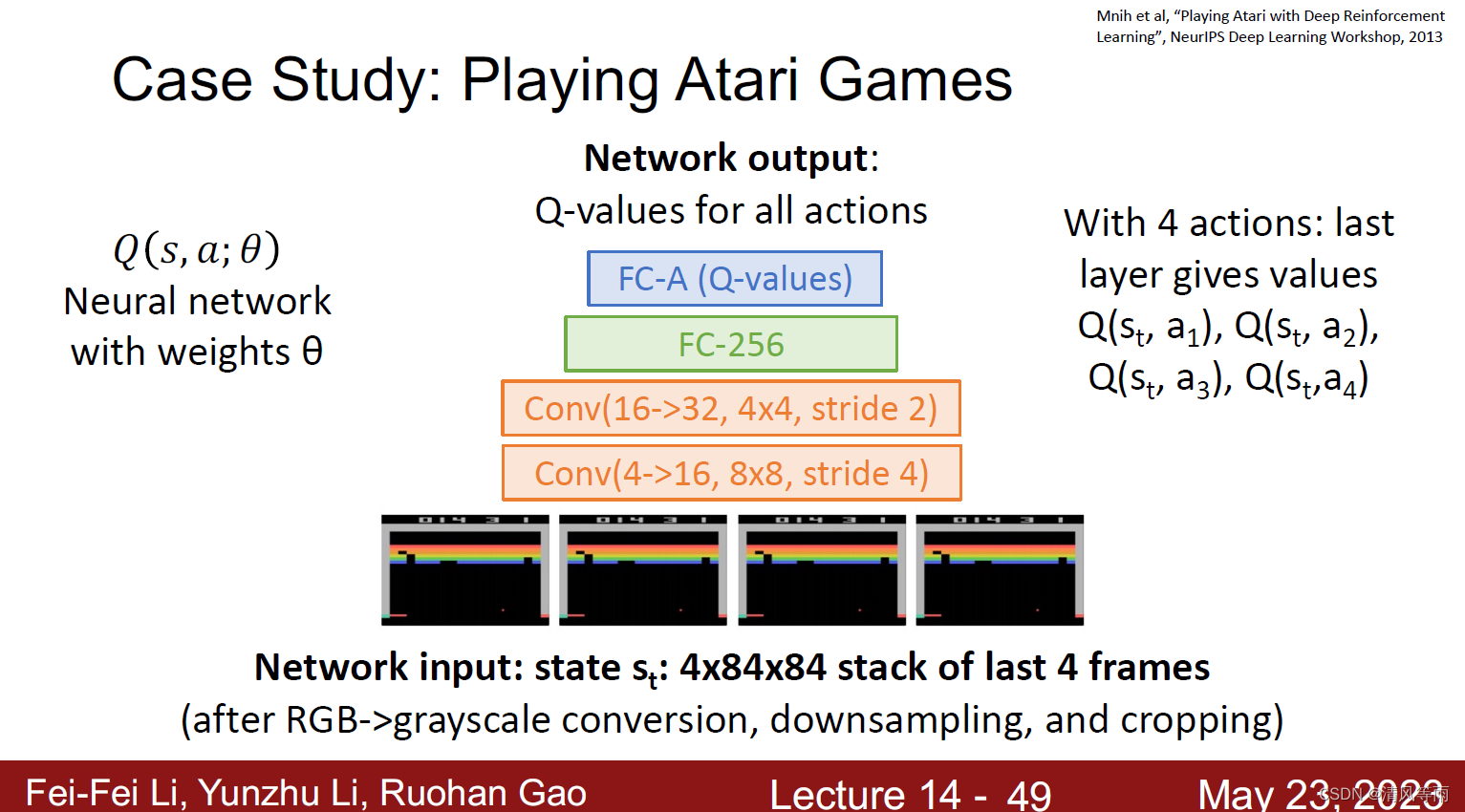
θ,重新寻找Q函数,使得其成立。为了使得其成立,需要找到一个损失函数L(s,a)(如上图)以此来最小化误差。其一个网络架构如下图所示:
Policy Gradients
Q-Learning中,对于有些问题,确定Q函数是比较苦难的。因此,可以使用一种更加简单的方法,那就是策略梯度(Policy Gradients)。策略梯度通过更新 策略网络来直接更新策略。策略网络是一个神经网络,输入是状态,输出直接就是动作,且一般输出有两种方式,输出一个动作的概率或者是直接输出一个动作。其公式的梯度计算如下图所示:







其流程如下图所示:


总结
本篇文章简单介绍了一下强化学习,以及一些相应的算法,各个算法的具体内容,仍需自己再详细了解。
注
本文所有图片均来自于cs231公开课的网站之中。















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









