









文章目录
Abstract
Lecture 1主要是对强化学习整体的一个简单介绍,描述了强化学习的概念,有哪些组成部分,能够解决什么问题,RL框架有哪些类别等。在这一讲中我们仅需要对强化学习有一个大概的认识即可。
1. 强化学习的特点
强化学习不同于监督式学习与非监督式学习:
- 强化学习训练时不存在监督者,只有奖励信号;
- 反馈结果是滞后的,不是实时得到的;
- 数据是具有时序性的,不是独立同分布(IID)的;
- Agent 的动作会影响到之后所获取到的数据,即这是一种主动学习过程。
强化学习的应用广泛:如直升机特技飞行、经典游戏、投资管理、发电站控制、让双足机器人行走等。
2. 强化学习的组成要素
2.1 Reward(奖励)
强化学习中最重要的信息之一就是Reward。
- Reward R t R_t Rt 是一个标量反馈信号;
- Reward 告诉我们Agent 在第 t 步做的怎么样;
- Agent 的工作是最大化累计Reward。
强化学习是基于”奖励假设”的:所有问题解决的目标都可以被描述成最大化预期累积奖励。
Sequential Decision Making
- 强化学习框架的目标是通过选择不同的动作以实现最大化总的未来奖励;
- 动作所产生的结果可能是长期性的;
- 动作所获得的奖励可能是滞后的;
- 为了获得更多的长期奖励,可能需要放弃眼前的即时奖励。
2.2 Agent(智能体)与 Environment(环境)
Agent与environment间的交互关系如下所示
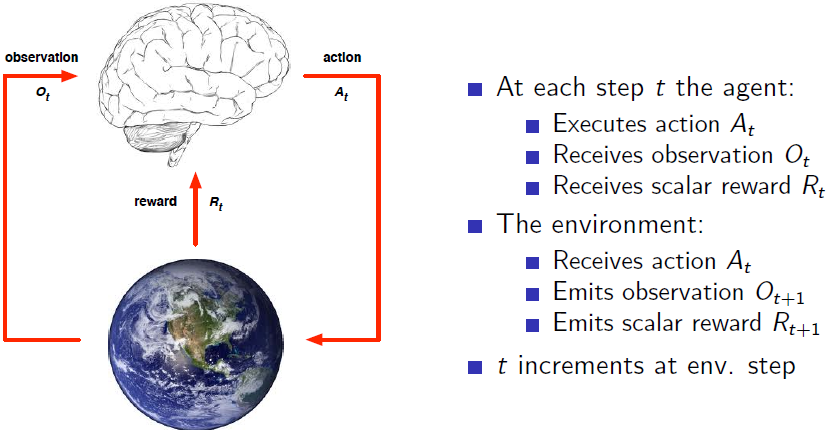
2.3 Histor(历史)和State(状态)
- History 是目前 Agent 所知道的东西,即一系列的观察、动作与奖励。 H t = O 1 , R 1 , A 1 , . . . , A t − 1 , O t , R t H_t=O_1, R_1, A_1, ..., A_{t-1}, O_t, R_t Ht=O1,R1,A1,...,At−1,Ot,Rt,即直到时间步t的所有观察到的变量(Agent感官仪器获取到的数据流);
- History 决定了接下来将会发生的事情;
– Agent 根据 History 选择 Actions;
– Environment 根据 History 选择 observations/rewards。 - History 信息量往往会很大,我们希望 Agents 可以在很短的时间内进行交互。因此我们一般研究的是状态 State,State 是对历史信息的总结,是 History 的函数, S t = f ( H t ) S_t=f(H_t) St=f(Ht)。
State 具体可分为三种:
(1) Environment state
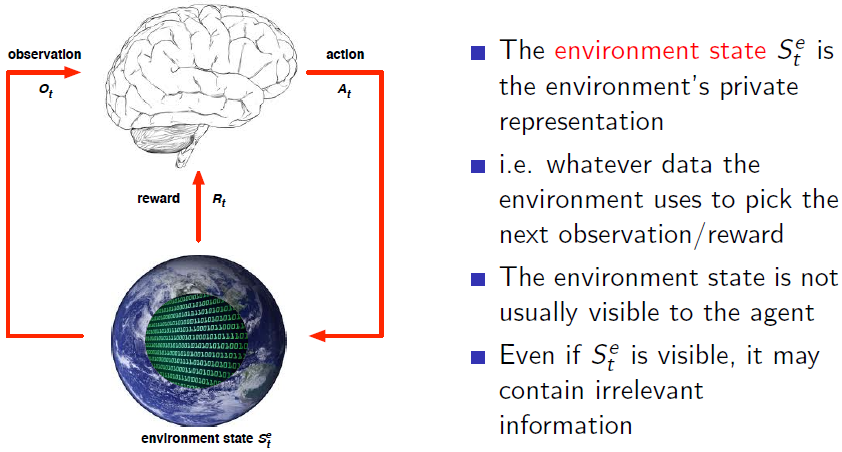
- 根据 Environment state 我们可以知道接下来会发生什么,以获取下一步的 observation/reward;
- Environment state 对于 Agent 并不总是可见的;
- Environment state 可能包含不相关信息;
(2) Agent state
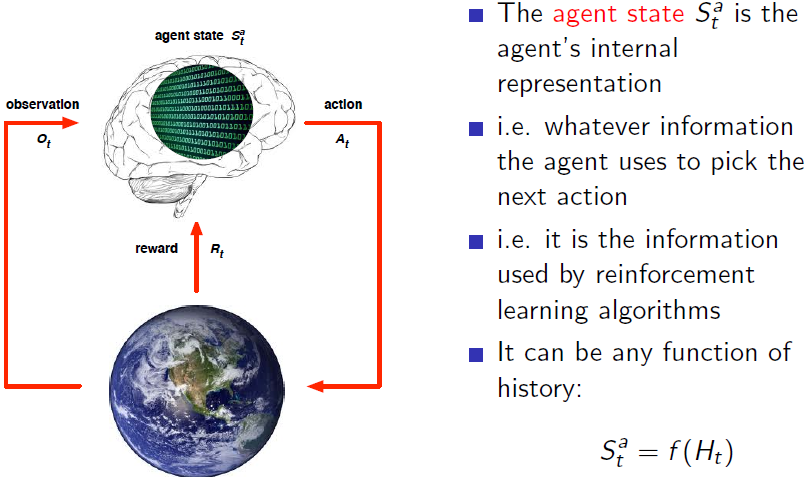
Agent state 决定了下一个 Action,即我们的决策算法是作用于Agent state上的。Agent state是前述history的函数,我们可以选择建立我们的映射函数,这是 Agent 的一部分,Agent 决定采用哪一个函数,如何将history、action、observation和reward联系起来,并将有用的信息保存下来。
(3) Information state(Markov state)

Markov 性指的是下一时刻的状态仅由当前状态决定,与过去的状态并没有太大关系,即可抛弃 History。Markov 状态包含了足够多的信息来得出未来的所有奖励。Markov的强大之处在于当定义 History 具备 Markov 性时它就不需要占据太大的空间。
例如环境状态是Markov的,因为环境状态包含了环境决定下一个观测/奖励的所有信息;同样,(完整的)历史 H t H_{t} Ht 也是马尔可夫的。
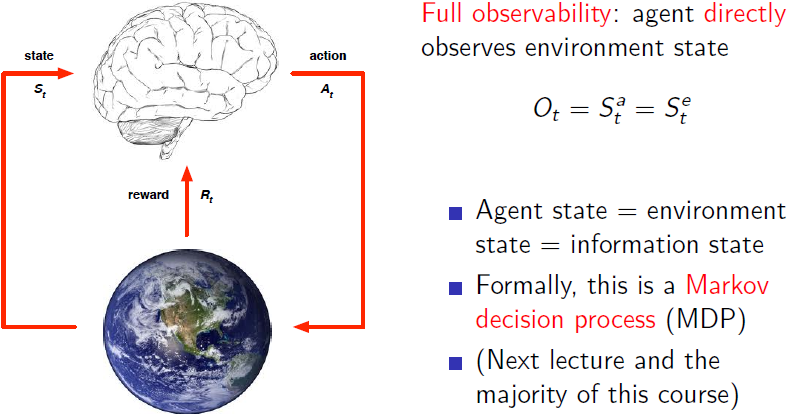
Fully Observable Environments:
Agent 能够真正地观测到环境状态的变化,即 Environment state 映射关系已知。另一种说法即Agent state与 Environment state相同。
Partially Observable Environments:
Agent并不能知道环境的所有信息。

Agent 必须构建它自己的状态呈现形式:
- 记录完整的历史数据: S t a = H t S^{a}_{t} = H_{t} Sta=Ht;
- 利用已有经验知识(数据),用各种智能体已知状态的概率分布作为当前时刻智能体状态的估计;
- 构建当前时刻智能体状态和观测的多项式,输入到循环神经网络中得到一个当前智能体状态的估计。
3. Agent(智能体)的组成要素
强化学习中的智能体可以由以下三个组成部分中的一个或多个组成:

- Policy

Policy就是我们需要学习得到的东西,它不一定是确定的,也可以是随机的。 - Value function

我们可以为Value function中未来时间步可能获得的Reward加上权重以告诉模型更重视眼前的Reward。 - Model
智能体对环境的建模,智能体通过模型模拟环境与智能体的交互机制。

- 一般而言model可以分为transition model( P P P)和reward model( R R R),前者用于预测环境的动态变化,后者用于估计我们得到的奖励;
- 从transition model公式中可以看出,其根据先前的状态和动作预测环境所处下一个状态的概率;
- 从Reward model 的公式中可以看出,预期的奖励是基于先前的状态与动作的。
(如今很多强化学习方法都是基于无模型的)
迷宫例子
-
基于确定Policy
每一个状态下做出何种动作都是确定的。
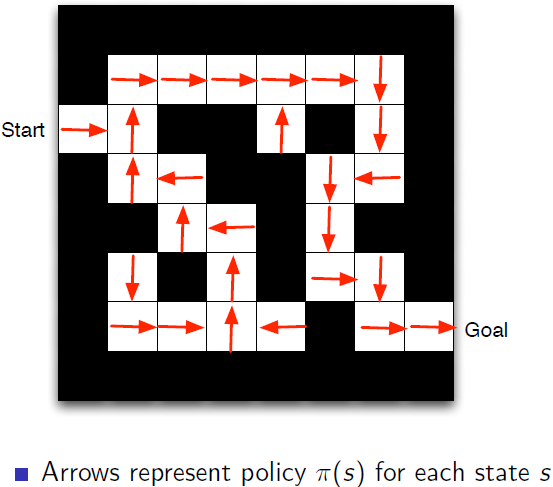
-
基于Value function
离终点步数越少奖励越高。

-
基于model
Model就是智能体创建一个自己对环境的感知映射。-1代表每走一步减1,即即时奖励。
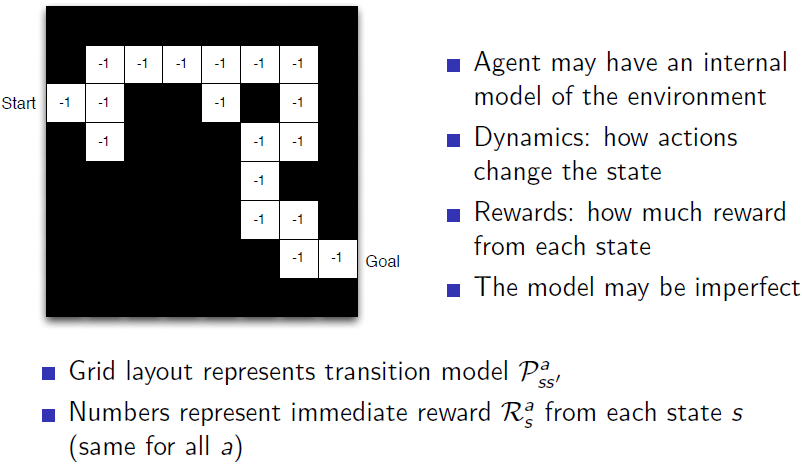
于是我们可以对RL的Agents进行分类:


4. Learning and Planning
强化学习与规划问题是密不可分的,强化学习第一步会试图去了解environment,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。

5. Exploration and Exploitation

探索和利用是智能体进行决策时需要平衡的两个方面。
6. Prediction and control

- 前者是遵循现在的policy,未来我们会得到多少奖励;
- 后者则是寻找最优的policy以得到最多的奖励;
- RL中我们需要解决prediction问题进而解决control问题,我们需要对所有的policy进行评估以找到最优policy。















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









