







本篇论文是谷歌投的一篇NIPS 2017的论文,提出了一种想象力增强的model-based强化学习方法,思路非常新颖,GitHub上可以搜到不少对I2A的复现代码。由于这篇论文写得比较抽象,个人时间有限,目前更多的只是翻译,之后有理解总结的话再更新本文。
本文旨在解决model-based方法中模型不准确导致预测存在误差的问题。
I2A既利用了基于模型的学习,也利用了无模型的学习。其架构如图1c所示,观测 O t O_t Ot同时输入到model-based路径(左)和model-free路径(右)中,其中model-free路径为常规的无模型强化学习算法。model-based路径的输出结果由多个rollout encoder聚合得到,rollout encoder是agent进行imagination任务的地方,其结果如图1b所示。
Rollout encoder有两层:imagine future和encoder。Imagine future是想象力发生的地方,imagine future中包括imagination core(结构如图1a)。向imagination core输入状态 O t O_t Ot,我们得到新的状态 O ^ t + 1 \hat{O}_{t+1} O^t+1和奖励 r ^ t + 1 \hat{r}_{t+1} r^t+1,接着将 O ^ t + 1 \hat{O}_{t+1} O^t+1输入到下一个imagination core得到下一个新状态 O ^ t + 2 \hat{O}_{t+2} O^t+2和奖励 r ^ t + 2 \hat{r}_{t+2} r^t+2。重复上述步骤 n n n次,我们得到一个基本上是一对状态和奖励的rollout,然后使用encoder(如LSTM)来编码此rollout,得到一个rollout encoding。这些rollout encoding就是想象出的未来路径。我们为不同的未来想象路径提供多个rollout encoder,我们使用一个aggregator 来聚合此rollout encoder。
Imagination core包括策略网络和环境模型。环境模型从agent的历史信息中学习,它获取状态 O ^ t \hat{O}_t O^t的信息,并根据经验想象所有可能的未来,选择高回报的动作 a ^ t \hat{a}_t a^t。
缺点:I2A将所有不确定性估计和模型使用表征至隐式神经网络训练过程中,继承了无模型方法的低效率。
文章目录
1. Introduction
Model-free方法使用了深度神经网络将原始观测直接映射为值或者动作,已经取得了一定的发展。但是这种方法通常需要大量的训练数据,且产生的策略不容易推广到同一环境中的新任务中,因为它缺乏泛化智能的行为灵活性。
Model-based RL 根据历史经验合成世界模型,通过使用内部模型来推理未来(imagining)。虽然需要先学习模型,但model-based的方法具有更好的泛化能力,且能够利用额外的无监督学习信号,提高数据效率。另外基于模型的方法通过增加内部模拟量来扩展性能和更多的计算能力。
基于模型的RL方法目前的应用仅限于具有精确的转换模型或易于学习的领域(符号环境或低维度系统)。对于复杂系统,采用标准规划方法基于模型的agent的性能通常会受到函数逼近导致的模型误差的影响。这些错误在规划过程中累积,导致过度乐观和很差的agent性能。目前没有能够抵抗模型缺陷的规划或基于模型的方法,这些方法在复杂域中是不可避免的。
本文通过提出想象力增强agent(Imagination-Augmented Agents)来解决这一问题,该方法通过“学习解释”不完美的预测来使用近似的环境模型。此种方法是end-to-end的、不对环境模型进行任何假设,且不完全依赖于模拟的returns。
2. The I2A architecture
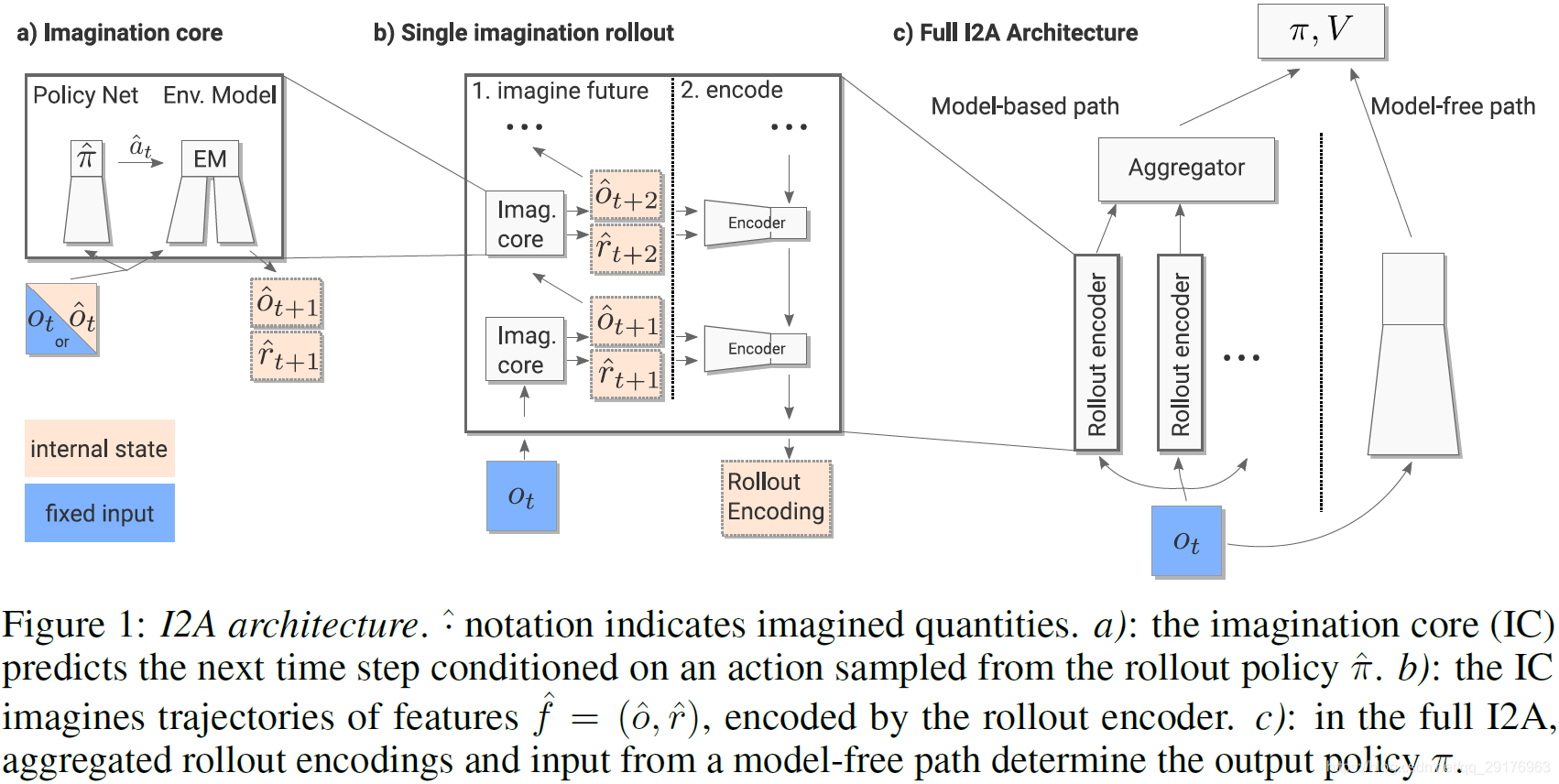
I2A架构图如上图所示。通过向环境模型输入当前的信息可以对未来进行预测,得到模拟的想象轨迹(imagined trajectories),这些轨迹由神经网络解释并作为策略网络的附加上下文提供。
通常,环境模型是可以从agent轨迹以无监督方式训练的任何循环架构:给定过去状态和当前动作,环境模型预测下一状态和来自环境的任何数量的信号。本文基于 action-conditional next-step predictors 建立环境模型,它们接收当前观测(或观测历史)和当前行动的输入,并预测下一次观测,也可能是下一次奖励。我们在未来的多个时间步中roll out环境模型,通过用当前时间的真实观测初始化想象轨迹,随后将模拟观测值馈送到模型中。
每一个rollout中的actions都来自于rollout策略 π ^ \widehat\pi π 。环境模型与策略 π ^ \widehat\pi π 共同构成了 imagination core module,用于预测下一时间步。该模块用于生成n个轨迹 T ^ 1 … T ^ n \widehat{T}_1\dots\widehat{T}_n T 1…T n,每一个轨迹 T ^ \widehat{T} T 都是一个特征序列( f ^ t + 1 , … , f ^ t + τ \widehat{f}_{t+1},\dots,\widehat{f}_{t+\tau} f t+1,…,f t+τ), t t t是当前时间步, τ \tau τ是rollout的长度, f ^ t + i \widehat{f}_{t+i} f t+i是环境模型的输出(即预测的observation 和/或 reward)。
I2As解决的一个关键问题是学习模型不能被认为是完美的,它有时可能会做出错误或无意义的预测。 因此,我们不希望仅依赖于预测的奖励(或从预测状态预测的值),这在经典规划中经常这么用。 此外,轨迹可能包含奖励序列之外的信息(轨迹可能包含信息性子序列 - 例如解决子问题 - 这不会导致更高的奖励)。 出于这些原因,我们使用一个rollout encoder ε \varepsilon ε将 imagined rollout 作为一个整体来处理并学会解释它,即提取对agent的决定有用的任何信息,或者甚至在必要时忽略它(图1b)。每个轨迹分别编码为rollout embedding e i = ε ( T ^ i ) e_i=\varepsilon(\widehat{T}_i) ei=ε(T i)。最后,aggregator
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









