







在眼底影像中青光眼的半监督分割

摘要主要说明了目前采用分割方法对于青光眼的诊断中,边界不明显的optic cup相比optic disc更难分割,因此这里只考虑optic cup的分割;本文方法的主要贡献点在于利用大量无标签数据的内在的特征来训练有少量标签数据集的分割模型,从而以半监督方式实现更高的分割精度;具体采用变分自编码器从无标签的数据集中学习数据潜在特征空间中的内嵌特征,然后文章将从无标签数据中通过变分自编码器中得到的内嵌特征组合到有监督的分割自编码器,从而实现分割自编码器有效训练,此时,训练的分割自编码器就会将无标签数据的内嵌特征考虑进来。实验结果表明,这种方法相比只用少量有标签的数据提高了optic cup的分割精度。
1 引言

目前半监督学习已经应用到MRI脑图分割、肺结核检测、视网膜血管的分割;本文方法首先通过VAE在大量无标签数据中学习这个内嵌的特征,然后通过迁移已学习到的内嵌特征的特性去训练分割自编码器。
2 本文半监督分割的方法
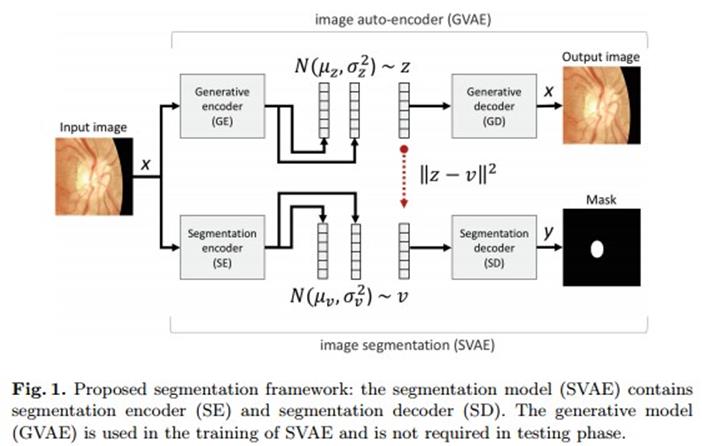
采用无标签的数据训练VAE,VAE由两部分组成:编码网网络GE将输入图像映射到连续的潜在变量z,解码网络GD使用变量z重构输入图像;
2.1 GVAE:生成变分自编码器
GE的模型为5层带有池化层的卷积层和2层全连接构成,网络的输入为图像x,而输出为均值和标准差,而潜在的中间变量z从这个正态分布中采样获得;GD由5层解卷积层构成,GD的输入为z,输出为重构的图像x。GVAE训练的代价函数由1式给出,其中第一项为后验近似q(z|x)到p(z)间的KL离散度,第二项为GD网络期望的重构误差;KL部分能够重新表达为2式:

这里有个问题,解码器GD的输入是从后验q(z|x)中随机采样产生,然后这种方式不能用于后向传播,因此本文针对这个问题使用文献5中的技巧对这部分进行重新参数化,使其能够用于后向传播的参数更新。
2.2 SVAE:应用于分割的变分编码器
SVAE的目的通过利用GVAE学习的内嵌特征去预测输入图像中的optic cup区域;本文SVAE也由包含5层卷积池化层和两层全连接层的SE和5层解卷积层的SD组成,SE的输入为图像x,输出为均值和方差;潜在中间变量v也是从q的正态分布中采样得到,SD以v作为输入,输出则为分割的optic cup的mask图像。
为了在SVAE中利用无标签图像的信息,此时给定一幅有标签的图像,已训练的GVAE能够得到潜在中间变量z,那么对于SVAE训练的代价函数可以定义为3式的表达式,第一项是p和q的负的KL离散度,能够重新表示为3式,第二项为输入v通过SD重建optic cup mask的误差,第三项为v和z的欧氏距离;
具体SVAE的训练步骤如下:
3 实验结果
EyePACS1(1 http://www.eyepacs.com/)12000张,其中选择600张伟有标签的数据集,11400为无标签的数据集;
数据的裁剪和尺寸变形

数据扩充

一般对于深度学习网络的训练,数据扩充是不可或缺的步骤
测试阶段处理

这里有点不理解的是均应该为向量,同时估计也是和z和v的维度一致;
对比实验

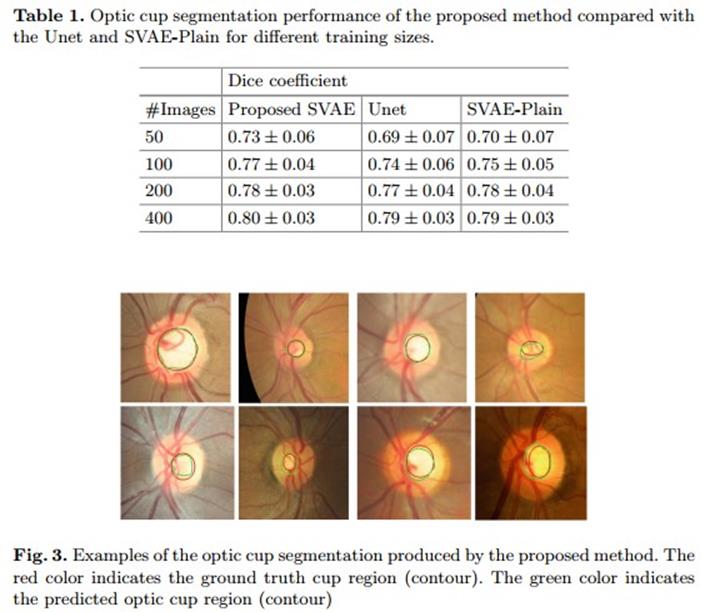
对于GVAE和SVAE的潜在中间变量z和v的维度设置为100;和医学图像最先进的分割方法Unet进行了对比,同时和没有GVAE的全监督模型作对比;
结果















 2944
2944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









