







深度优先(DFS)和广度优先(BFS)
深度优先搜索( Depth First Search , DFS ):首先从某个顶点出发,依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和该顶点有路径相通的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
广度优先搜索( Breadth First Search , BFS ):从图中某顶点出发,依次访问的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。
深度优先搜索和广度优先搜索分别类似于树的前序遍历和层次遍历。
Dijkstra 算法属于典型的广度优先搜索算法。
深度优先搜索(DFS)

算法基本思想
1.首先访问图中某一个顶点Vi,以该顶点为出发点;
2.任选一与该顶点Vi邻接的未被访问的顶点Vj;访问Vj;
3.以Vj为新的出发点继续进行深度优先搜索,直至图中所有和Vi有路径的顶点被访问到。
深度优先搜索算法
从图的某一点 v 出发,递归地进行深度优先遍历算法描述:
void DFSTraverse(Graph G)
{for (v=0; v<G.vexnum; ++v)
visited[v] = FALSE; /*访问标志数组初始化*/
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS(G, v); /*对尚未访问的顶点调用 DFS*/
}
void DFS(Graph G,int v ) /*从第 v 个顶点出发递归地深度优先遍历图 G*/
{ visited[v]=TRUE;Visit(v); /*访问第 v 个顶点*/
for(w=FisrtAdjVex(G,v);w>=0; w=NextAdjVex(G,v,w))
if (!visited[w]) DFS(G,w); /*对 v 的尚未访问的邻接顶点 w 递归调用 DFS*/
}
以邻接表为存储结构的整个图 G 进行深度优先遍历实现的 C 语言描述:
void DFSTraverseAL(ALGraph G) /*深度优先遍历以邻接表存储的图 G*/
{ int i;
for (i=0;i<G.vexnum;i++)
visited[i]=FALSE; /*标志向量初始化*/
for (i=0;i<G.vexnum;i++)
if (!visited[i]) DFSAL(G,i); /*vi未访问过,从 vi开始 DFS 搜索*/
}
void DFSAL(ALGraph G,int i) /*以 vi为出发点对邻接表存储的图 G 进行 DFS 搜索*/
{ ArcNode *p;
Visit(G.adjlist[i]); /*访问顶点 vi*/
visited[i]=TRUE; /*标记 vi已访问*/
p=G.adjlist[i].firstarc; /*取 vi边表的头指针*/
while(p) /*依次搜索 vi的邻接点 vj,j=p->adjvex*/
{ if (!visited[p->adjvex]) /*若 vj尚未访问,则以 vj为出发点向纵深搜索*/
DFSAL(G,p->adjvex);
p=p->nextarc; /*找 vi的下一个邻接点*/
} }
此部分详细原理解释可以参考严蔚敏的数据结构(C语言版)
遍历图的过程实质上是对每个顶点查找其邻接点的过程,其耗费的时间则取决于所采用的存储结构。当以邻接矩阵为图的存储结构时,查找每个顶点的邻接点所需时间为O(n2) ,其中 n 为图中顶点数。而当以邻接表作图的存储结构时,找邻接点所需时间为 O(e),其中e 为无向图中边的数或有向图中弧的数。由此,当以邻接表作存储结构时,深度优先搜索遍历图的时间复杂度为 O(n+e) 。
广度优先搜索(BFS)
算法基本思想
广度优先搜索(BFS)遍历类似于树的按层次遍历。
(1)首先访问图中某一指定的出发点Vi;
(2)然后依次访问VI的所有邻接点Vi1,Vi2……Vit;
(3)再依次以Vi1,Vi2……Vit为顶点,访问各顶点未被访问的邻接点,依此类推,直到图中所有顶点均被访问为止。
广度优先搜索(BFS)
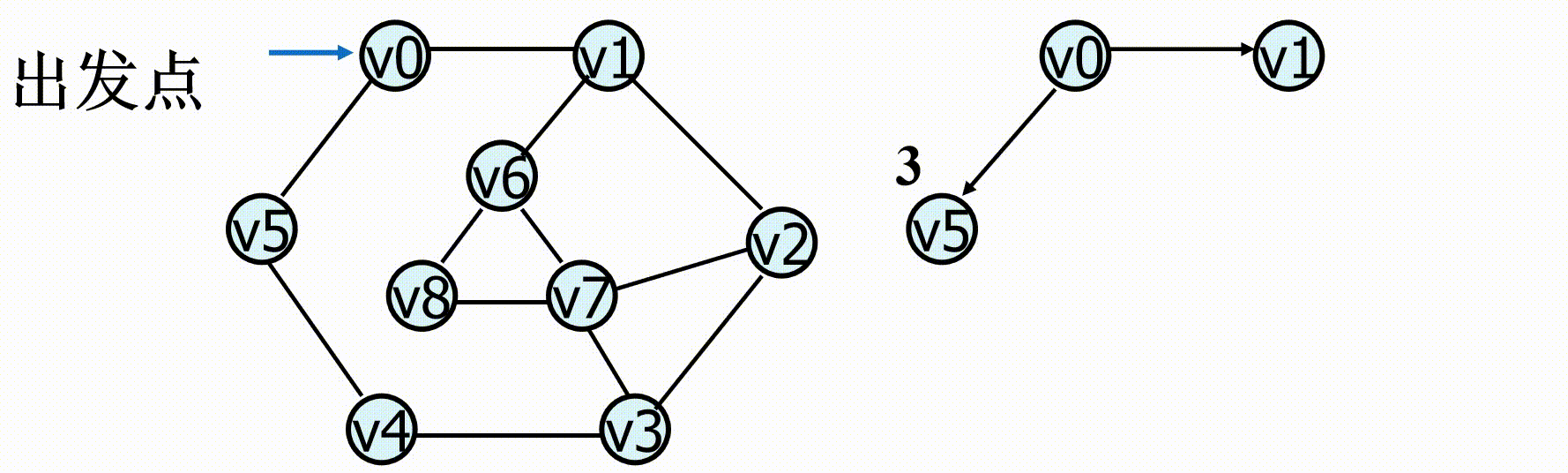 从图的某一点 v 出发,进行广度优先遍历算法描述:
从图的某一点 v 出发,进行广度优先遍历算法描述:
void BFSTraverse (MGraph G) /*按广度优先非递归遍历图 G,使用辅助队列 Q*/
{
for (v=0; v<G.vexnum; ++v)
visited[i] = FALSE; /*访问标志数组初始化*/
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) BFS(G, v); /*对尚未访问的顶点调用 BFS*/
}
void BFS (Graph G,int v) {InitQueue(Q); /*置空的辅助队列 Q*/
visited[v]=TRUE; Visit(v); /*访问 v*/
EnQueue(Q,v); /*v 入队列*/
while (!QueueEmpty(Q))
{ DeQueue(Q,u); /*队头元素出队并置为 u*/
for(w=FistAdjVex(G,u); w>=0; w=NextAdjVex(G,u,w))
if(!visited[w])
{visited[w]=TRUE; Visit(w);
EnQueue(Q,w); /*u 尚未访问的邻接顶点 w 入队列 Q*/
}
}
}
以邻接矩阵为存储结构的整个图 G 进行广度优先遍历实现的 C 语言描述。
void BFSTraverseAL(MGraph G) /*广度优先遍历以邻接矩阵存储的图 G*/
{
int i;
for (i=0;i<G.vexnum;i++)
visited[i]=FALSE; /*标志向量初始化*/
for (i=0;i<G.vexnum;i++)
if (!visited[i]) BFSM(G,i); /* vi未访问过,从 vi开始 BFS 搜索*/
}
void BFSM(MGraph G,int k) /*以 vi为出发点,对邻接矩阵存储的图 G 进行 BFS 搜索*/
{
int i,j;
sqQueue Q;
InitQueue(Q);
Visit(G.vexs[k]); /*访问原点 Vk*/
visited[k]=TRUE;
EnQueue(Q,k); /*原点 Vk入队列*/
while (!QueueEmpty(Q))
{i=DeQueue(Q); /*Vi出队列*/
for (j=0;j<G.vexnum;j++) /*依次搜索 Vi的邻接点 Vj*/
if(G.edges[i][j]==1 && !visited[j]) /*若 Vj未访问*/
{Visit (G.vexs[j]); /*访问 Vj */
visited[j]=TRUE;
EnQueue(Q,j); /*访问过的 Vj入队列*/
}
}
}
此部分详细原理解释可以参考严蔚敏的数据结构(C语言版)
Dijkstra算法
Dijkstra 算法是由荷兰计算机科学家迪杰斯特拉于1959年提出的,是从一个节点遍历其余各节点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
Dijkstra算法原理
初始点看作一个集合S,其它点看作另一个集合挨个的把离初始点最近的点找到并加入集合S,集合中所有的点的d[i]都是该点到初始点最短路径长度,由于后加入的点是根据集合S中的点为基础拓展的,所以能找到最短路径。
用途: 用于求图中指定两点之间的最短路径,或者是指定一点到其它所有点之间的最短路径。
Dijkstra算法基本步骤
1.将图上的初始点看作一个集合S,其它点看作另一个集合
2.根据初始点,求出其它点到初始点的距离d[i] (若相邻,则d[i]为边权值;若不相邻,则d[i]为无限大)
3.选取最小的d[i](记为d[x]),并将此d[i]边对应的点(记为x)加入集合S(实际上,加入集合的这个点的d[x]值就是它到初始点的最短距离)
4.再根据x,更新跟 x 相邻点 y 的d[y]值:d[y] = min{ d[y], d[x] + 边权值w[x][y] },因为可能把距离调小,所以这个更新操作叫做松弛操作。
5.重复3,4两步,直到目标点也加入了集合,此时目标点所对应的d[i]即为最短路径长度。(注:重复第三步的时候,应该从所有的d[i]中寻找最小值,而不是只从与x点相邻的点中寻找)
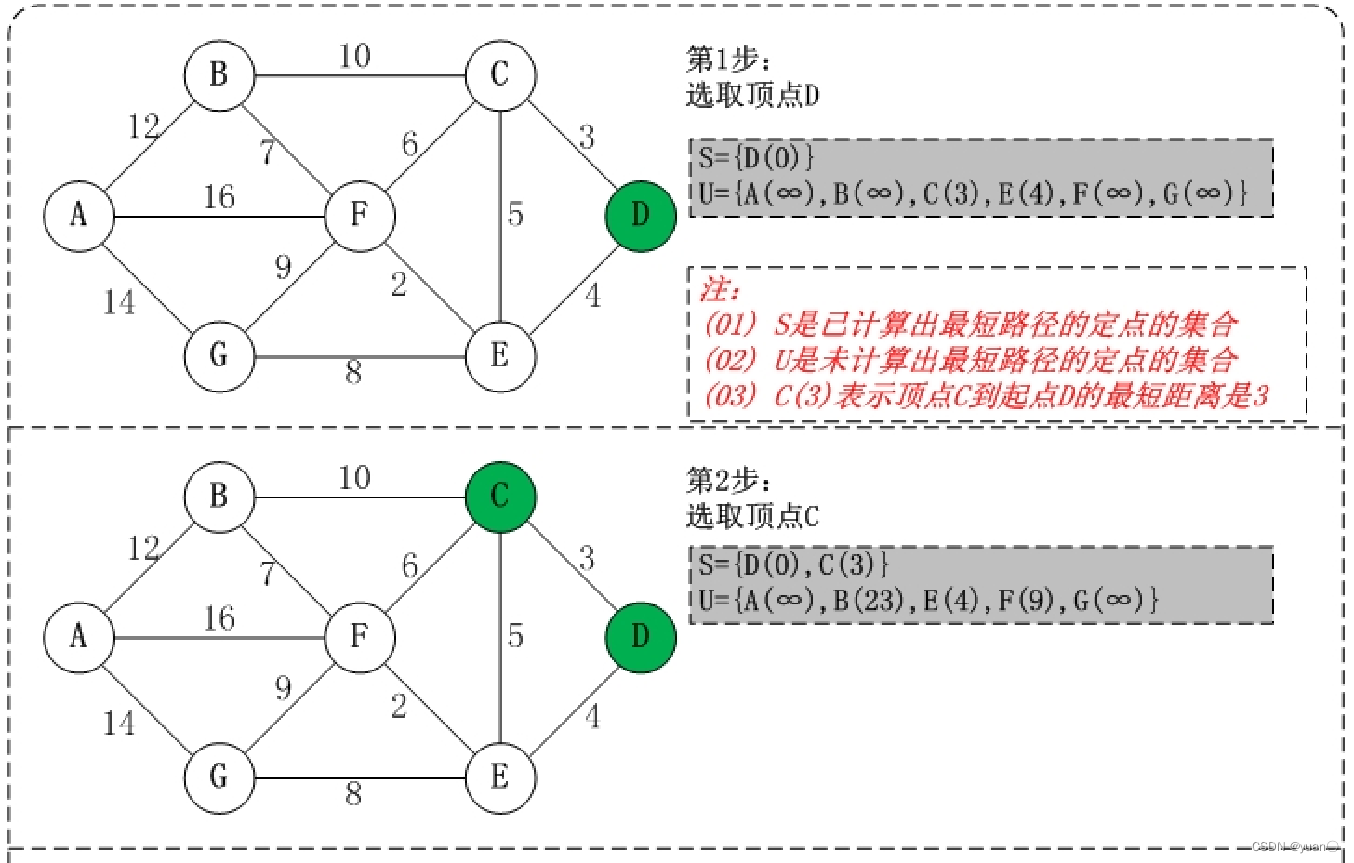
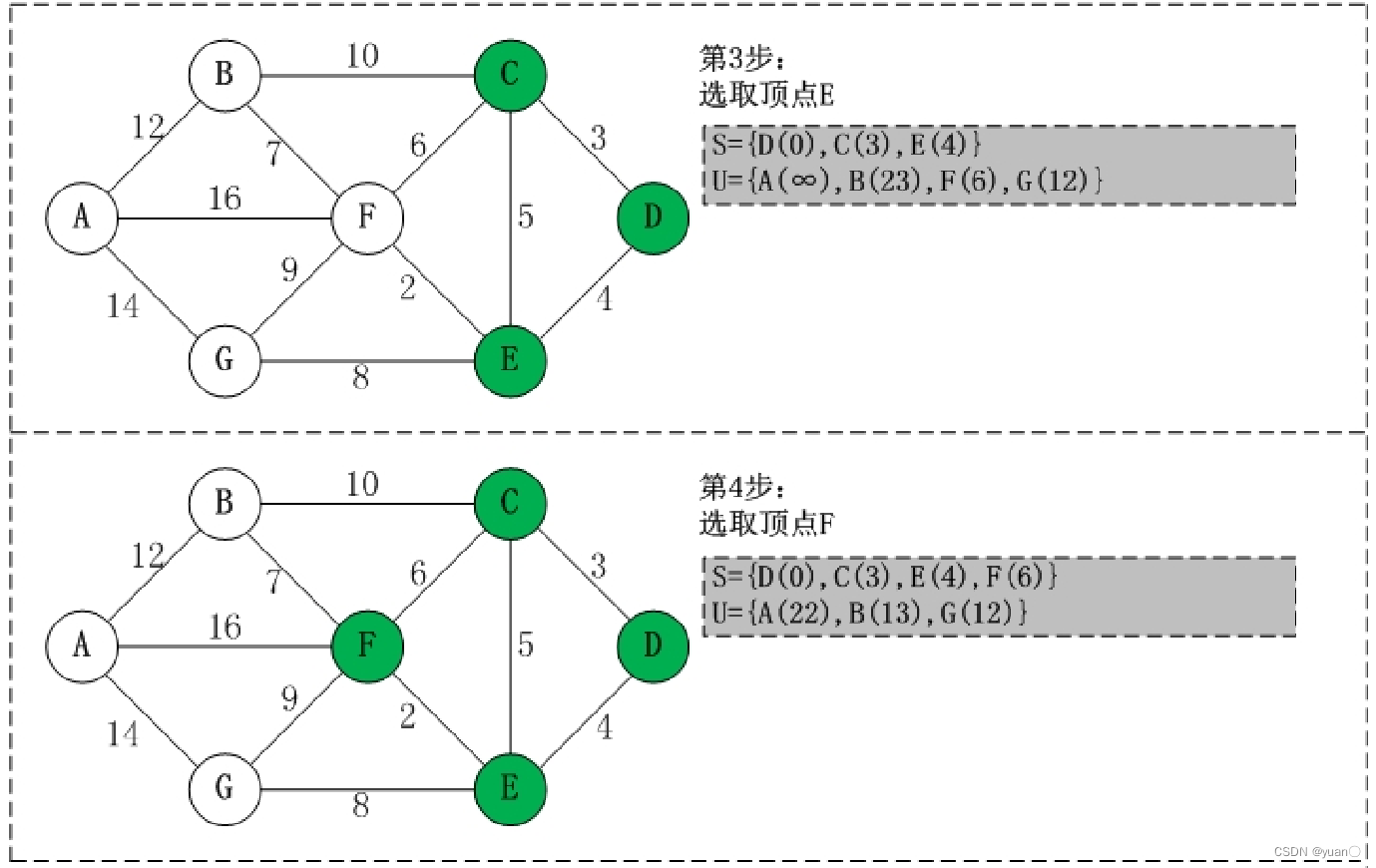
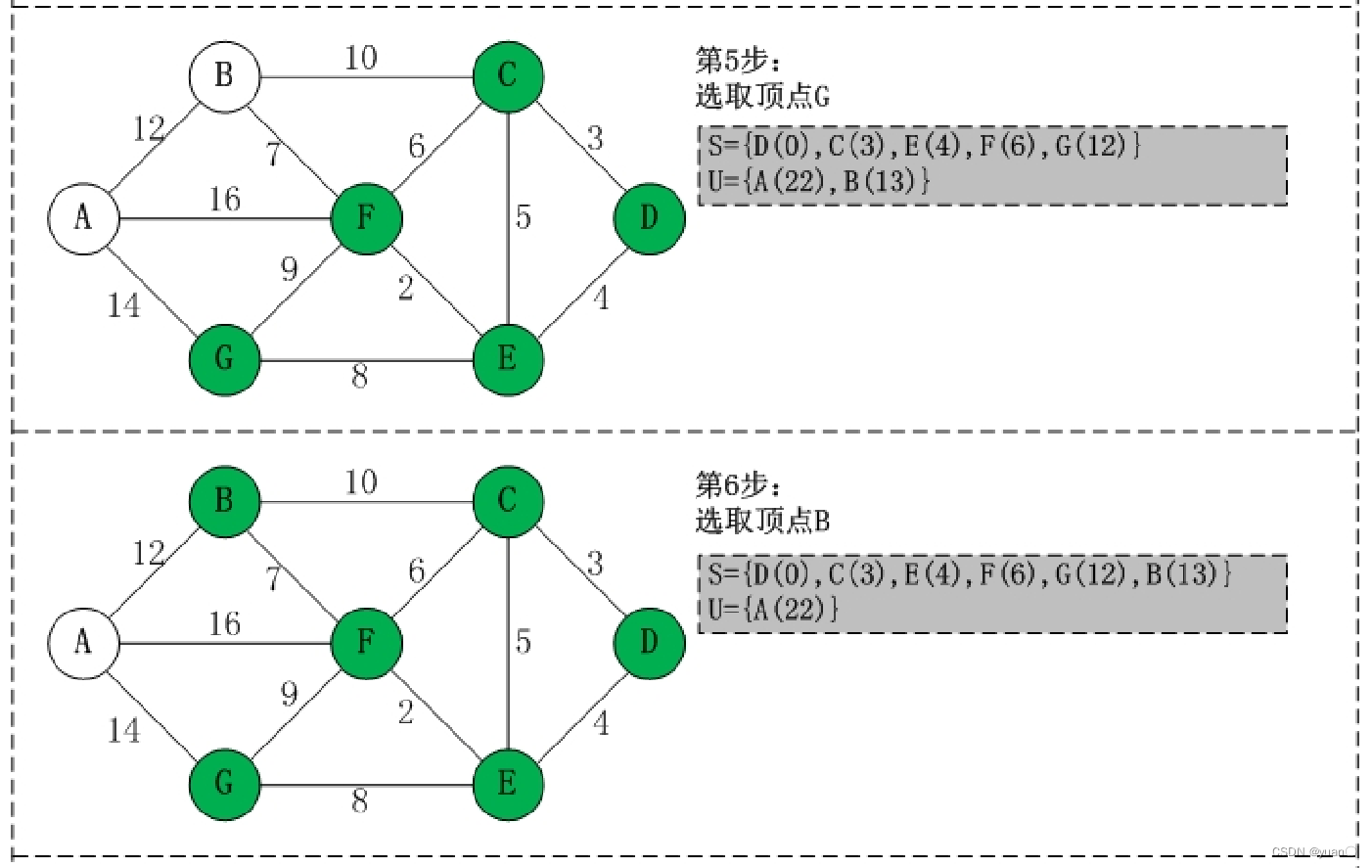
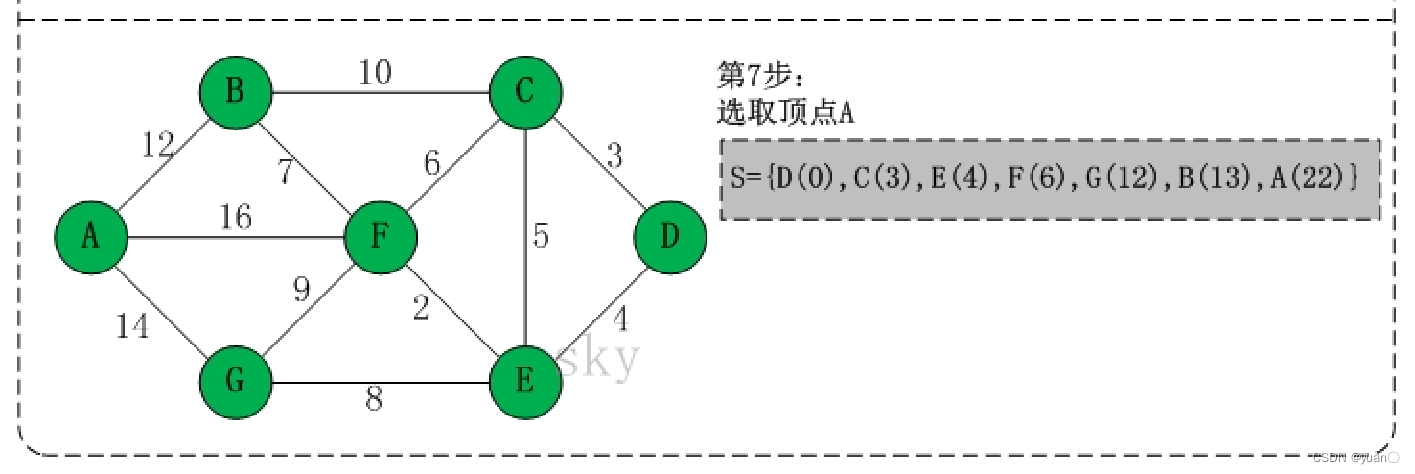 Dijkstra 算法十分简洁,能够有效的找到最优解,不足之处在数据节点庞大时所需的节点繁多,效率随着数据节点的增加而下降,耗费大量内存空间与计算时间。
Dijkstra 算法十分简洁,能够有效的找到最优解,不足之处在数据节点庞大时所需的节点繁多,效率随着数据节点的增加而下降,耗费大量内存空间与计算时间。

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









