







论文标题:MVTN: Multi-View Transformation Network for 3D Shape Recognition
论文、项目地址:在公众号「计算机视觉工坊」,后台回复「MVTN」,即可直接下载。
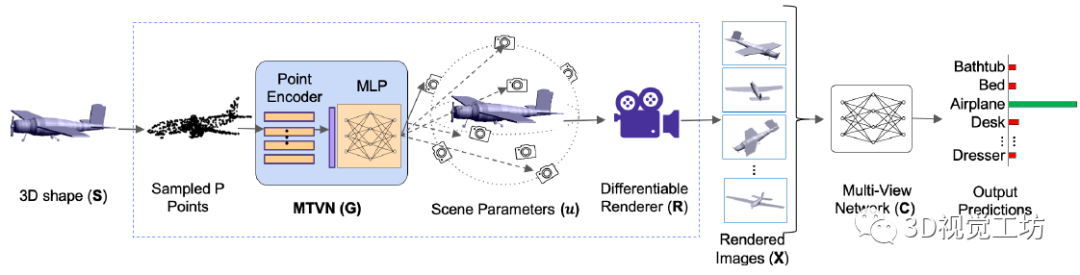
摘要:多视图投影方法在3D形状识别方面能达到先进的性能,现有的这些方法学习从多个视图聚合信息。然而,对于所有形状,这些视图的相机视点往往是启发式设置和固定的。为了避免当前固化的多视图方法,研究人员引入了多视图转换网络 (MVTN),它基于可微渲染的最新研究进展实现3D形状识别的视点回归。因此,MVTN可以与任何用于3D形状分类的多视图网络一起进行端到端的训练。研究人员将MVTN集成到可以渲染3D网格或点云的新型自适应多视图网络中。MVTN在3D形状分类和3D形状检索任务中表现出明显的性能提升,而无需额外的训练监督。在这些任务中,MVTN在ModelNet40、ShapeNet Core55和最新的ScanObjectNN数据集上实现了最先进的性能(提高了6%)。同时研究表明MVTN可以针对旋转和遮挡提高网络的鲁棒性。
研究贡献:
1.提出了MVTN网络,利用可微分渲染器,支持3D形状识别任务的端到端训练。
2.将MVTN与多视图方法相结合,在标准基线ModelNet40、ShapeNet Core55和ScanObjectNN上的3D分类和形状检索方面取得了当前研究中的最佳结果。
3.MVTN针对多视图旋转和遮挡问题,提高网络的鲁棒性,使MVTN在3D模型未完全对齐或部分裁剪的现实场景中更加实用。
研究方法:
1.MultiView 3D 识别概述
3D多视图识别通过从相同形状S的多个视点渲染定义了M幅图像,这些视图被输入至同一个骨干网络f中,使用该网络提取每个视图的判别特征,然后将这些特征在视图中进行聚合,进而用于下游任务,例如分类或检索。
Training Multi-View Networks:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









