






点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

作者丨仿佛若有光157
来源丨CV技术指南
前言 本文介绍了NMS的应用场合、基本原理、多类别NMS方法和实践代码、NMS的缺陷和改进思路、介绍了改进NMS的几种常用方法、提供了其它不常用的方法的链接。
本文很早以前发过,有个读者评论说没有介绍多类别NMS让他不满意,因此特来补充。顺便补充了NMS的缺点和改进思路。
Non-Maximum Suppression(NMS)非极大值抑制。从字面意思理解,抑制那些非极大值的元素,保留极大值元素。其主要用于目标检测,目标跟踪,3D重建,数据挖掘等。
目前NMS常用的有标准NMS, Soft NMS, DIOU NMS等。后续出现了新的Softer NMS,Weighted NMS等改进版。
原始NMS
以目标检测为例,目标检测推理过程中会产生很多检测框(A,B,C,D,E,F等),其中很多检测框都是检测同一个目标,但最终每个目标只需要一个检测框,NMS选择那个得分最高的检测框(假设是C),再将C与剩余框计算相应的IOU值,当IOU值超过所设定的阈值(普遍设置为0.5,目标检测中常设置为0.7,仅供参考),即对超过阈值的框进行抑制,抑制的做法是将检测框的得分设置为0,如此一轮过后,在剩下检测框中继续寻找得分最高的,再抑制与之IOU超过阈值的框,直到最后会保留几乎没有重叠的框。这样基本可以做到每个目标只剩下一个检测框。

原始NMS(左图1维,右图2维)算法伪代码如下:


实现代码:(以pytorch为例)
def NMS(boxes,scores, thresholds):
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
areas = (x2-x1)*(y2-y1)
_,order = scores.sort(0,descending=True)
keep = []
while order.numel() > 0:
i = order[0]
keep.append(i)
if order.numel() == 1:
break
xx1 = x1[order[1:]].clamp(min=x1[i])
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
w = (xx2-xx1).clamp(min=0)
h = (yy2-yy1).clamp(min=0)
inter = w*h
ovr = inter/(areas[i] + areas[order[1:]] - inter)
ids = (ovr<=thresholds).nonzero().squeeze()
if ids.numel() == 0:
break
order = order[ids+1]
return torch.LongTensor(keep)除了自己实现以外,也可以直接使用torchvision.ops.nms来实现。
torchvision.ops.nms(boxes, scores, iou_threshold)上面这种做法是把所有boxes放在一起做NMS,没有考虑类别。即某一类的boxes不应该因为它与另一类最大得分boxes的iou值超过阈值而被筛掉。
对于多类别NMS来说,它的思想比较简单:每个类别内部做NMS就可以了。
实现方法:把每个box的坐标添加一个偏移量,偏移量由类别索引来决定。
下面是torchvision.ops.batched_nms的实现源码以及使用方法
#实现源码
max_coordinate = boxes.max()
offsets = idxs.to(boxes) * (max_coordinate + torch.tensor(1).to(boxes))
boxes_for_nms = boxes + offsets[:, None]
keep = nms(boxes_for_nms, scores, iou_threshold)
return keep
#使用方法
torchvision.ops.boxes.batched_nms(boxes, scores, classes, nms_thresh)这里偏移量用boxes中最大的那个作为偏移基准,然后每个类别索引乘以这个基准即得到每个类的box对应的偏移量。这样就把所有的boxes按类别分开了。
在YOLO_v5中,它自己写了个实现的代码。
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres)这里的max_wh相当于前面的boxes.max(),YOLO_v5中取的定值4096。这里的agnostic用来控制是否用于多类别NMS还是普通NMS。
NMS的缺点
1. 需要手动设置阈值,阈值的设置会直接影响重叠目标的检测,太大造成误检,太小达不到理想情况。
2. 低于阈值的直接设置score为0,做法太hard。
3. 只能在CPU上运行,成为影响速度的重要因素。
4. 通过IoU来评估,IoU的做法对目标框尺度和距离的影响不同。
NMS的改进思路
1. 根据手动设置阈值的缺陷,通过自适应的方法在目标系数时使用小阈值,目标稠密时使用大阈值。例如Adaptive NMS
2. 将低于阈值的直接置为0的做法太hard,通过将其根据IoU大小来进行惩罚衰减,则变得更加soft。例如Soft NMS,Softer NMS。
3. 只能在CPU上运行,速度太慢的改进思路有三个,一个是设计在GPU上的NMS,如CUDA NMS,一个是设计更快的NMS,如Fast NMS,最后一个是掀桌子,设计一个神经网络来实现NMS,如ConvNMS。
4. IoU的做法存在一定缺陷,改进思路是将目标尺度、距离引进IoU的考虑中。如DIoU。
下面稍微介绍一下这些方法中常用的一部分,另一部分仅提供链接。
Soft NMS
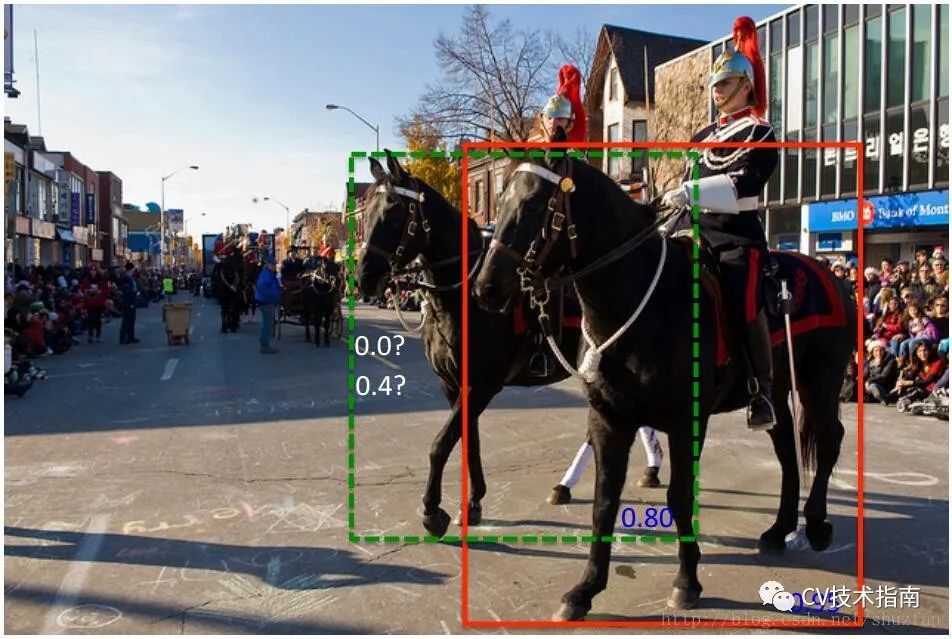
根据前面对目标检测中NMS的算法描述,易得出标准NMS容易出现的几个问题:当阈值过小时,如下图所示,绿色框容易被抑制;当过大时,容易造成误检,即抑制效果不明显。因此,出现升级版soft NMS。
Soft NMS算法伪代码如下:

标准的NMS的抑制函数如下:
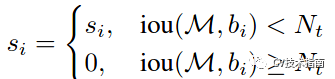
IOU超过阈值的检测框的得分直接设置为0,而soft NMS主张将其得分进行惩罚衰减,有两种衰减方式,第一种惩罚函数如下:
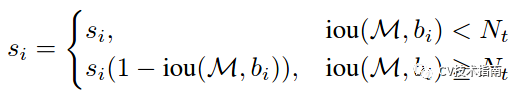
这种方式使用1-Iou与得分的乘积作为衰减后的值,但这种方式在略低于阈值和略高于阈值的部分,经过惩罚衰减函数后,很容易导致得分排序的顺序打乱,合理的惩罚函数应该是具有高iou的有高的惩罚,低iou的有低的惩罚,它们中间应该是逐渐过渡的。因此提出第二种高斯惩罚函数,具体如下:
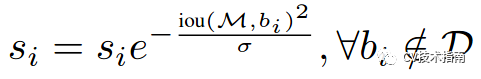
这样soft NMS可以避免阈值设置大小的问题。
Soft NMS还有后续改进版Softer-NMS,其主要解决的问题是:当所有候选框都不够精确时该如何选择,当得分高的候选框并不更精确,更精确的候选框得分并不是最高时怎么选择 。论文值得一看,本文不作更多的详解。
此外,针对这一阈值设置问题而提出的方式还有Weighted NMS和Adaptive NMS。
Weighted NMS主要是对坐标进行加权平均,实现函数如下:
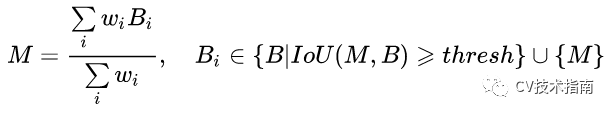
其中Wi = Si *IoU(M,Bi),表示得分与IoU的乘积。
Adaptive NMS在目标分布稀疏时使用小阈值,保证尽可能多地去除冗余框,在目标分布密集时采用大阈值,避免漏检。
Softer NMS论文链接:
https://arxiv.org/abs/1809.08545
Softer NMS论文代码:
https://github.com/yihui-he/softer-NMS
Weighted NMS论文链接:
https://ieeexplore.ieee.org/document/8026312/
Adaptive NMS论文链接:
https://arxiv.org/abs/1904.03629
DIoU NMS
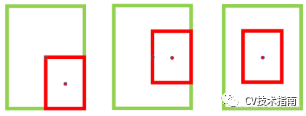
当IoU相同时,如上图所示,当相邻框的中心点越靠近当前最大得分框的中心点,则可认为其更有可能是冗余框。第一种相比于第三种更不太可能是冗余框。因此,研究者使用所提出的DIoU替代IoU作为NMS的评判准则,公式如下:
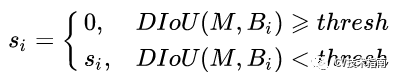
DIoU定义为DIoU=IoU-d²/c²,其中c和d的定义如下图所示
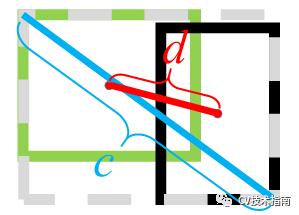
在DIoU实际应用中还引入了参数β,用于控制对距离的惩罚程度。
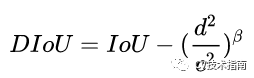
当 β趋向于无穷大时,DIoU退化为IoU,此时的DIoU-NMS与标准NMS效果相当。
当 β趋向于0时,此时几乎所有中心点与得分最大的框的中心点不重合的框都被保留了。
注:除了DIoU外,还有GIoU,CIoU,但这两个都没有用于NMS,而是用于坐标回归函数,DIoU虽然本身也是用于坐标回归,但有用于NMS的。
GIoU
GIoU的主要思想是引入将两个框的距离。寻找能完全包围两个框的最小框(计算它的面积Ac)。

计算公式如下:
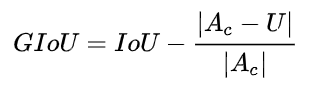
当两个框完全不相交时,没有抑制的必要。
当两个框存在一个大框完全包围一个小框时或大框与小框有些重合时,GIoU的大小在(-1,1)之间,不太好用来作为NMS的阈值。
GIoU的提出主要还是用于坐标回归的loss,个人感觉用于NMS不合适,CIoU也是如此,这里之所以提这个,是因为它与DIoU、CIoU一般都是放一起讲的。
其它相关NMS
为了避免阈值设置大小、目标太密集等问题,还有一些其他方法使用神经网络去实现NMS,但并不常用,这里只提一笔,感兴趣的读者请自行了解。如:
ConvNMS:A Convnet for Non-maximum Suppression
Pure NMS Network:Learning non-maximum suppression
Yes-Net: An effective Detector Based on Global Information
Fast NMS:
https://github.com/dbolya/yolact
Cluster NMS:
https://github.com/Zzh-tju/CIoU
Matrix NMS:
https://github.com/WXinlong/SOLO
Torchvision封装的免编译CUDA NMS
此处参考:
https://zhuanlan.zhihu.com/p/157900024
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









