









目录
LangChain利用区块链的不可篡改性、去中心化、透明等特点,解决目前语言服务行业中存在的信任问题,为企业和个人提供安全、高效、低成本的语言服务。LangChain的目标是在全球范围内打造一个透明、高效、互相信任的语言服务生态系统,为语言行业提供更好的发展机遇。它通过智能合约和分布式网络连接语言服务提供商和客户,提供包括翻译、口译、本地化等在内的各种语言服务。
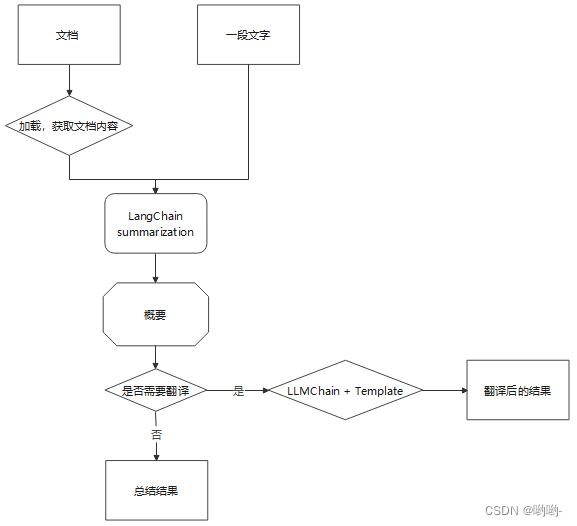
本次示例中,我们使用LangChain对文档进行概要总结,并使用它的翻译能力,将总计后的文本翻译成任何想要的语言。总体执行过程如下:
1. 引入需要的类
该功能的实现,需要使用到大语言模型的OpenAI,langchain/chains的LLMChain类、loadSummarizationChain类,以及langchain/text_splitter中的RecursiveCharacterTextSplitter类进行文档分割。以此引入需要的类如下:
import { OpenAI } from "langchain/llms/openai"
import { LLMChain, loadSummarizationChain } from "langchain/chains"
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"
2. 获取OpenAI key
在OpenAI网站中,获取key。这是必须的,在创建OpenAI实例时,key是一个必要参数。
const OPENAI_API_KEY = '' // openAI key,需要自己获取
3. 创建一个openai实例
创建OpenAI实例,此处我们设置了temperature参数为0,意思是进行精确匹配(temperature参数相关可查看我的上一篇博文 temperature 中的介绍),maxTokens参数设置-1表示尽可能输出多的返回结果,设置verbose为true参数表示在openai执行过程中输出详细过程,modelName指定了gpt-3.5-turbo-0613,你也可改为其它模型。
const model = new OpenAI({
openAIApiKey: OPENAI_API_KEY,
temperature: 0,
maxTokens: -1,
verbose: true,
modelName: 'gpt-3.5-turbo-0613'
})
4. 文档加载
加载文档,并提取文档的内容。LangChain对不同格式的文档分别定义了不同的文档加载器,此处我们只对text、pdf、docx三类文档的加载做了演示,分别引入对应的文档加载器:
import {TextLoader} from 'langchain/document_loaders/fs/text'
import { PDFLoader } from 'langchain/document_loaders/fs/pdf'
import { DocxLoader } from 'langchain/document_loaders/fs/docx'
使用.load()方法完成文档加载,获取到文档内容。
async function getDocPageContent(origin:string, query_docs: any, filename: string) {
let querys = query_docs
if(!!origin && origin === 'file') {
const fileType:string = filename.split('.').slice(-1)[0]
const loaders: Record<string,any> = {
'txt': new TextLoader(`statics/${filename}`),
'pdf': new PDFLoader(`statics/${filename}`),
'docx': new DocxLoader(`statics/${filename}`),
'doc': new DocxLoader(`statics/${filename}`)
}
const loader = loaders[fileType]
const docLoad = await loader.load()
querys = docLoad[0].pageContent
}
return querys
}
5. 进行文档拆分,获取文档list
chunkSize和chunkOverlap可以自己设置,一般chunkOverlap需要设置大于0,保证文档分割不会漏掉。
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 10 }) // 文本拆分
const docs = await textSplitter.createDocuments([query_docs]) // 返回一个拆分后的文档list
6. 概要总结
使用loadSummarizationChain类定义一个chain,并执行.call方法,传入参数为文档list。
const chain = loadSummarizationChain(model, {
type: 'map_reduce',
returnIntermediateSteps: true,
})
const result = await chain.call({
input_documents: docs,
})
console.log(result.text) // 总结的结果
执行上述方法,就可完成文档的总结。但在实际过程中,由于一些不可控因素,总结后输出的语言类型会与输入语言的种类可能会不一致。如包含中英文的一段文本,总结后变成英文,而且这种现象覅从场景。所以,总结完成后,我们还多加入了一个步骤:文本翻译。
下面执行翻译过程:
7. 文本翻译
7.1 引入类
从langchain/prompts中引入SystemMessagePromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate三个提示词模板,并引入对话模型ChatOpenAI。
import { SystemMessagePromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate } from "langchain/prompts"
import { ChatOpenAI } from "langchain/chat_models/openai"
7.2 编写翻译提示词,生成模板
编写提示词模板templatePoem,提示词模板在LangChain中非常重要,大模型通过提示词模板的提示执行操作,所以,使用大语言模型时,提示词模板需要进行多调试才行。
templatePoem用于生成系统模板,同时创建一个HumanMessagePromptTemplate模板,用于接收来自chat的信息。ChatPromptTemplate将两类消息模板结合起来,用于作为ChatOpenAI的提示词模板。
const templatePoem =`
you are a translation expert, proficient in various languages.
Please translate the article or text in the style of William Shakespeare.
Translates everything into {to_language}.`
const systemTemplatePoem = SystemMessagePromptTemplate.fromTemplate(templatePoem)
const humanMessagePrompt = HumanMessagePromptTemplate.fromTemplate("{text}")
const chatPromptTemplatePoem = ChatPromptTemplate.fromPromptMessages([systemTemplatePoem, humanMessagePrompt])
7.3 构建ChatOpenAI示例,并执行翻译
首先使用ChatOpenAI定义一个翻译模型,此处使用gpt-4-0613,temperature为0
定义一个LLMChain,分别传入大语言模型和模板,执行.call方法即可进行翻译。此处,因为我们在系统模板和对话模板中均设置了参数,所以在.call方法中即可传入指定的参数。大语言模型在执行时便可接收到该参数,按照您所设定的方式进行执行。
const translateModel = new ChatOpenAI({ modelName: "gpt-4-0613", temperature: 0, openAIApiKey: OPENAI_API_KEY })
const translateChain = new LLMChain({llm: translateModel, prompt: chatPromptTemplatePoem})
const result = await translateChain.call({
to_language: to_language,
text: text
})
以上,即可完成对文档概要进行总结。但需要注意的是:
- 在使用
loadSummarizationChain时,需要主要文档切割的程度; - 对于翻译的结果,我们增加了翻译,这里主要是因为大语言模型对于文本语言的不确定性导致的。对于它不能够识别语言的这一个问题,我们已经在多个场合中遇见了。所以,这一点在使用时需要注意。
- 提示词模板的设置,对于大语言模型输出希望的结果来说至关重要。所以,积累、测试模板,也是一种一项重要的工作。
- 在使用langChain的一些类时,需要注意各个参数值的含义。
最后,希望大家都能将大模型利用起来~~

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









