






URL
https://arxiv.org/pdf/2405.01434
TL;DR
2024 年 5 月份字节新加坡 fengjiashi 团队的作品,主页。面向的是故事生成任务,通过对 self-attention 的创新,实现了一个不需要训练的主体保持+故事生成模型。另外作者还针对长视频故事生成的问题,提出了一种 semantic space temporal motion prediction module,这个模块经过额外的训练之后,可以显著提升视频的连续性,和主体的一致性。

主要贡献:
- 提出 consistent self-attention,不需要训练或者 finetune,可以完成故事生成中的主体保持,同时保留一定的编辑性。
- 针对视频故事生成,提出一种 motion prediction module,输入两张图片,可以生成一个将两张图片串连起来的视频。从而可以生成超过一分钟的长视频。
- 加入了 text 之后,可以快速生成一段连续的故事
Model & Method
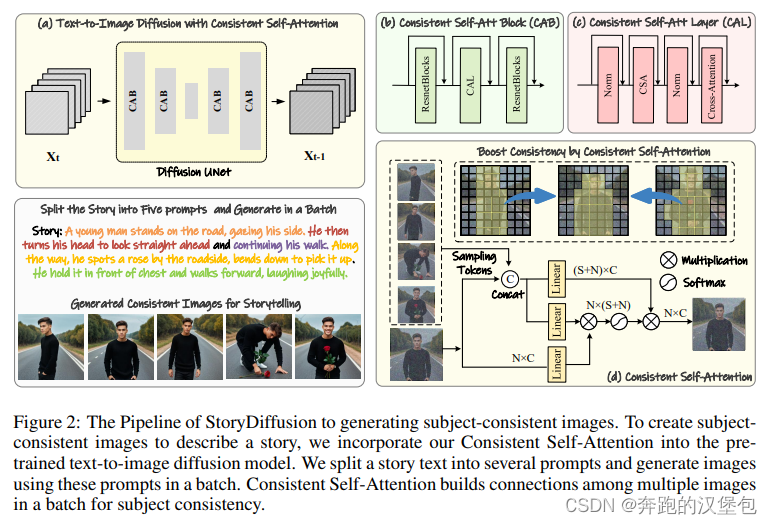
ppl 分为两个部分,第一部分是 self-attention 来实现连续故事图片生成,第二部分是利用本文提出的 motion module + 第一阶段的故事图片来生成完整的故事视频。
-
第一阶段故事图片生成:
思路是原地修改 self-attn,在一次推理过程中,会在 batch 内部做一次特征的随机采样,组成新的 batch 特征组。目的是把 batch 内特征做一次关联,这样batch内每一个特征都可以看到其他特征的信息。随机采样之后,对采样后的特征计算 K、V,采样前的特征计算 Q,完成一次正常的 self-attn 过程。(随机采样过程在这一块没有详细说明,读了一下源码,就是按照一定比例 [0,1] 随机选取特征的像素数值)

-
基于第一阶段的结果,如果用两张图片分别作为首帧和尾帧,生成一段故事视频。这样将多张图片连在一起,就可以生成一段长视频。但是作者表示已有的方法不足以应对这种首尾帧差异比较大的差异情况。主要原因是 motion module 几乎不会考虑到帧间的 pixel 级别的关联,为了解决这个问题,作者提出了以下优化方法:
- 首先,对首帧和尾帧做 clip 得到 img encoder feature
- 对上述 feature,插值获得长度等于视频长度的帧序列
- 针对插值出来的序列,用一个专门训练过的模型来预测得到最终视频转换的帧序列。
- 最后,把上述帧序列作为 condition,和 text 一起 concat 起来之后,送到原本的视频 SD 的 cross attn 中生成最终的视频结果。

以上就是文章核心的思路了,一些实验细节不展开
Dataset & Results
一些结果展示,可以看到本文的结果在主体一致性+编辑性上都是最好的,但是也仍然能看出主体的动作、景别仍然存在趋同的情况。(包括最开始的结果也是),表情的编辑性似乎还可以

视频生成的结果可以参考主页,文章贴的结果如下:



关于batch内采样率的 ablation,单从一张图的结果看没有特别明显的差异,本文最终选用的是 0.5

Thoughts
- 是 Consistent story 类似的思路,对比之下更简单一些。目前看的一些在 self-attn 上操作的方法,基本都是用一些模型以外的思路来做 batch 内的关联。
- 表情的编辑性看起来还不错,景别、动作编辑性存疑
- 一致性确实还不错


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









