






URL
https://arxiv.org/pdf/2403.16990
TD;DR
2024 年 3 月 Snap Research(没听说过这家公司) + 以色列一家大学的文章,目前 1 引用。提出的是一种 training-free 的方法,通过 prompt + location 控制生成多个主体,作者表示提出的方法可以有效避免(外观相似、语义相似的)多主体之间纹理混淆的问题,可以有效独立的控制各个主体生成。

Model & Method
已有方法生成多主体普遍存在纹理混淆的问题,作者认为根本原因是 SD 模型重 attention 层会对多个不同的物体产生混淆(blend)。如下图所示,作者认为多个物体之间的语意信息比较相近的时候,特别容易出现多物体之间的混淆问题。

为了证明自己的观点,作者做了一些统计的实验。分别用 1. 小猫和小狗,2. 仓鼠和松鼠 生成图片:
- 首先分别单独生成两个概念,得到了特征分布(每个点是用 PCA 将 query 投影到 2D 的可视化结果)
- 然后再一起生成两组概念,用了三种方法,最右侧的是本文的方法。

ppl 如下图,正文写的非常啰嗦可以直接直接看图
训练的时候输入 text(包含多个物体),以及每个物体对应的 bbox 信息。每一层都会引导 self-attn、cross-attn 只关注于该物体 bbox 内的特征,通过一组科学的参数引导 bbox 外的特征尽可能为 0。

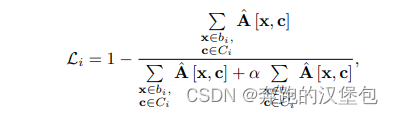
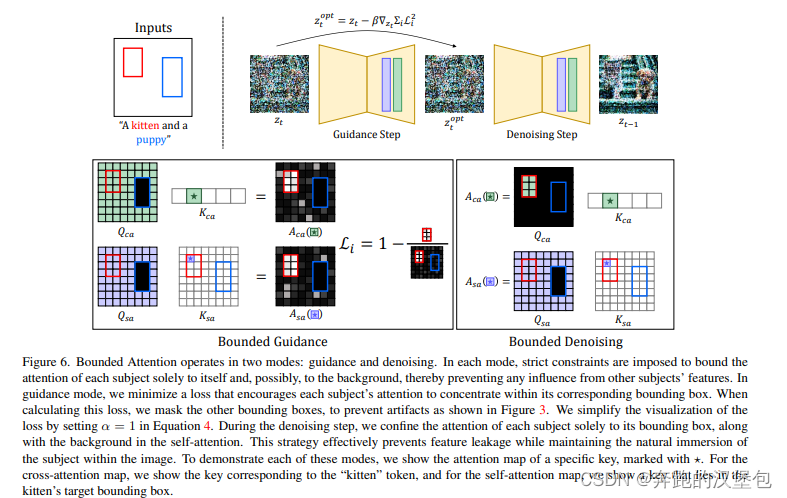
去噪时,bbox 只是提供一个大致的参考位置,给模型用来再前几个 step 生成全局的信息。有了前几个 step 的结果之后,会在此基础上去细化 mask 的形状,后续都是基于此形状进行去噪。
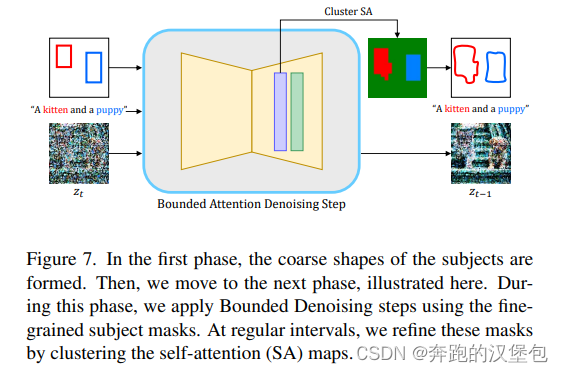

Dataset & Results
部分结果:



Thought
- 感觉这篇文章的 related work 写的不错,后续可以参考里面的相关文献。
- 正文部分写的稀烂。。。开头说是一个 training-free 的方法,写着写着出来一个 loss 看了半天也没看懂在哪里需要用到 这个 loss。
- 仔细想了一下,因为有 bbox 位置的输入,所以所谓的 loss 那一步,是否在 bbox 内的 mask 完全是可以得到准确的权重矩阵,所以不需要额外的训练















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









