






URL
https://arxiv.org/pdf/2404.16771
TD;DR
2024 年 4 月 lenovo 的文章,面向的任务是面部 ID 保持。整篇文章看下来核心应该是提出的面部一致性保持数据集,大约有 50w 张面部图片。另外文章也说提出了一种面部保持的方法(作为 baseline),可以基于一张参考图实现面部一致性生成。核心贡献是优化了面部特征的打标过程,同时引入面部细节的 attention 机制保证面部特征的一致性。

作者表示,已有的方法生成的图片,尽管看上去脸的结果和参考图长得差不多,但是细节的保持做的仍然不够好,如下图(一些细微的特征)

Model & Method
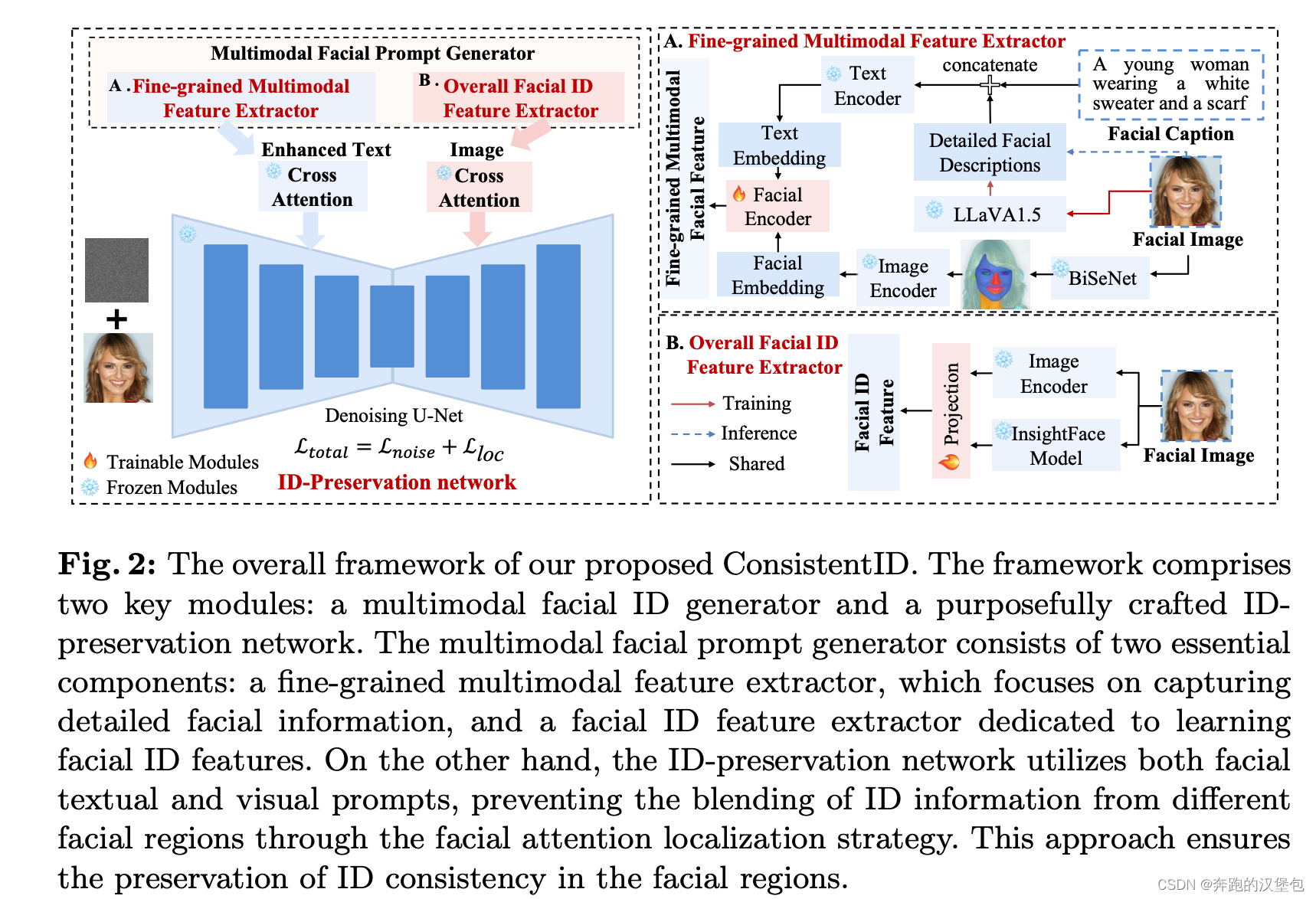
整体 ppl 如下图,包括两部分:
- 面部特征提取,包括细粒度特征和面部 id 特征提取。可以理解为是分别提取外观特征和结构特征。
a. 细粒度特征提取用的是 llava + clip img encoder
b. face id 特征也是一个专用的 img encoder - 图片生成:把第一步得到的两组特征 + caption 一起注入 SD。注入的时候只会针对 cross attn 里面的 mask 区域,否则 cross attn 通常会关注到全局的信息导致注入的信息影响其他区域,同时其他区域的 prompt 也会影响到主体的 mask 区域内
Dataset & Result
数据集方面,本文提出了一个全新的面部 id 保持数据集。
结果展示如下图

Thought
- 这篇论文看的不是特别仔细,有时间得看一下第一部分的面部特征提取 encoder 的结构,也许对 ip 保持也会有用?
- 这种细节和 ID 分开处理的思路,很想结构和外观分开处理的思路,非常像是当前版本的答案















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









