







还是基础哈 自己不劳就弄来学学~~ 图像中的注意力机制
我们知道,输入一张图片,神经网络会提取图像特征,每一层都有不同大小的特征图。如图1所示,展示了 VGG网络在提取图像特征时特征图的大小变化。
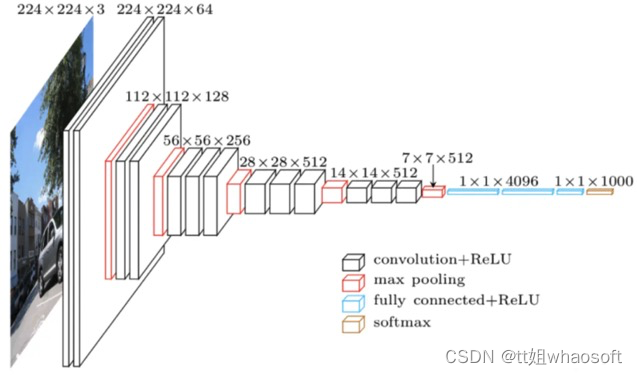
图1 VGG网络特征结构图
其中,特征图常见的矩阵形状为[ C , H , W ](图1中的数字为[ H , W , C ] 格式)。当model在training时,特征图的矩阵形状为[ B , C , H , W ]。其中B表示为batch size(批处理大小),C表示为channels(通道数),H表示为特征图的high(高度),W表示为特征图的weight(宽度)
提问:为什么特征图的维度就是[ B , C , H , W ],而不是其他什么维度格式?
回答:pytorch在处理图像时,读入的图像处理为[ C , H , W ]格式,如果在训练时加入batch size,那么就有多个特征图,将batch size放在第一维,自然就是[ B , C , H , W ]。这是pytorch的处理方式
在网络提取图像特征层时,通过在卷积层之间添加通道注意力机制、空间注意力机制可以增强网络提取图像的能力。在编写代码时,考虑的是特征图间的attention机制,因此代码输入是[ B , C , H , W ]的特征图,输出仍然是[ B , C , H , W ] 维的特征图。让我们接下来通过三篇论文来看这两种注意力机制是如何工作的。
二、SENet
1. 论文介绍
论文名称:Squeeze-and-Excitation Networks
链接:https://arxiv.org/pdf/1709.01507.pdf
SEBlock结构图:
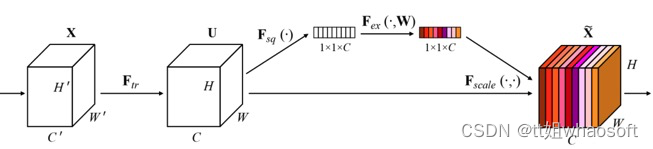
图2 SEBlock结构图

摘要重点:
卷积神经网络(CNN)的核心组成部分是卷积算子,它使网络能够通过融合每层局部感受野中的空间和通道信息来构建信息特征。之前的大量研究已经调查了这种关系的空间成分,并试图通过在CNN的特征层次中提高空间编码的质量来增强CNN。在这项工作中,我们将重点放在通道(channel-wise)关系上,并提出了一个新的名为SE模块的架构单元,它通过显式地建模通道之间的相互依赖性,自适应地重新校准通道特征响应。这些模块可以堆叠在一起形成SENet网络结构,并在多个数据集上非常有效地推广。
SEBlock创新点:
1.SEBlock会给每个通道一个权重,让不同通道对结果有不同的作用力。
2.这个SE模块能够非常方便地添加进目前主流的神经网络当中。
2. 算法解读
图3展示了通道注意力机制的四个步骤,具体如下:
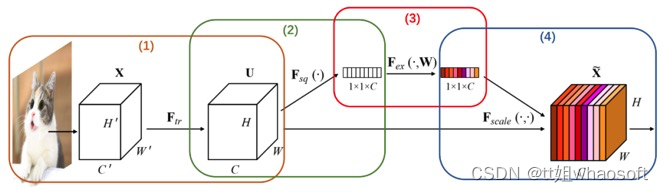
图3 SEBlock模块分析
①.从单张图像开始,提取图像特征,当前特征层U的特征图维度为[ C , H , W ]
②.对特征图的[ H , W ] ]维度进行平均池化或最大池化,池化过后的特征图大小从[ C , H , W ]->[ C , 1 , 1 ]。[ C , 1 , 1 ]可理解为对于每一个通道C,都有一个数字和其一一对应。图4对应了步骤(2)的具体操作。

图4 平均池化(最大池化)操作,得到每个通道的权重,得到每个通道的权重
③.对[ C , 1 , 1 ]的特征可以理解为,从每个通道本身提取出来的权重,权重表示了每个通道对特征提取的影响力,全局池化后的向量通过MLP网络后,其意义为得到了每个通道的权重。图5对应了步骤(3)的具体操作。
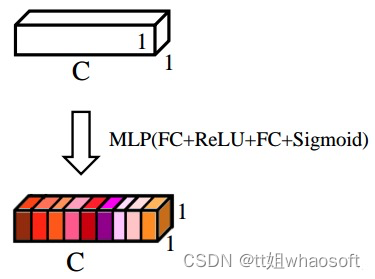
图5 通道权重生成
④.上述步骤,得到了每个通道C的权重[ C , 1 , 1 ],将权重作用于特征图U[ C , H , W ],即每个通道各自乘以各自的权重。可以理解为,当权重大时,该通道特征图的数值相应的增大,对最终输出的影响也会变大;当权重小时,该通道特征图的数值就会更小,对最终输出的影响也会变小。图6对应了步骤(4)的具体操作。
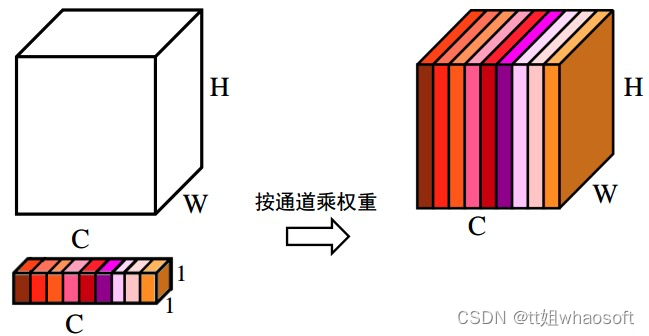
图6 通道注意力——各通道乘以各自不同权重
原论文中给出了通道注意力网络细节,这里展示出来,如图7所示。
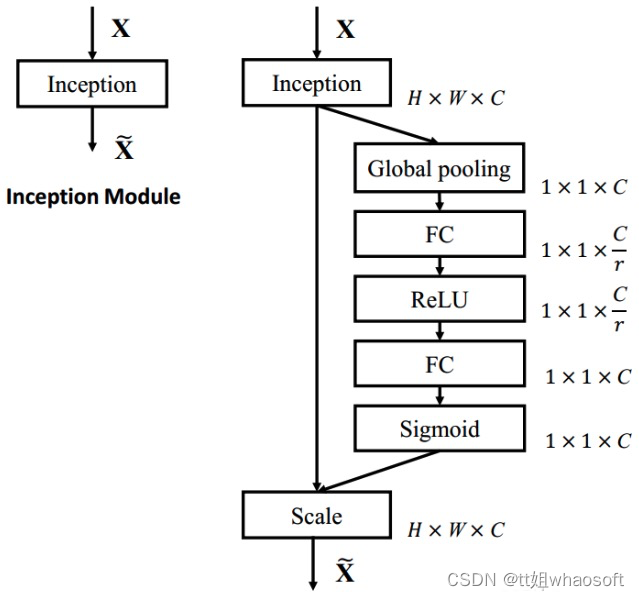
图7 SEBlock实现前(左)后(右)对比
注:文中经过对比实验发现,r 取16的时候效果最好,所以一般默认r = 16,但当通道数很小的时候,需要自己再调整
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









