






Squeeze-and-Excitation Networks
2018发表,2017年获得了分类大赛的冠军
即插即用模块。
论文出发点或背景:
卷积神经网络注重抽取一些特征,用局部感受野来融合空间和通道信息来获取信息。为了促进网络的表达力,一些方法被提出去加强空间编码。为了关注通道关系并提出了一个新架构,就叫SE block。通过模拟通道间的相互依赖关系,自适应地重新校准通道明智的特征响应。(不太理解)
原文:that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels.
通过明确通道间地相互依赖关系/自适应地重新校准通道特征响应。
通过堆叠SE block创造了SENet
最近的研究表明,通过明确嵌入学习机制,可以改善网络性能,这些机制有助于捕捉空间相关性。无需额外监督,一个例子就是:Inception的提出就是为了捕获更好的空间关系。该网络通过在模块中嵌入多尺度过程。
现在更多的研究在更好地模拟空间依赖性,并且纳入了空间注意力。
论文创新思路:
目标:
通过显式地建模其卷积特征通道之间地相互依赖关系来提高网络的表示能力。
SE block的基本架构:

一个基本映射就是:

两个操作:
(1)U又经过一个squeeze操作,通过H*W(空间维度)的特征映射聚合,生成通道描述符,这个描述符嵌入了通道特征响应的全局分布,使得来自网络的全局接受域的信息能够被较低的层利用。(就是将这张图上所有的特征整合起来)
(2)excitation operation:激励操作,通过基于通道依赖性的自门机制莱薇每个通道学习特定于样本的激活,控制每个通道的激励,然后将特征映射U重新加权以生成SE块的输出。(自门机制,依赖性地学习每个通道的激活,控制每个通道的激励程度,简单来说就是学习每个通道对样本的重要性,并根据此来调整通道的激活程度使网络能够自适应地调整每个通道的重要性)
最后,这些重新加权的特征映射生成SE block的输出。
总结:
网络能够更好地利用全局信息,并根据样本的特征动态调整每个通道的重要性,提高网络的性能和泛化能力。
补充知识:
(Batch normalization (BN) [16] improved gradient propagation by inserting units to regulate layer inputs, stabilis ing the learning process.)BN层通过增加unit来规范每层的输入来改善梯度传播。
相关工作:
(1)Deep architectures
-
(提到VGG、inception、BN、resnet、Highway)
另外开始讨论:An alternative line of research has explored ways to tune the functional form of the modular components of a network。多分枝卷积、跨通道相关性。跨信道相关性通常被映射为特征的新组合,要么独立于空间结构[6,20],要么通过联合使用标准卷积滤波器[24]与1×1卷积。
相反,我们声称为单元提供一种机制来明确地建模通道之间的动态非线性依赖可以简化学习过程。
多分支卷积是一种泛化的概念,可以让网络使用更多不同类型的变换操作,提高了网络的灵活性。
最近一些研究表明,通过学习自动化的操作符组合可以取得竞争性的性能,这表明了学习到的操作符可以比手工设计更有效。
讨论了通道之间的交叉关系,通常被映射为新的特征组合。一些方法旨在降低模型和计算复杂性,因为它们假设通道之间的关系可以被一组与局部感受野无关的函数组合表示。
作者提出了一种相反的观点,认为通过引入全局信息来建模通道之间的动态关系,可以更有效地学习到特征之间的复杂依赖关系,从而提高网络的性能。
(2)Attention and gating mechanisms.
注意和门控机制。广义地说,注意力可以被视为一种工具,使可用处理资源的分配偏向于输入信号中信息最丰富的成分。这种机制的好处已经在一系列任务中得到了证明,从图像[3,19]中的本地化和理解到基于序列的模型[2,28]。它通常是内爆的 结合门控功能(例如软max或s型)和顺序技术[12,41]。最近的研究表明,它适用于图像字幕[4,48]和唇部回复等任务 ading [7].在这些应用程序中,它通常用于一个或多个层次上,表示适应模式之间的更高级抽象。Wang等人。[46]介绍了一个强大的集群 -使用沙漏模块[31]屏蔽注意机制。这个高容量的单元被插入到中间阶段之间的深度剩余网络中。相比之下,我们提出的SE块是一个轻条件 Ht门控机制,专门以一种计算效率高的方式建模通道关系,旨在增强整个网络中基本模块的表征能力。
具体实现方法和效果:
3.1. Squeeze: Global Information Embedding
每个学习到的过滤器都有一个局部接受域,因此转换输出U的每个单元都无法利用该区域之外的上下文信息。所以第一步就是先整合这些信息。生成一个统计量()
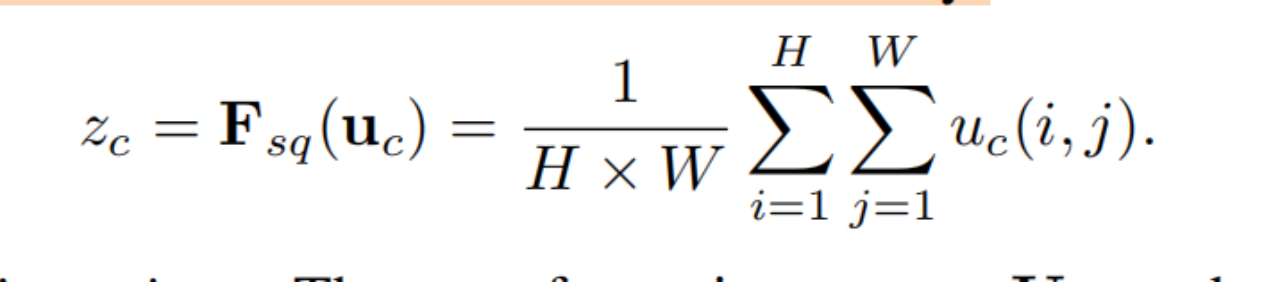
3.2. Excitation: Adaptive Recalibration
第二步:整合信息完成后对信息进行挤压。去寻找一个函数,这个函数需要满足两点:
该函数必须满足两个标准:首先,它必须是灵活的(特别是,它必须能够学习通道之间的非线性交互),其次,它必须学习一个非相互排斥的功能,难以捉摸的关系,因为我们希望确保多个通道被允许被强调,而不是一个热激活。

为了限制模型的复杂性并泛化模型,通过形成一个瓶颈来参数化门控机制,在非线性引入两个FC。

实现:
Optimisation is performed using synchronous SGD with momentum 0.9 and a mini-batch size of 1024. The initial learning rate is set to 0.6 and decreased by a factor of 10 every 30 epochs.















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









