







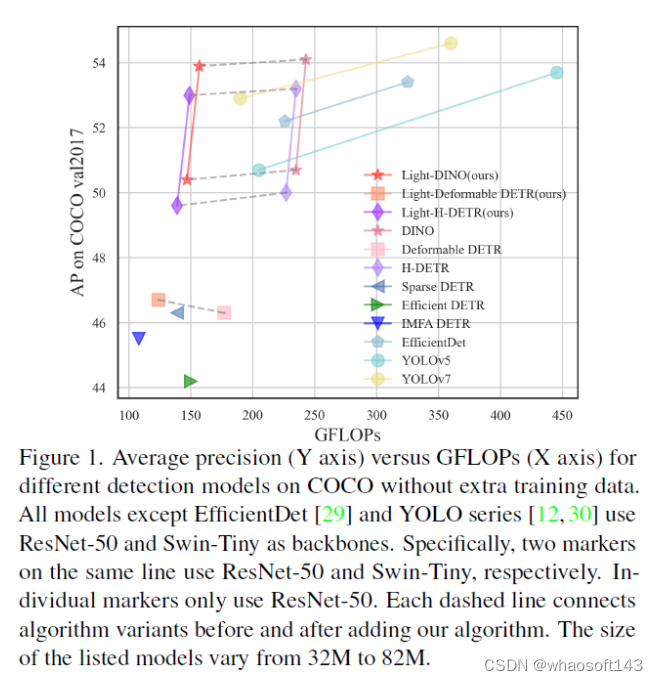
这是一种简单而高效的端到端目标检测框架,可以有效地将检测头的GFLOPs减少60%,同时保持99%的原始性能。高效交错多尺度编码器
最近基于DEDetection-TRansformer(DETR)的模型已经获得了显著的性能。如果不在编码器中重新引入多尺度特征融合,它的成功就无法实现。然而,多尺度特征中过度增加的标记,特别是对于大约75%的低级别特征,在计算上效率很低,这阻碍了DETR模型的实际应用。本文提出了Lite DETR,这是一种简单而高效的端到端目标检测框架,可以有效地将检测头的GFLOPs减少60%,同时保持99%的原始性能。具体而言,论文设计了一个高效的编码器块,以交错的方式更新高级特征(对应于小分辨率特征图)和低级特征(对应于大分辨率特征图)。此外,为了更好地融合多尺度特征,论文开发了一种key-aware的可变形注意力来预测更可靠的注意力权重。综合实验验证了所提出的Lite DETR的有效性和效率,并且高效的编码器策略可以很好地推广到现有的基于DETR的模型中。
 论文链接:https://arxiv.org/abs/2303.07335
论文链接:https://arxiv.org/abs/2303.07335
代码链接:https://github.com/IDEA-Research/Lite-DETR
目标检测旨在通过定位图像中的边界框并预测相应的分类分数来检测图像中感兴趣的目标。在过去的十年里,许多基于卷积网络的经典检测模型[23,24]取得了显著进展。最近,DEtection TRansformer[1](DETR)将Transformers引入到目标检测中,类似DETR的模型在许多基本视觉任务上都取得了很好的性能,如目标检测[13,36,37]、实例分割[5,6,14]和姿态估计[26,28]。
从概念上讲,DETR[1]由三部分组成:主干、Transformer编码器和Transformer解码器。许多研究工作一直在改进主干和解码器部分。例如,DETR中的主干通常是继承的,并且可以在很大程度上受益于预训练的分类模型[10,20]。DETR中的解码器部分是主要的研究重点,许多研究工作试图为DETR查询引入适当的结构,并提高其训练效率[11,13,18,21,36,37]。相比之下,在改进编码器部分方面所做的工作要少得多。朴素DETR中的编码器包括六个Transformer编码器层,它们堆叠在主干的顶部,以改进其特征表示。与经典的检测模型相比,它缺乏多尺度特征,这些特征对物体检测至关重要,尤其是对小目标的检测[9,16,19,22,29]。简单地在多尺度特征上应用Transformer编码器层是不可行的,因为计算成本是特征token数量的二次方。例如,DETR使用C5特征图来应用Transformer编码器,C5特征图是输入图像分辨率的1/32。如果C3特征(1/8比例)包括在多尺度特征中,则仅来自该比例的标记的数量将是来自C5特征图的标记的16倍。Transformer中自注意力的计算成本将高出256倍。
为了解决这个问题,Deformable DETR[37]开发了一种可变形注意力算法,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









