






问题篇
博主在进行DINO-DETR模型实验时,使用缩减后的COCO数据集进行训练,发现其mAP值只能达到0.27作用,故而修改了下pycocotool的代码,令其输出每个类别的AP值,来看看是由于什么原因导致这个问题。
之所以这样是因为博主认为各类别的AP值是不均匀的,必定由学得好的与学得不好的。
参数设置:batch-size=1,lr=0.00005
使用22个epoch中训练结果最好的那个进行验证,结果如下:
【truck,car,bus】
分别为0.02,0.11,0.70,map为0.28
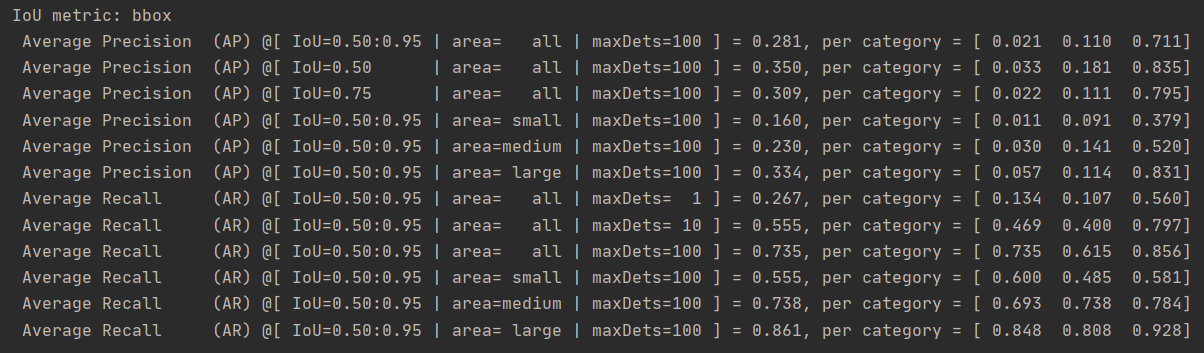
batch-size=2,lr=0.0001,epoch=24。结果如下:
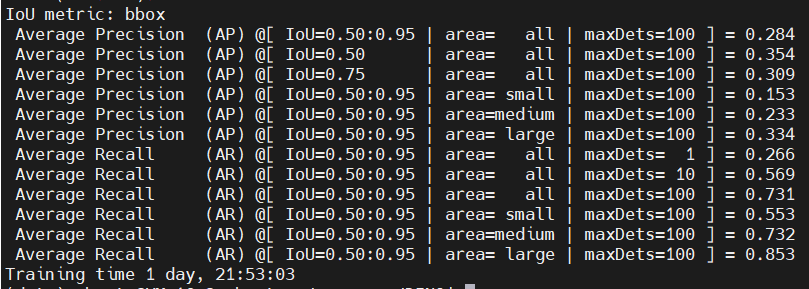
随后使用官方给定的训练后的模型进行测试:
【'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck'】
对应car,bus,truck为:0.49,0.72,0.42,map值为0.54
上述实验结果首先证明了博主的猜想,即各个类别的AP值是不同的,也就说明其并非是对所有类别信息都有一个较好的结果。
其次尝试分析一下造成这个问题的原因。
首先在我们缩小的COCO数据集上,尽管car的标注较多,但目标都较小,而且存在很大程度的遮挡。且car在出现时背景复杂多变(有时是通过窗户看到,有时出现在马路上,有时旁边出现其他的物体),周边出现多种信息。
而bus尽管数量上并不占优,但其在出现时特征较为明显,显示较为完整,且出现时背景较为固定。(多为公路上出现)故而其学习效果较好。
博主选择了几个具有代表性的图像进行展示,用以证实博主上面的猜想。

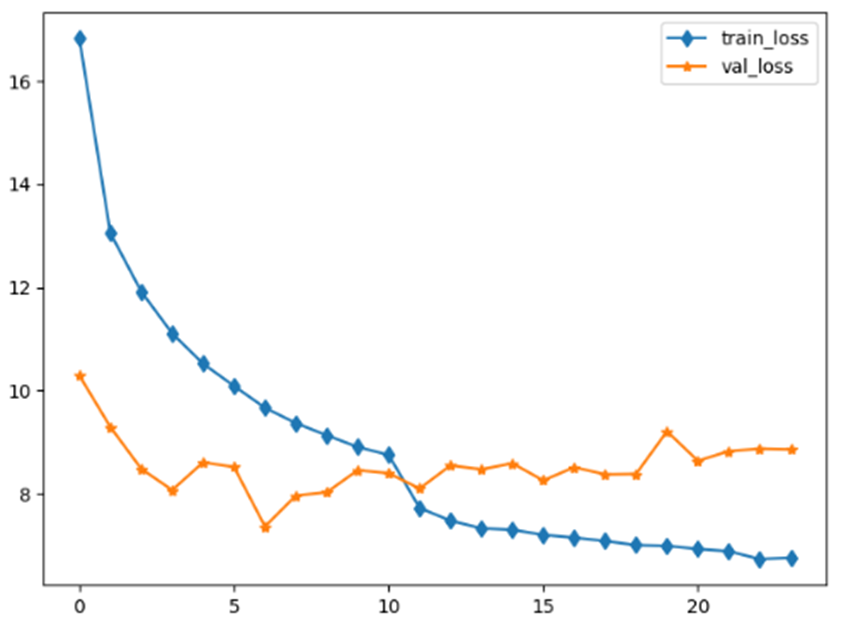
输出训练过程中loss值变化情况:
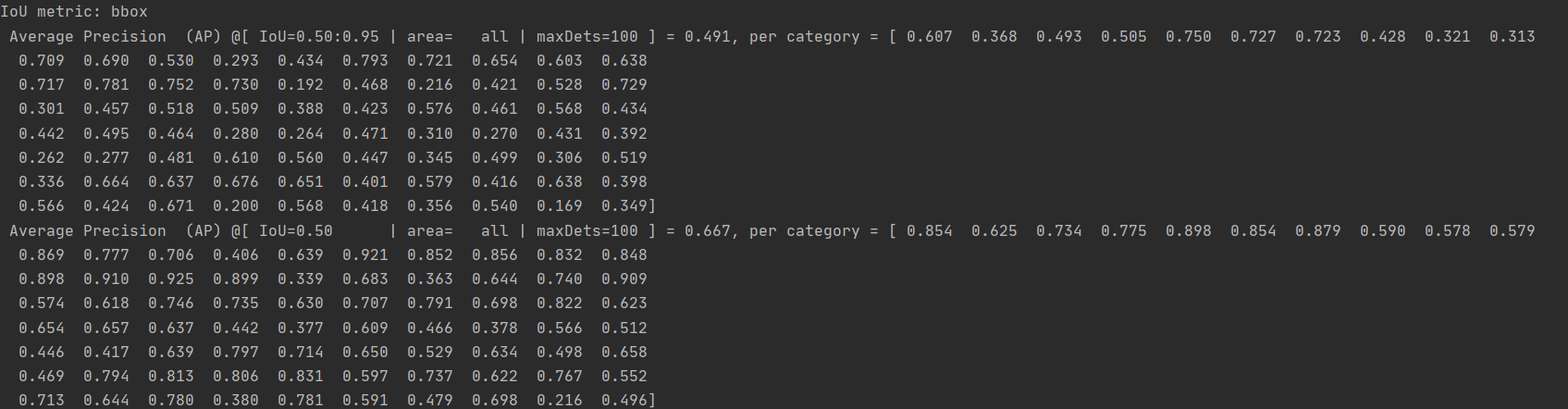
使用DINO-DETR官方给定的权重模型来验证完整COCO数据集,完整结果如下:
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.491, per category = [ 0.607 0.368 0.493 0.505 0.750 0.727 0.723 0.428 0.321 0.313
0.709 0.690 0.530 0.293 0.434 0.793 0.721 0.654 0.603 0.638
0.717 0.781 0.752 0.730 0.192 0.468 0.216 0.421 0.528 0.729
0.301 0.457 0.518 0.509 0.388 0.423 0.576 0.461 0.568 0.434
0.442 0.495 0.464 0.280 0.264 0.471 0.310 0.270 0.431 0.392
0.262 0.277 0.481 0.610 0.560 0.447 0.345 0.499 0.306 0.519
0.336 0.664 0.637 0.676 0.651 0.401 0.579 0.416 0.638 0.398
0.566 0.424 0.671 0.200 0.568 0.418 0.356 0.540 0.169 0.349]
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.667, per category = [ 0.854 0.625 0.734 0.775 0.898 0.854 0.879 0.590 0.578 0.579
0.869 0.777 0.706 0.406 0.639 0.921 0.852 0.856 0.832 0.848
0.898 0.910 0.925 0.899 0.339 0.683 0.363 0.644 0.740 0.909
0.574 0.618 0.746 0.735 0.630 0.707 0.791 0.698 0.822 0.623
0.654 0.657 0.637 0.442 0.377 0.609 0.466 0.378 0.566 0.512
0.446 0.417 0.639 0.797 0.714 0.650 0.529 0.634 0.498 0.658
0.469 0.794 0.813 0.806 0.831 0.597 0.737 0.622 0.767 0.552
0.713 0.644 0.780 0.380 0.781 0.591 0.479 0.698 0.216 0.496]
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.536, per category = [ 0.660 0.353 0.531 0.537 0.822 0.799 0.812 0.481 0.303 0.312
0.802 0.742 0.564 0.315 0.447 0.836 0.778 0.730 0.664 0.706
0.790 0.833 0.841 0.791 0.199 0.510 0.219 0.462 0.585 0.860
0.268 0.515 0.592 0.572 0.416 0.461 0.621 0.500 0.626 0.488
0.465 0.547 0.500 0.291 0.291 0.525 0.333 0.298 0.476 0.426
0.268 0.302 0.501 0.680 0.615 0.497 0.365 0.536 0.341 0.527
0.351 0.729 0.715 0.741 0.775 0.480 0.635 0.446 0.738 0.412
0.713 0.417 0.746 0.187 0.634 0.437 0.363 0.579 0.200 0.428]
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.327, per category = [ 0.409 0.223 0.388 0.338 0.704 0.394 0.449 0.238 0.246 0.267
0.448 0.346 0.263 0.184 0.315 0.396 0.494 0.351 0.438 0.531
0.516 0.681 0.612 0.457 0.206 0.302 0.185 0.324 0.383 0.666
0.292 0.332 0.482 0.519 0.410 0.382 0.461 0.315 0.478 0.326
0.279 0.333 0.301 0.204 0.244 0.263 0.159 0.095 0.121 0.227
0.154 0.204 0.314 0.385 0.423 0.324 0.255 0.131 0.195 0.029
0.055 0.069 0.332 0.194 0.546 0.349 0.284 0.288 0.250 0.113
0.532 0.296 0.800 0.164 0.459 0.275 0.115 0.176 0.131 0.309]
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.524, per category = [ 0.675 0.427 0.637 0.456 0.735 0.578 0.348 0.455 0.370 0.512
0.722 0.729 0.459 0.263 0.619 0.763 0.726 0.645 0.647 0.675
0.661 0.781 0.722 0.770 0.189 0.514 0.288 0.554 0.510 0.817
0.416 0.688 0.806 0.556 0.465 0.503 0.693 0.537 0.638 0.588
0.589 0.620 0.629 0.456 0.354 0.517 0.333 0.441 0.276 0.433
0.303 0.359 0.599 0.511 0.614 0.505 0.387 0.382 0.372 0.197
0.199 0.573 0.608 0.573 0.752 0.561 0.583 0.545 0.614 0.325
0.538 0.484 0.415 0.292 0.678 0.490 0.465 0.496 0.279 0.403]
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.630, per category = [ 0.796 0.650 0.734 0.659 0.784 0.864 0.767 0.572 0.507 0.613
0.856 0.961 0.780 0.492 0.817 0.813 0.760 0.809 0.720 0.779
0.789 0.810 0.849 0.778 0.274 0.621 0.155 0.701 0.742 0.894
0.221 0.541 0.686 0.421 0.027 0.583 0.548 0.664 0.575 0.697
0.789 0.729 0.594 0.423 0.440 0.639 0.543 0.438 0.576 0.601
0.285 0.342 0.603 0.732 0.817 0.539 0.484 0.563 0.324 0.554
0.470 0.734 0.748 0.807 0.802 0.634 0.684 0.692 0.783 0.490
0.824 0.485 0.740 0.401 0.619 0.650 0.535 0.704 0.482 0.830]
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.379, per category = [ 0.205 0.289 0.192 0.299 0.583 0.562 0.668 0.396 0.158 0.146
0.680 0.719 0.427 0.290 0.215 0.769 0.664 0.400 0.141 0.192
0.294 0.589 0.279 0.386 0.253 0.283 0.252 0.348 0.231 0.615
0.243 0.446 0.450 0.196 0.387 0.388 0.527 0.360 0.502 0.254
0.208 0.314 0.441 0.276 0.292 0.352 0.148 0.159 0.382 0.174
0.110 0.111 0.262 0.429 0.149 0.273 0.188 0.522 0.271 0.596
0.425 0.604 0.555 0.614 0.609 0.310 0.515 0.443 0.704 0.444
0.722 0.440 0.606 0.090 0.483 0.310 0.450 0.382 0.409 0.304]
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.651, per category = [ 0.613 0.509 0.588 0.606 0.830 0.811 0.832 0.705 0.454 0.459
0.819 0.816 0.725 0.508 0.445 0.902 0.861 0.738 0.608 0.642
0.765 0.894 0.784 0.800 0.506 0.602 0.503 0.540 0.597 0.813
0.481 0.633 0.605 0.557 0.608 0.564 0.699 0.599 0.729 0.574
0.568 0.649 0.680 0.522 0.561 0.701 0.434 0.493 0.751 0.531
0.417 0.435 0.634 0.725 0.577 0.577 0.512 0.789 0.577 0.793
0.652 0.813 0.790 0.800 0.756 0.619 0.779 0.650 0.827 0.665
0.822 0.666 0.814 0.299 0.743 0.628 0.639 0.704 0.600 0.570]
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.727, per category = [ 0.735 0.599 0.682 0.704 0.877 0.837 0.865 0.791 0.604 0.537
0.824 0.820 0.792 0.612 0.599 0.909 0.869 0.809 0.766 0.792
0.871 0.904 0.865 0.857 0.590 0.718 0.587 0.597 0.721 0.823
0.590 0.686 0.650 0.700 0.695 0.596 0.739 0.666 0.759 0.682
0.643 0.734 0.718 0.592 0.624 0.767 0.659 0.640 0.792 0.694
0.626 0.609 0.742 0.792 0.748 0.733 0.658 0.848 0.651 0.845
0.718 0.857 0.803 0.832 0.759 0.682 0.783 0.672 0.827 0.706
0.822 0.707 0.850 0.526 0.764 0.709 0.650 0.769 0.709 0.607]
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.563, per category = [ 0.575 0.433 0.587 0.553 0.777 0.550 0.675 0.662 0.490 0.491
0.648 0.644 0.619 0.435 0.486 0.625 0.616 0.627 0.630 0.678
0.753 0.840 0.717 0.677 0.522 0.532 0.483 0.475 0.561 0.752
0.510 0.542 0.612 0.648 0.609 0.531 0.597 0.524 0.644 0.594
0.516 0.611 0.574 0.502 0.517 0.592 0.490 0.460 0.372 0.520
0.431 0.492 0.536 0.581 0.631 0.544 0.518 0.344 0.491 0.700
0.305 0.386 0.533 0.565 0.660 0.619 0.394 0.534 0.525 0.340
0.900 0.502 0.800 0.449 0.666 0.565 0.362 0.428 0.600 0.556]
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.767, per category = [ 0.800 0.687 0.812 0.684 0.879 0.768 0.656 0.795 0.663 0.710
0.823 0.833 0.762 0.650 0.799 0.832 0.868 0.793 0.791 0.830
0.821 0.846 0.838 0.831 0.686 0.750 0.728 0.757 0.747 0.920
0.805 0.904 0.933 0.815 0.808 0.710 0.838 0.727 0.802 0.805
0.764 0.836 0.829 0.761 0.834 0.790 0.682 0.744 0.754 0.737
0.632 0.705 0.800 0.759 0.801 0.756 0.708 0.759 0.688 0.464
0.598 0.768 0.786 0.734 0.845 0.853 0.782 0.809 0.824 0.635
0.760 0.751 0.750 0.721 0.837 0.785 0.767 0.739 0.633 0.661]
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.883, per category = [ 0.900 0.852 0.919 0.825 0.919 0.933 0.892 0.899 0.867 0.868
0.932 0.985 0.939 0.815 0.933 0.934 0.905 0.916 0.889 0.931
0.920 0.925 0.945 0.924 0.650 0.905 0.790 0.905 0.882 0.938
0.975 0.780 0.757 0.814 0.800 0.633 0.900 0.879 0.958 0.917
0.929 0.908 0.932 0.838 0.857 0.922 0.881 0.887 0.910 0.894
0.769 0.762 0.900 0.882 0.952 0.878 0.882 0.897 0.813 0.882
0.885 0.917 0.890 0.933 0.922 0.893 0.907 0.939 0.900 0.795
0.900 0.848 0.879 0.832 0.864 0.916 0.843 0.914 0.967 0.900]
解决篇
简直是大无语,博主在检查数据集时终于发现了问题:尽管在train是class损失已经降了下来,但在val时损失却总是居高不下,这不免让我产生了怀疑:难道是我的类别这块出现了问题,随后统计了下train与val中样本的数量:
很明显truck和car的train_num与val_num是不匹配的,这大概便是症结所在,再次查看数据集标注文件,果然是这里出现了问题,truck与car在val数据集中表反了。呜呜呜,搞了那么久,自己还在那乱想,原来是数据集出现了问题,啊啊啊啊。

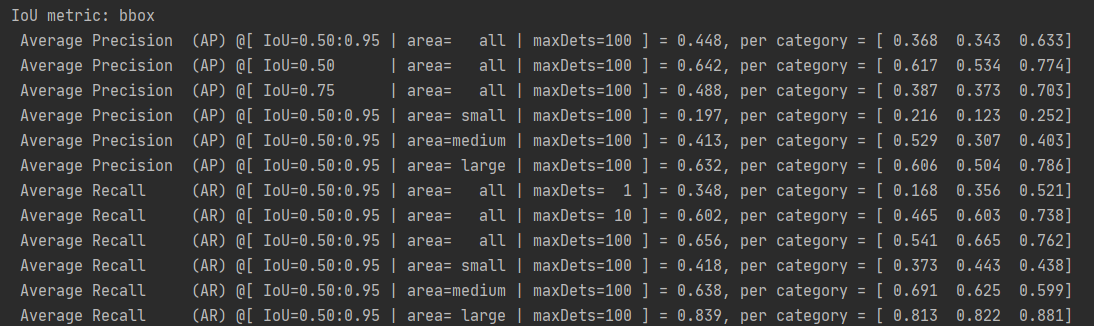
随后重新制作了数据集,问题解决:

















 7084
7084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











