







Title: EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
Paper: https://arxiv.org/pdf/2305.07027v1.pdf
Code: https://github.com/microsoft/Cream/tree/main/EfficientViT
本文介绍了一种名为EfficientViT的高效视觉Transformer模型,旨在解决传统Vision Transformer模型在计算成本方面存在的问题,使其适用于实时应用。
最近有几项工作设计了轻便高效的Vision transformers模型。不幸的是,这些方法大多旨在减少模型参数或Flops,这是速度的间接指标,不能反映模型的实际推理吞吐量。例如,在Nvidia V100 GPU上,使用700M浮点的MobileViT XS比使用1220M浮点的DeiT-T运行得慢得多。尽管这些方法以较少的Flops或参数获得了良好的性能,但与标准同构或分级transformer(例如DeiT和Swin)相比,它们中的许多方法并没有显示出显著的壁时钟加速,并且没有得到广泛采用。
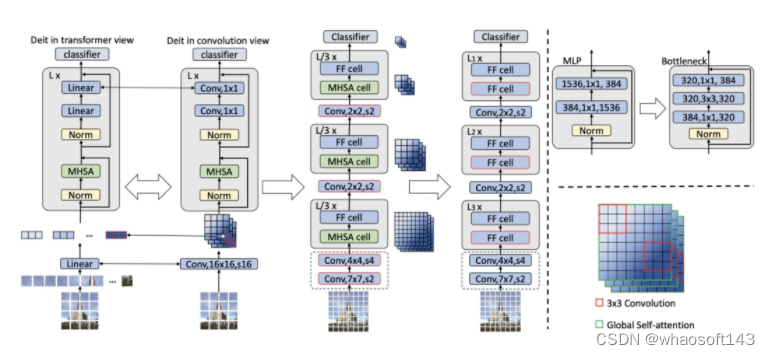
为了解决这个问题,研究者探讨了如何更快地使用Vision transformers,试图找到设计高效transformer架构的原则。基于主流的Vision transformers DeiT和Swin,系统地分析了影响模型推理速度的三个主要因素,包括内存访问、计算冗余和参数使用。特别是,发现transformer模型的速度通常是内存限制的。
基于这些分析和发现,研究者提出了一个新的存储器高效transformer模型家族,命名为EfficientViT。具体来说,设计了一个带有三明治布局的新块来构建模型。三明治布局块在FFN层之间应用单个存储器绑定的MHSA层。它减少了MHSA中内存绑定操作造成的时间成本,并应用了更多的FFN层来允许不同信道之间的通信,这更具内存效率。然后,提出了一种新的级联群注意力(CGA)模块来提高计算效率。其核心思想是增强输入注意力头部的特征的多样性。与之前对所有头部使用相同特征的自我注意不同,CGA为每个头部提供不同的输入分割,并将输出特征级联到头部之间。该模块不仅减少了多头关注中的计算冗余,而且通过增加网络深度来提高模型容量。
众所周知,传统Transformer模型的速度通常受限于内存效率低下的操作,尤其是在多头自注意力机制(MHSA)中的张量重塑和逐元素函数。为了提高内存效率并增强通道间的通信,本文设计了一种新的构建块,采用了"三明治布局(sandwich layout)"策略,即在高效的前馈神经网络FFN层之间使用了一个受内存限制的MHSA。
此外,作者还发现在自注意力机制中,不同头部之间的注意力图具有高度的相似性,导致计算冗余。为了解决这个问题&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8081
8081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









