







 OpenScene是一种使用CLIP特征的零样本方法,用于开放词汇的3D场景理解,包括语义分割、材料识别和功能理解等任务。该方法通过将3D点与图像像素和文本嵌入对齐,实现了无监督的训练和多样化的查询能力,甚至在多类别任务中超越了完全监督的模型。
OpenScene是一种使用CLIP特征的零样本方法,用于开放词汇的3D场景理解,包括语义分割、材料识别和功能理解等任务。该方法通过将3D点与图像像素和文本嵌入对齐,实现了无监督的训练和多样化的查询能力,甚至在多类别任务中超越了完全监督的模型。
用于开放词汇的三维场景理解的简单而有效的零样本方法OpenScene,在具有40、80或160个类别的室内3D语义分割上,击败完全监督的方法。
论文地址:https://arxiv.org/abs/2211.15654
项目地址:https://github.com/pengsongyou/openscene
传统的3D场景理解方法依赖于标记的3D数据集,以监督的方式训练模型来执行单个任务。而作者提出了一种替代方法OpenScene,这是一个针对三维场景的开放词袋查询模型。其中模型预测了在CLIP特征空间中与文本和图像像素共嵌入的3D场景点的密集特征。这种零样本方法实现了与任务无关的训练和开放词汇查询。例如,要执行SOTA零样本3D语义分割,它首先推断每个3D点的CLIP特征,然后基于与任意类标签嵌入的相似性对它们进行分类。更有趣的是,它能够实现一系列从未尝试过的开放词汇场景理解应用。例如,它允许用户输入任意文本查询,然后查看热图来指示场景的哪些部分匹配。方法能够在复杂的3D场景中识别对象、材料、可利用性、活动和房间类型,所有这些都使用同一个模型进行训练,而不需要任何标记的3D数据。 Introduction
Introduction
三维场景理解是计算机视觉中的一项基本任务。给定一个带有一组位姿以及RGB信息的三维网格或点云,目标是推断每个三维点的语义、可利用性、功能和物理特性。例如,在上图中所示的房子中,我们想要预测哪些表面是风扇的一部分(语义)、由金属制成(材料)、在厨房内(房间类型)、一个人可以坐的地方(可利用性)、一个人可以工作的地方(功能),以及哪些表面是软的(物理特性)。这些问题的答案可以帮助机器人与场景进行智能交互,或通过交互式查询和可视化帮助人们理解它。
然而由于现实中的查询有多种可能,实现这一广泛的场景理解目标是具有挑战性的。传统的3D场景理解系统是通过针对特定任务设计的基准数据集的监督训练而得到的(例如,针对20个类别的封闭集合的3D语义分割)。它们每个都设计用于回答一种类型的查询(这个点是在椅子、桌子还是床上吗?),但对于训练数据稀缺的相关查询(例如,分割罕见的物体)或没有3D监督的其他查询(例如,估计材料特性),提供的帮助很少。
本文研究如何利用预训练的文本-图像嵌入模型(例如CLIP)来辅助三维场景理解。这些模型是从带有标题的大型图像数据集中训练出来的,以在共享特征空间中共同编码视觉和语言概念。最近的研究表明,这些模型可以用于增加二维图像语义分割的灵活性和泛化能力。然而,没有人研究如何利用它们来改善三维场景理解任务。
作者提出了一种名为OpenScene的简单而有效的零样本方法,用于开放词汇的三维场景理解。作者的关键思路是使用文本字符串和图像像素共同编码的,在CLIP特征空间中的三维点的密集特征(如下图所示)。为了实现这一目标,作者建立了3D场景中的3D点与位姿图像中的像素之间的关联,并训练一个3D网络,使用CLIP像素特征作为监督来编码3D点。这种方法将3D点与特征空间中的像素对齐,进而与文本特征对齐,从而实现对3D点的开放词汇查询。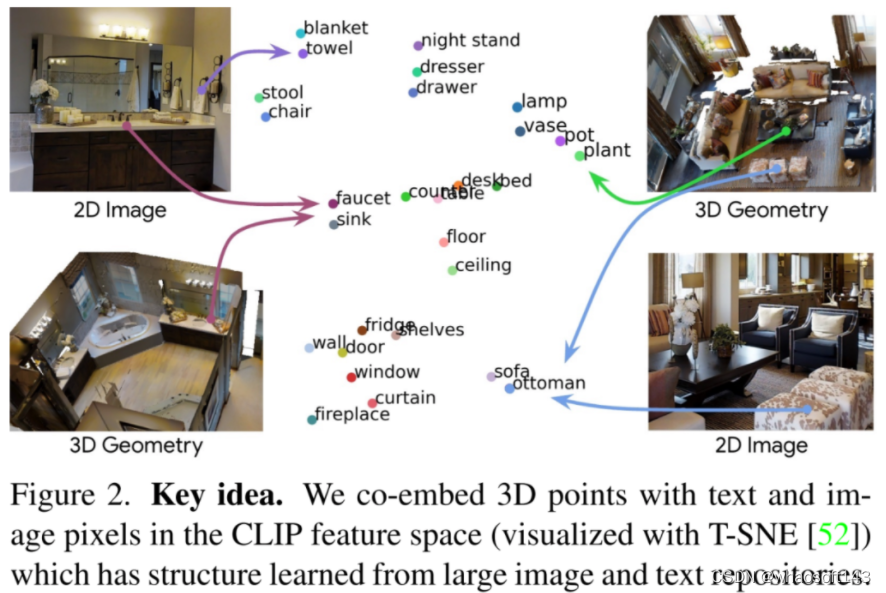 作者的3D点嵌入算法包括2D和3D卷积。首先,作者将点的3D位置反投影到每个图像中,并使用多视角融合聚合相关像素的特征。接下来,我们训练一个稀疏的3D卷积网络,仅从3D点云几何形状中进行特征提取,并使用最小化与聚合像素特征之间差异的损失。最后,作者将2D融合和3D网络产生的特征组合成每个3D点的单个特征。这种混合的2D-3D特征策略使算法能够利用2D图像和3D几何中的显著模式,因此比单个域中的特征更具有鲁棒性和描述性。
作者的3D点嵌入算法包括2D和3D卷积。首先,作者将点的3D位置反投影到每个图像中,并使用多视角融合聚合相关像素的特征。接下来,我们训练一个稀疏的3D卷积网络,仅从3D点云几何形状中进行特征提取,并使用最小化与聚合像素特征之间差异的损失。最后,作者将2D融合和3D网络产生的特征组合成每个3D点的单个特征。这种混合的2D-3D特征策略使算法能够利用2D图像和3D几何中的显著模式,因此比单个域中的特征更具有鲁棒性和描述性。
一旦计算出了每个3D点的特征,我们就可以执行各种3D场景的理解查询任务了。由于CLIP模型是使用自然语言标题进行训练的,因此它捕捉到了超越物体类别标签的概念,包括可供性、材料、属性和功能。例如,将3D特征与“软”的Embeddings计算相似度会产生图文章开头所示图片的结果,突出显示沙发、床和舒适的椅子是最佳匹配项。
由于作者的方法是零样本的(即不使用目标任务的标记数据),因此在传统基准测试中的有限任务集上,它的性能不如完全监督的方法(例如具有20个类别的3D语义分割)。但是,在其他任务上它表现出明显更强的性能。例如,在具有40、80或160个类别的室内3D语义分割上,它击败了完全监督的方法。它也比其他零样本baseline表现更好,并且可以在新的数据集上使用,即使它们具有不同的标签集,也无需重新训练。它适用于室内RGBD扫描以及室外驾驶捕获。
Method
作者方法的概述如下图所示。首先使用一个预训练的面向开放词汇的2D语义分割模型为每个图像计算每个像素的特征。然后,作者将多视图的像素特征聚合到每个3D点上,形成每个点的融合特征向量(Image Feature Fusion)。接下来,作者使用仅接受3D点云作为输入的3D网络来提炼出这些融合特征(3D Distillation)。我们将融合的2D特征和提炼的3D特征组合成单个点特征(2D-3D Feature Ensemble),并使用它来回答开放词汇的查询(Inference)。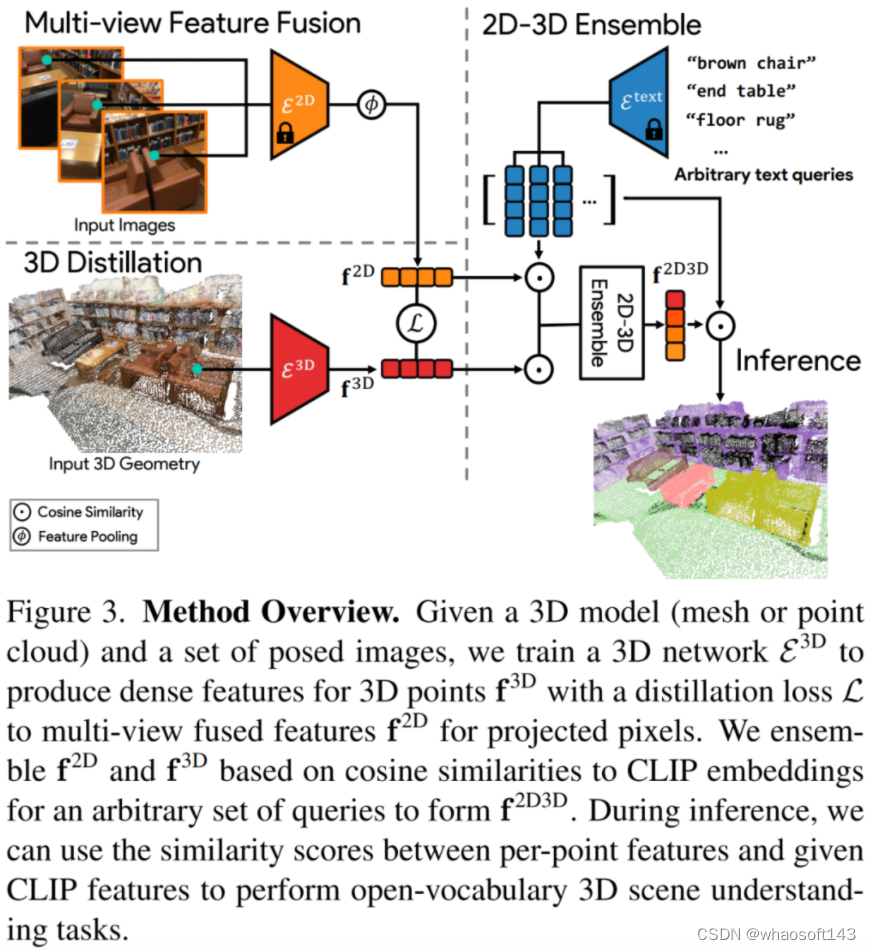 1. Image Feature Fusion
1. Image Feature Fusion
 2. 3D Distillation
2. 3D Distillation  3. 2D-3D Feature Ensemble
3. 2D-3D Feature Ensemble
simply the feature with the highest ensemble score. whaosoft aiot http://143ai.com 4. Inference
4. Inference 探索
探索
最后,作者探索是否可以查询3D场景以了解超出类别标签的属性。由于CLIP嵌入空间是用大规模文本语料库训练的,它可以表示远远不止类别标签-它可以编码物理属性、表面材料、人类可利用性、潜在功能、房间类型等等。我们假设我们可以使用我们的3D点与CLIP特征的共同嵌入来发现关于场景的这些类型的信息。
下图展示了有关物理属性、表面材料和活动潜在地点的查询示例结果。从这些示例中,我们可以发现OpenScene确实能够将单词与场景的相关区域关联起来-例如,床、沙发和软垫椅与“Comfy”相匹配,烤箱和壁炉与“Hot”相匹配,钢琴键盘与“Play”相匹配。这种多样化的3D场景理解将很难通过完全监督的方法实现,而这需要进行大量的3D标注工作。在作者看来,这是本论文最有趣的结果。
讨论
总结一下,本文介绍了一种与任务无关的方法,将3D点与文本和图像像素一起嵌入到特征空间中,并展示了它在零样本、开放词汇量的3D场景理解中的实用性。它在标准基准测试上实现了零样本3D语义分割的最新水平,在具有许多类标签的3D语义分割中优于监督方法,并使得新的开放词汇量应用程序可以使用任意文本和图像查询来查询3D场景,而无需使用任何标记的3D数据。这些结果为3D场景理解提供了一个新的方向,即通过从大规模多模态数据集中训练的基础模型引导3D场景理解系统,而不仅仅是使用小型标记的3D数据集进行训练。

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









