







传统的3D场景理解方法依赖于带标签的3D数据集,用于训练一个模型以进行单一任务的监督学习。我们提出了OpenScene,一种替代方法,其中模型在CLIP特征空间中预测与文本和图像像素共同嵌入的3D场景点的密集特征。这种零样本方法实现了与任务无关的训练和开放词汇查询。例如,为了执行最先进的零样本 3D语义分割,它首先推断每个3D点的CLIP特征,然后根据与任意类别标签的嵌入的相似性对它们进行分类。更有趣的是,它实现了一系列以前从未实现过的开放词汇场景理解应用。例如,它允许用户输入任意文本查询,然后查看一个热图,指示场景的哪些部分匹配。我们的方法在复杂的3D场景中有效地识别对象、材料、功能、活动和房间类型,所有这些只使用一个模型进行训练,而无需任何带标签的3D数据。
1. Introduction
3D场景理解是计算机视觉中的一项基本任务。给定一个带有一组RGB图像的3D网格或点云,目标是推断每个3D点的语义、可视性、功能和物理属性。例如,给定图1所示的房子,我们想要预测哪些表面是风扇(语义)的一部分,由金属(材料)制成,在厨房(房间类型)内,人可以坐在哪里(可供性),人可以在哪里工作(功能),哪些表面是柔软的(物理性质)。这些问题的答案可以帮助机器人与场景进行智能交互,或者通过交互式查询和可视化帮助人们理解场景。
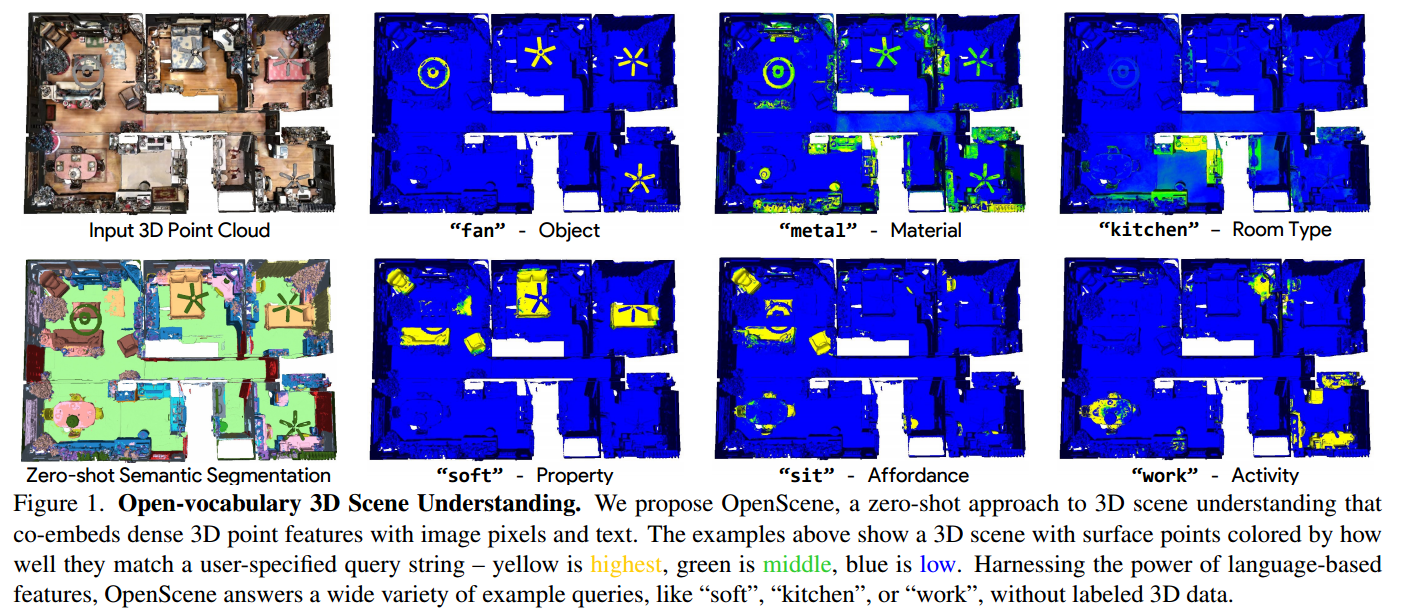
(图1:开放词

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











