







流水线性并行、张量并行、3D并行三种分布式训练方法的详细解读,从原理到具体方法案例。
流水线性并行和张量并行都是对模型本身进行划分,目的是利用有限的单卡显存训练更大的模型。简单来说,流水线并行水平划分模型,即按照层对模型进行划分;张量并行则是垂直划分模型。3D并行则是将流行线并行、张量并行和数据并行同时应用到模型训练中。
流水线并行
流水线并行的目标是训练更大的模型。本小节先介绍符合直觉的朴素层并行方法,并分析其局限性。然后,介绍流水线并行算法GPipe和PipeDream。
1. 朴素层并行
当一个模型大到单个GPU无法训练时,最直接的想法是对模型层进行划分,然后将划分后的部分放置在不同的GPU上。下面以一个4层的序列模型为例,介绍朴素层并行: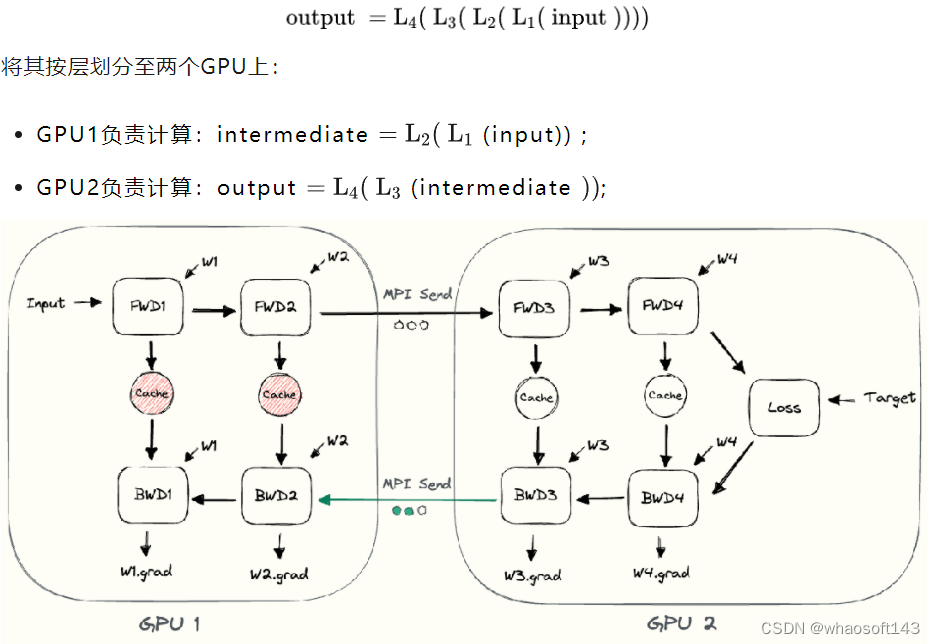 动图
动图  根据上面的介绍,可以发现朴素层并行的缺点:
根据上面的介绍,可以发现朴素层并行的缺点:
-
低GPU利用率。在任意时刻,有且仅有一个GPU在工作,其他GPU都是空闲的。
-
计算和通信没有重叠。在发送前向传播的中间结果(FWD)或者反向传播的中间结果(BWD)时,GPU也是空闲的。
-
高显存占用。GPU1需要保存整个minibatch的所有激活,直至最后完成参数更新。如果batch size很大,这将对显存带来巨大的挑战。
GPipe
GPipe的原理
GPipe通过将minibatch划分为更小且相等尺寸的microbatch来提高效率。具体来说,让每个microbatch独立的计算前后向传播,然后将每个mircobatch的梯度相加,就能得到整个batch的梯度。由于每个层仅在一个GPU上,对mircobatch的梯度求和仅需要在本地进行即可,不需要通信。
假设有4个GPU,并将模型按层划分为4个部分。朴素层并行的过程为
| Timestep | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| GPU3 | FWD | BWD | ||||||
| GPU2 | FWD | BWD | ||||||
| GPU1 | FWD | BWD | ||||||
| GPU0 | FWD |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4071
4071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









