







发现大佬的东西哦 感谢,电梯间电动车识别方案分享
本文代码链接:https://github.com/mengyunye/cvmart
一、任务分析
本次任务为电梯内场景下的16个常见类别的目标检测,16个类别分别如下:
(1)person:人
(2)head:人头,人头框在person框内
(3)door_open:电梯完全打开
(4)door_half_open:电梯半开状态
(5)door_close:电梯关闭状态
(6)daizi:塑料袋、垃圾袋、编织袋、蛇皮袋、麻袋、购物袋
(7)bottle:矿泉水瓶、易拉罐瓶、啤酒瓶等瓶子
(8)bag:背包、手提包、斜挎包、单肩包
(9)box:纸箱、盒子、泡沫箱
(10)plastic_basket:塑料筐
(11)suitcase:行李箱
(12)mobile_phone:手机
(13)umbrella:雨伞
(14)folder:文件夹
(15)bicycle:自行车
(16)electric_scooter:电动车,包括电摩车、电瓶车、电动自行车
任务的评价指标由F1-score和FPS共同组成,详细的计算公式如下图所示。
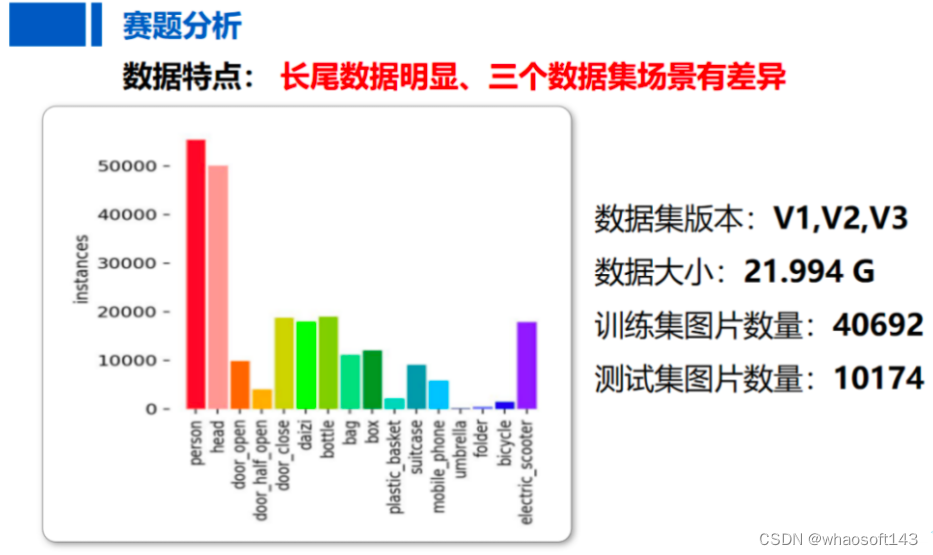
 训练集总共40692张图片,测试集总共10174张图片。16个类别的实例数量分布差异较大,person、head类别实例数量多达50000+,而umbrella和folder类别实例数量仅有100+,长尾数据情况明显,并且该任务提供了三个版本的数据集,三个版本的场景均有差异。
训练集总共40692张图片,测试集总共10174张图片。16个类别的实例数量分布差异较大,person、head类别实例数量多达50000+,而umbrella和folder类别实例数量仅有100+,长尾数据情况明显,并且该任务提供了三个版本的数据集,三个版本的场景均有差异。
二 、模型方案
 yolo系列模型至今已经有很多版本,在本次任务中,我们选用了yolo系列最新的yolov8和极市平台最常用的yolov5作为基线模型。在尝试了yolov8和yolov5的基线模型后,经过对比在本次任务中yolov5表现效果更佳。yolov5的模型结构如下图所示,它具有推理速度快,精度较高的优势。Yolov5官方代码中,给出的检测网络一共四个版本,分别是yolov5s, yolov5m,yolov5l,yolov5x四个模型。yolov5s是YOLOV5系列中深度最小,特征图的宽度最小的网络,后面的三种网络都是在此基础上不断的加深,不断的加宽。考虑到该榜对推理速度有一定的要求,我们选择了yolov5s版本作为baseline。
yolo系列模型至今已经有很多版本,在本次任务中,我们选用了yolo系列最新的yolov8和极市平台最常用的yolov5作为基线模型。在尝试了yolov8和yolov5的基线模型后,经过对比在本次任务中yolov5表现效果更佳。yolov5的模型结构如下图所示,它具有推理速度快,精度较高的优势。Yolov5官方代码中,给出的检测网络一共四个版本,分别是yolov5s, yolov5m,yolov5l,yolov5x四个模型。yolov5s是YOLOV5系列中深度最小,特征图的宽度最小的网络,后面的三种网络都是在此基础上不断的加深,不断的加宽。考虑到该榜对推理速度有一定的要求,我们选择了yolov5s版本作为baseline。
在模型训练上我们主要做了三个改进,分别是数据划分、损失函数和训练策略上的改进。
在数据划分上,考虑到数据长尾分布明显,于是我们采用优先满足实例数量较少类别按比例划分策略划分数据集,将训练数据按9:1划分训练集和验证集。采用这样的策略能够有效地避免数据量极少的类别因为随机划分数据集可能在训练集出现的数量过少或没有出现的情况。经过试验对比,这样的划分策略能够有效地提升实例数量较少类别的识别。
在损失函数上,我们引入MPDIoU改进IoU损失,该该算法伪代码如下图所示。MPDIoU是一种基于最小点距离的新型边界框相似度比较度量,相对于现有的IoU具有收敛快、效果更优的特点。使用改进后的损失函数,我们的F1-score可以达到0.9518。
MPDIoU实现相关代码如下:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MPFIoU=True, imgsize=640, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, 1), box2.chunk(4, 1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, 1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, 1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
MPFIoU_m = 2*imgsize**2
if MPFIoU:
d1 = (b2_x1-b1_x1)**2 + (b2_y1-b1_y1)**2
d2 = (b2_x2-b1_x2)**2 + (b2_y2-b1_y2)**2
iou -= (d1+d2)/MPFIoU_m
return iou
最后为了优化实例较少样本的训练效果不佳的情况,我们降低了学习率,每类选取100个样本,然后进行循环冻结,此时F1-score能够达到0.9535。最后进行微调,使用所有数据训练,随机选取50%的数据作为验证,同时关闭数据增强、降低学习率。最终F1-score达到0.9543。
三、部署方案
我们采用极市官方提供的部署套件,将输入图像尺寸由训练时候的640X640改为480X480。以此提升推理速度,此时推理速度可以达到100+,速度分满分。但是,此时我们发现F1-score下降了0.0235,这对于整体的分数损失是极大的。whaosoft aiot http://143ai.com

精度损失可能是输入图像尺寸变小导致,但是一般不会下降这么多。经过对比Python和C++的推理代码,我们发现可能是NMS的差别导致精度的差异较大,于是我们对C++的NMS进行了重写,将原来的NMS重写为单类别别NMS。果然,重写后的NMS使F1-score上涨到0.9481。重写后的NMS代码如下:
void NMS(std::vector<BoxInfo> &objects, float iou_thresh)
{
auto cmp_lammda = [](const BoxInfo &b1, const BoxInfo &b2)
{ return b1.score > b2.score; };
std::sort(objects.begin(), objects.end(), cmp_lammda);
for (int i = 0; i < objects.size(); ++i)
{
if(objects[i].score < 0.000001){
continue; //已经删除,跳过
}
for (int j = i + 1; j < objects.size(); ++j)
{
if(objects[i].label != objects[j].label){//不同类别,跳过
continue;
}
cv::Rect rect1 = cv::Rect{objects[i].x1, objects[i].y1, objects[i].x2 - objects[i].x1, objects[i].y2 - objects[i].y1};
cv::Rect rect2 = cv::Rect{objects[j].x1, objects[j].y1, objects[j].x2 - objects[i].x1, objects[j].y2 - objects[j].y1};
if (IOU(rect1, rect2) > iou_thresh)
{
objects[j].score = 0.f;
SDKLOG(INFO) << "erase id:" << j;
}
}
}
auto iter = objects.begin();
while (iter != objects.end())
{
if (iter->score < 0.000001)
{
iter = objects.erase(iter);
}
else
{
++iter;
}
}
}
四、成果总结
不过本方案最终可以取得第一的成绩,不过成绩是在截榜之后出的,截榜时取得了第二名。算法精度和推理速度的提升分别为:F1-score:0.9047-->0.9481 (+0.0434),FPS:53-->105 (+52)。
五、参考文献
Yolov8损失函数改进:MPDIoU新型边界框相似度度量,效果秒杀GIoU、 DIoU、CIoU、EIoU等 | ELSEVIER 2023:https://zhuanlan.zhihu.com/p/647613274
Yolov8官方GitHub仓库:http://github.com/ultralytics/ultralytics

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









