







这里说下自动驾驶中的多模态融合感知算法(数据级/特征级/目标级)
多模态传感器融合意味着信息互补、稳定和安全,长期以来都是自动驾驶感知的重要一环。然而信息利用的不充分、原始数据的噪声及各个传感器间的错位(如时间戳不同步),这些因素都导致融合性能一直受限。本文全面调研了现有多模态自动驾驶感知算法,传感器包括LiDAR和相机,聚焦于目标检测和语义分割,分析超过50篇文献。同传统融合算法分类方法不同,本文从融合阶段的不同将该领域分类两大类、四小类。此外,本文分析了当前领域存在的问题,对未来的研究方向提供参考。
为什么需要多模态?
这是因为单模态的感知算法存在固有的缺陷。举个例子,一般激光雷达的架设位置是高于相机的,在复杂的现实驾驶场景中,物体在前视摄像头中可能被遮挡,此时利用激光雷达就有可能捕获缺失的目标。但是由于机械结构的限制,LiDAR在不同的距离有不同的分辨率,而且容易受到极端恶劣天气的影响,如暴雨等。虽然两种传感器单独使用都可以做的很出色,但从未来的角度出发,LiDAR和相机的信息互补将会使得自动驾驶在感知层面上更安全。
近期,自动驾驶多模态感知算法获得了长足的进步,从跨模态的特征表示、更可靠的模态传感器,到更复杂、更稳定的多模态融合算法和技术。然而,只有少数的综述[15, 81]聚焦于多模态融合的方法论本身,并且大多数文献都遵循传统分类规则,即分为前融合、深度(特征)融合和后融合三大类,重点关注算法中特征融合的阶段,无论是数据级、特征级还是提议级。这种分类规则存在两个问题:首先,没有明确定义每个级别的特征表示;其次,它从对称的角度处理激光雷达和相机这两个分支,进而模糊了LiDAR分支中提级级特征融合和相机分支中数据级特征融合的情况。总结来说,传统分类法虽然直观,但已经不适用于现阶段多模态融合算法的发展,一定程度上阻碍了研究人员从系统的角度进行研究和分析。
任务和公开比赛
常见的感知任务包括目标检测、语义分割、深度补全和预测等。本文重点关注检测和分割,如障碍物、交通信号灯、交通标志的检测和车道线、freespace的分割等。自动驾驶感知任务如下图所示:
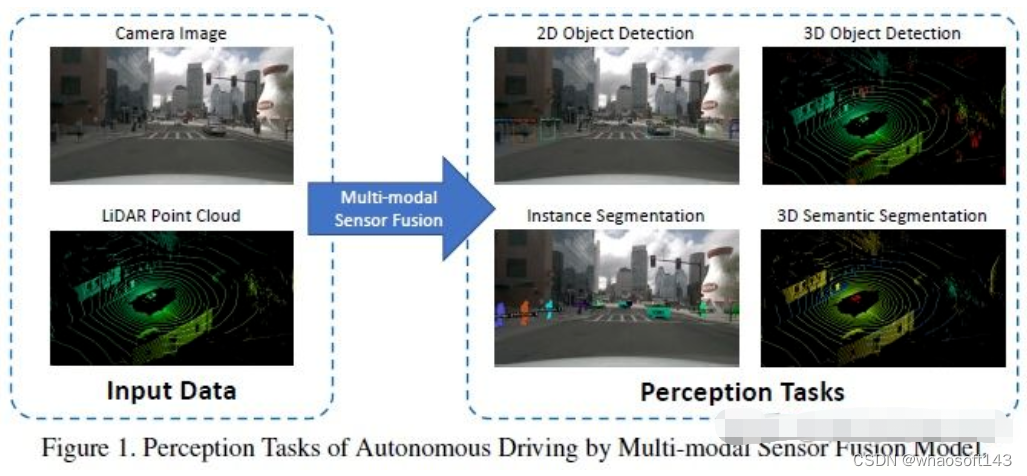
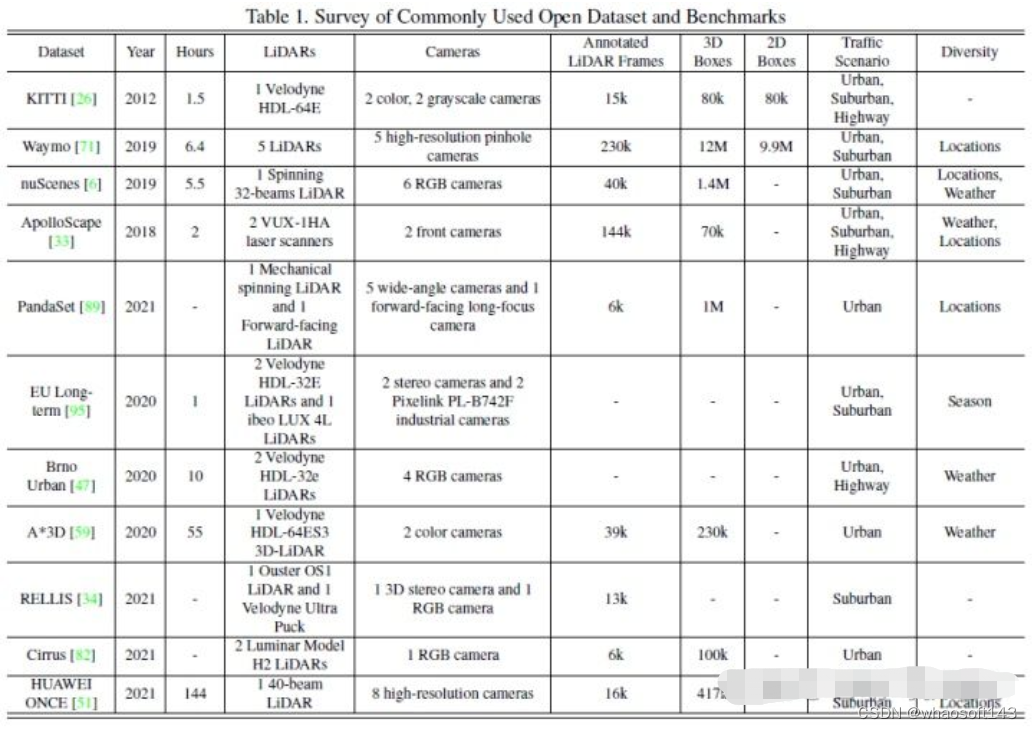
常用的公开数据集主要包含KITTI、Waymo和nuScenes,下图汇总了自动驾驶感知相关的数据集及其特点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









