









多模态目标检测的场景
- 单模态的目标检测领域,尤其是基于图像的目标检测任务在各大数据集中取得了较好的效果,其中主要分为基于CNN和基于Transformer骨干网络检测算法,尤其是基于Transformer的DINO模型在COCO数据集中取得了SOTA AP = 63.2%的效果,但是在真实场景下,相机受环境的光线、天气等干扰较大,鲁棒性较差。如下图所示,在雨雾天气下,相机的镜头被雨滴遮盖部分图像信息,导致左方的行人没有检测到,此时的单模态模型性能会大幅度下降甚至失效。

传感器
-
毫米波雷达和激光雷达作为自动驾驶领域的两种常用传感器,其相较于相机,可以获取除RGB等物体的纹理信息以外的深度、速度等信息,能够为目标检测提供额外的辅助信息来提高检测精度。
-
其中,激光雷达能够获取环境的密集深度信息,其产生的点云信息具有密度高,精准,具有3D信息等优点。当前存在多个基于点云模态的目标检测算法,以Qi等人[1]提出的Frustum-PointNet为代表的图像-点云融合检测方式,利用CNN的图像检测结果筛选目标点云,后通过CNN对目标点云3D-Box位置进行回归。但是激光雷达传感器以激光的方式获得点云的深度信息,仍受到光线等外部环境的干扰,对云雾的穿透性不强,在雨天会误识别雨滴而导致传感器失效。

毫米波原理
- 毫米波雷达的成像原理:毫米波雷达的点包括 X、Y坐标,RCS(物体反射面积)和 Doppler(物体速度),毫米波雷达是指工作在波长为1-10mm的毫米波段,频率为30~300GHz。基于其工作模式可以分为 “脉冲” 和 “连续波” 两种。其中,脉冲类型的毫米波雷达的原理与激光雷达相似都是采用TOF的方法。而连续波类型可以分为:CW恒频连续波,用于测速; FSK频移键控连续波,可探测单个目标的距离和速度,以及目前所采用的:FMCW调频连续波,探测多个目标的距离和速度,毫米波雷达工作原理如下图所示。原理涉及的篇幅较大,这里列出我参考的一篇技术blog:
https://blog.csdn.net/wxc_1998/article/details/122834341
前沿工作
-
John等人[2]提出一种基于YOLOv3的双分支融合检测结构-RVNet,其将图像与经过投影后的雷达图像分别送入独立的分支处理,将两个分支产生的特征图进行concate并将concate后的特征图分别送入两个独立的目标检测分支,同时对于大目标和小目标采取不同的特征融合方式。经过实验,作者证明雷达信息对目标的二分类任务具有较大的提升,对于多分类任务性能提升不大,说明了雷达点云其对于增强视觉检测模型的所不擅长的小目标和遮挡目标检测具有较大的提升,而对于目标的分类任务上所提供的信息不足。

-
Nobis等人 [3]提出了一种多级特征融合的检测模型-CRFNet,其通过RetinaNet提取多级特征并进行融合检测,同时提出了BlackIn使模型偏重于对雷达信息的学习从而提升雷达信息对目标检测的效果。在数据方面,作者进行了多个消融实验:AF & GAF,证明了雷达点云的杂波对于目标检测性能提升的阻碍较大,而且多级融合结果能够大大提升目标检测效果。
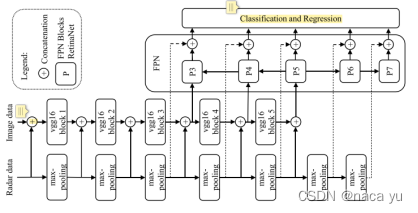
-
Nabati等人[4]在CRFNet的基础上,提出一种端到端滤波的双分支融合检测模型,其以CenterNet为基础模型,其通过CenterNet预测目标的初步3D-Box,通过投影结合Pillar Expansion与Frustum Assotiation实现端到端的点云杂波滤除,最后融合两个模态的信息进行目标检测。但是,其作为一种two-stage:先预测,后投影筛选的流程会增加处理时间,同时限制了雷达点对于模型的范围性能提升,并没有超过CRFNet。
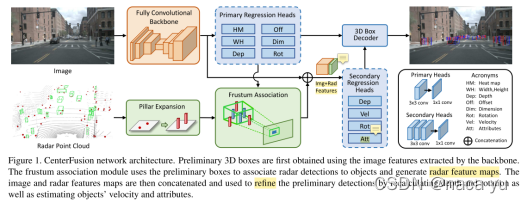
-
Shuo等人[5]提出一种基于注意力的融合检测方式- SAF-FCOS:其将雷达点云图通过卷积滤波后,将其转化为阈值来增强点云对应的RGB信息实现融合。同时对ADD,MULTILY,CONCATE多种融合方式进行消融实验,实验证明注意力融合的效果最好。这里也可能是作者提出的early-fusion方式适合注意力融合机制。
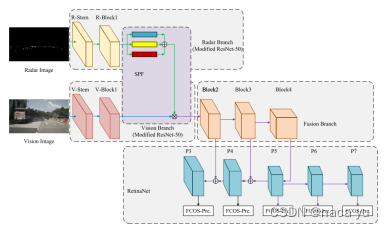
- Kowol[6]提出一种后融合的双分支目标检测模型,雷达分支为二分类模型,通过将图像分割为n个slice并判断为(0:有目标,1:无目标),图像分支使用YOLOv3作为检测模型独立预测目标位置,通过Boosting Gradient的方式实现弱分类器的增强,联合两个分支的预测结果做出最后预测。实验证明,作者提出的模型可以有效提升恶劣天气和夜晚环境下的检测效果,由于slice宽度的限制,作者只针对汽车单一目标训练和验证,存在检测目标单一的问题。
[1]Qi, C. R., & Guibas, L. J. (2018). 12-Qi_Frustum_PointNets_for_CVPR_2018_paper.pdf. Frustum PointNets for 3D Object Detection from RGB-D Data.
[2]John, V., & Mita, S. (2019). RVNet: Deep Sensor Fusion of Monocular Camera and Radar for Image-Based Obstacle Detection in Challenging Environments. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11854 LNCS(September), 351–364. https://doi.org/10.1007/978-3-030-34879-3_27
[3]Nobis, F., Geisslinger, M., Weber, M., Betz, J., & Lienkamp, M. (2019). A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection. 2019 Symposium on Sensor Data Fusion: Trends, Solutions, Applications, SDF 2019, 1–7. https://doi.org/10.1109/SDF.2019.8916629
[4]Nabati, R., & Qi, H. (n.d.). CenterFusion : Center-based Radar and Camera Fusion for 3D Object Detection.
[5]Chang, S., Zhang, Y., Zhang, F., Zhao, X., Huang, S., Feng, Z., & Wei, Z. (2020). Spatial attention fusion for obstacle detection using mmwave radar and vision sensor. Sensors (Switzerland), 20(4), 1–21. https://doi.org/10.3390/s20040956
[6]Kowol, K., Rottmann, M., Bracke, S., & Gottschalk, H. (2021). YOdar: Uncertainty-based sensor fusion for vehicle detection with camera and radar sensors. ICAART 2021 - Proceedings of the 13th International Conference on Agents and Artificial Intelligence, 2, 177–186. https://doi.org/10.5220/0010239301770186


















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











