







1.背景

这篇文章是北航和亚洲微软研究院共同发表的。目前主流的NLP任务,都需要先预训练模型,例如Bert和ALBert。本文章也主要集中在机器翻译(NMT)上的预训练任务。
本文指出,以前的预训练任务,并没有训练encoder和decoder之间的cross-attention,这会导致在fine-tuning阶段并没有巨大的提升。针对预训练任务上,cross-attention的训练,本文提出了两个语义交互(semantic interface)方法:
- CL-SemFace:使用交互语言embeddings,训练attention的参数
- VQ-SemFace:使用量化embedding,把encoder output和decoder inputs限制在同一语言独立空间中
实验中,用到了6个有监督翻译语言对,3个无监督翻译语言对
2. 引入
以前,预训练通常方法是在encoder和decoder上,利用大数据集独立进行训练,这种做法忽略了attention层的参数训练。论文中提到,通过语义接口(semantic interface),编码器经过预训练以将特征提取到该空间,解码器经过预训练以生成encoder提供的内容。
- CL-SemFace:使用cross-lingual embeddings(跨语言)无监督训练
- VQ-SemFace:同时映射encoder outputs 和decoder inputs 到同一VQ空间中
3.方法介绍
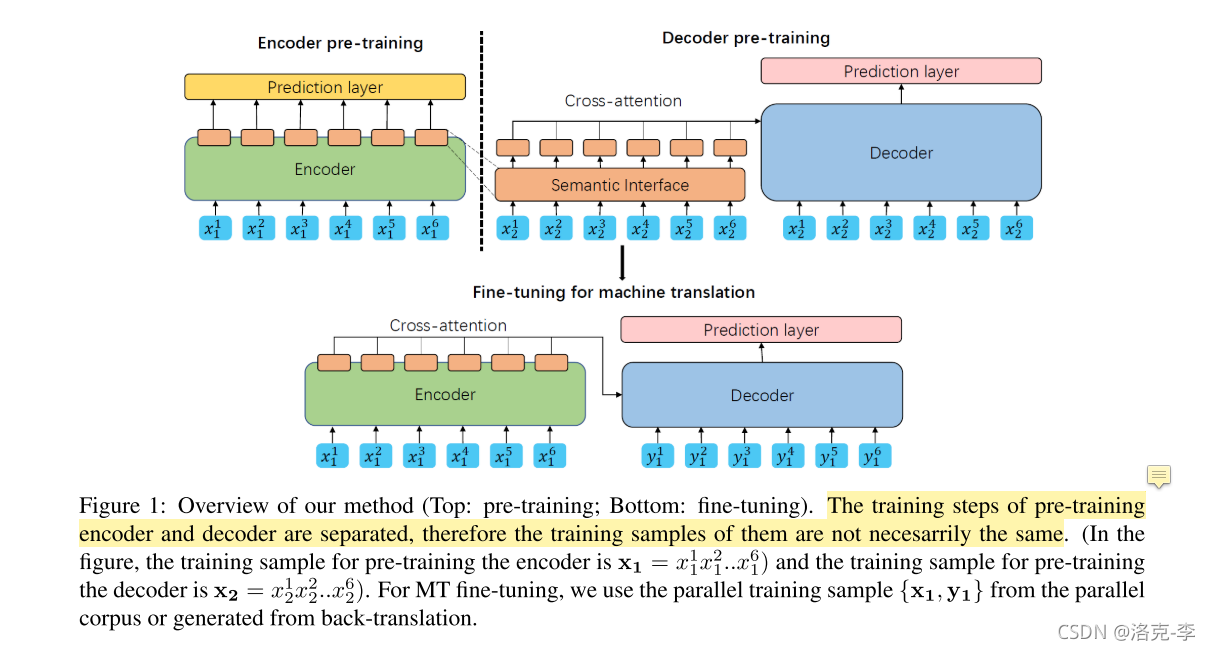
首先整个预训练阶段如上图所示。
(1)首先,使用单语数据分别预训练编码器和解码器,它们之间有语义接口。其中
x
1
x_1
x1输入到encoder中,
x
2
x_2
x2输入到docoder中,两个输入用到的是两种不同的语言。
(2)编码器经过预训练得到Semantic Interface,而解码器经过预训练通过cross-attention内容完成解码。
具体的执行算法如下:

- 输入:语料库 D x D_x Dx和 D y D_y Dy,输出:更新参数 M θ M_\theta Mθ
- (1)随机初始化encoder和decoder的参数 θ e n c \theta_{enc} θenc和 θ d e c \theta_{dec} θdec,还有semantic interface 的参数 θ s f \theta_{sf} θsf
- (2)针对CL-SemFace,初始化 θ s f \theta_{sf} θsf作为预训练embeddings
- (3)从两个语料库中随机选择batch B B B;输入 B B B到encoder和SemFace中,更新参数 θ e n c \theta_{enc} θenc和 θ s f \theta_{sf} θsf;在输入 B B B到decoder中,更新参数 θ d e c \theta_{dec} θdec
3.1 CL-SemFace
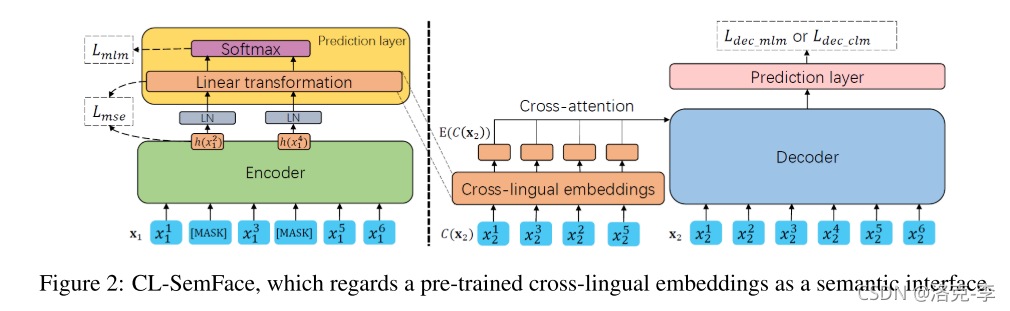
(1)encoder:输入
x
1
x_1
x1,利用MLM任务和MSE任务,进行与训练
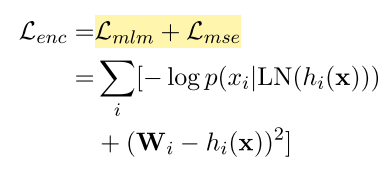
(2)cross-attention:在 x 2 x_2 x2中添加噪声,得到 C ( x 2 ) C(x_2) C(x2)。把ecoder中得到的BPE embedding拿出来,然后用第二个样本 x 2 x_2 x2进行输入编码,得到 E E E。把 E E E和 x 2 x_2 x2进行相乘,用来训练decoder
(3)这种做法就可以同时训练attention层
3.2 VQ-SemFace
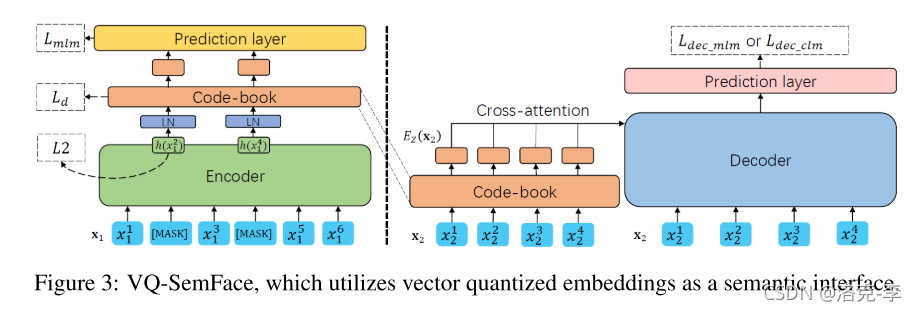
CL-SemFace主要是用来约束word embedding,意味着不同的单词可能有同样的embedding,同时网络的units需要和词典的大小一致。
因此VQ-SemFace主要用来学习上下文独立的语义,它主要参考了VQ-VAE模型,设定了一个潜在空间。
VQ的定义可以参考这个网址:https://zhuanlan.zhihu.com/p/91434658
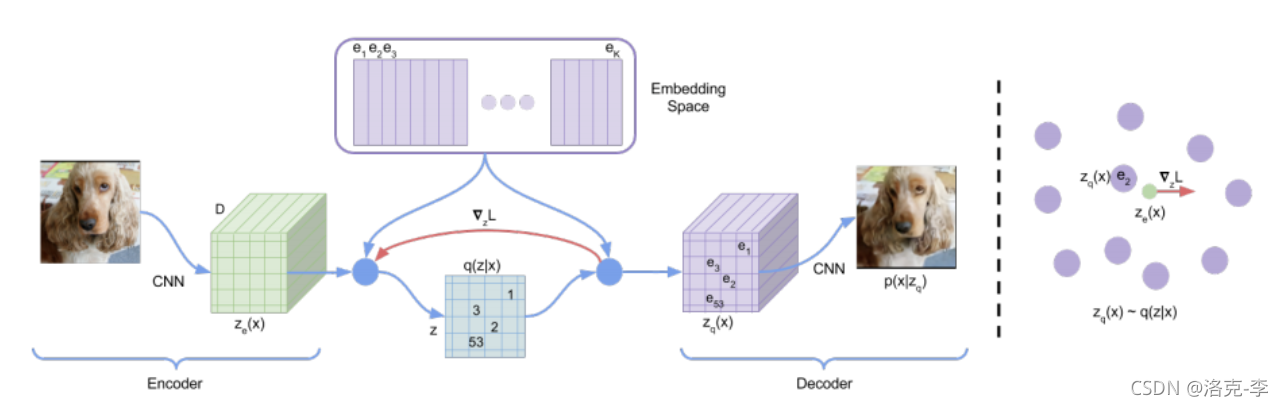
VQ方法:把 x 1 x_1 x1输入到encoder得到 h h h,然后在code-book(前在语义空间)找到最相似的 z z z
4.实验
在fine-tuning阶段,去掉了semantic interface,直接使用cross-attention进行解码和编码。
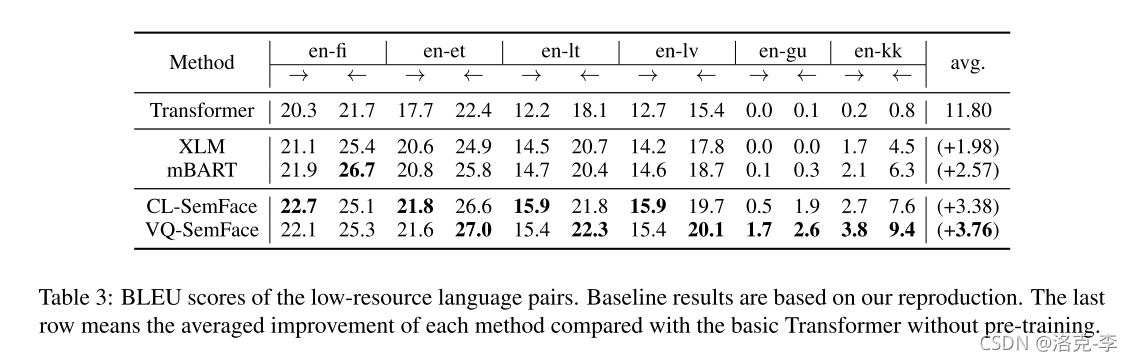
- 在多个数据集上,效果比Transformer要好。















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











