






微调NLLB模型进行维吾尔语翻译:从数据构建到多卡训练的实战分享
一、项目背景与动机(引言)
内容要点:
- 为什么要做维吾尔语翻译?
维吾尔语是我国新疆地区主体民族语言,也是中华文化重要组成部分。做好维吾尔语翻译,既能打破语言壁垒,促进民族间文化交流、教育医疗资源共享与经济协作,保障少数民族平等获取信息的权利,又能守护语言多样性,助力非遗传承与边疆地区治理,对维护民族团结、推动区域发展具有重要现实意义。
- 当前主流翻译模型对维吾尔语的支持情况。
目前看到的开源模型只有
Meta NLLB (No Language Left Behind)和 Google 的MADLAD-400支持维吾尔语。主要是词表支持才可以进行微调,试过自己训练词表,效果不太好。
- 选择
facebook/nllb-200-distilled-600M的原因。
NLLB 在 Hugging Face 社区拥有非常成熟的生态系统。有大量的教程、微调脚本示例(尤其是配合
transformers库和accelerate)以及社区讨论。你之前使用nllb-200-distilled-600M的经验可以直接复用或轻松迁移到更大的NLLB模型(如NLLB-1.3B, NLLB-3.3B)。
- 微调的目标(提升
维吾尔语到中文的翻译质量)。
目前我们有两亿条中-维平行句对语料,经过一系列数据清洗、去重复、质量评估等步骤,最终剩余970w对高质量数据。
- ✅ 全球语言支持图中维吾尔语的位置(可截图nllb支持语言列表)
- ✅ 已有模型对维吾尔语的BLEU、Chrf++表现
找了下
NLLB的paper以及HuggingFcce,只找到两个结果内容与维语相关,一个是英文-维语翻译结果Chrf++为39.3,维语-英文Chrf++为47.4。感觉不是很高,在接下来的微调中,我只使用了BLEU指标。
二、数据准备与预处理
2.1 数据来源
- 数据采集方式(企业自有)
- 数据量、语种配对情况(如 Uyghur-Chinese)
📊 数据概览表
| 数据名称 | 语种对 | 数据量(句对) | 来源 | 备注 |
|---|---|---|---|---|
| UyZh-Corpus | Uy-Zh | 200000000 | 自建 | 新闻/百科类 |
2.2 清洗与标准化
- 去除乱码
- 长度过滤
- 重复样本处理
- 质量筛选
过程比较痛苦,整个过程,洗数据占用大概 60% 的精力

2.3 数据格式转换(torch的Dataloader格式)
- 分割为train/test
筛选完后,高质量数据大概剩余970w对,只拿了 1000 条作为测试数据,不知道这是不是后面导致 BLEU 值偏高的原因(应该不是😊)。
📊 数据划分比例
| 数据集 | 样本数 | 占比 |
|---|---|---|
| 训练集 | 970w | 99% |
| 测试集 | 1k | 1% |
三、模型结构与训练策略
3.1 模型选择
- 简述
NLLB-200-distilled-600M的结构特点 (transformer decoder-only,适合低资源场景等)
📊 NLLB模型对比
| 模型名 | 参数量 | 支持语言数 | 适用场景 |
|---|---|---|---|
| nllb-200-distilled-600M | 600M | 200+ | 中小语种翻译 |
| nllb-1.3B | 1.3B | 200+ | 大模型精度高 |
3.2 加速框架设置(Accelerate + 多卡)
- 介绍
Accelerate的优势与使用方法
🤖
Huggingface的Accelerate是一个轻量级训练加速库,支持多卡、混合精度等训练策略,无需复杂配置即可在多种硬件上高效运行。使用方法简单,只需通过accelerate config配置环境,再用accelerate launch启动训练脚本,快速实现分布式训练。
- 设备展示(小装一下😂)(使用8卡A100,fp16/bf16)
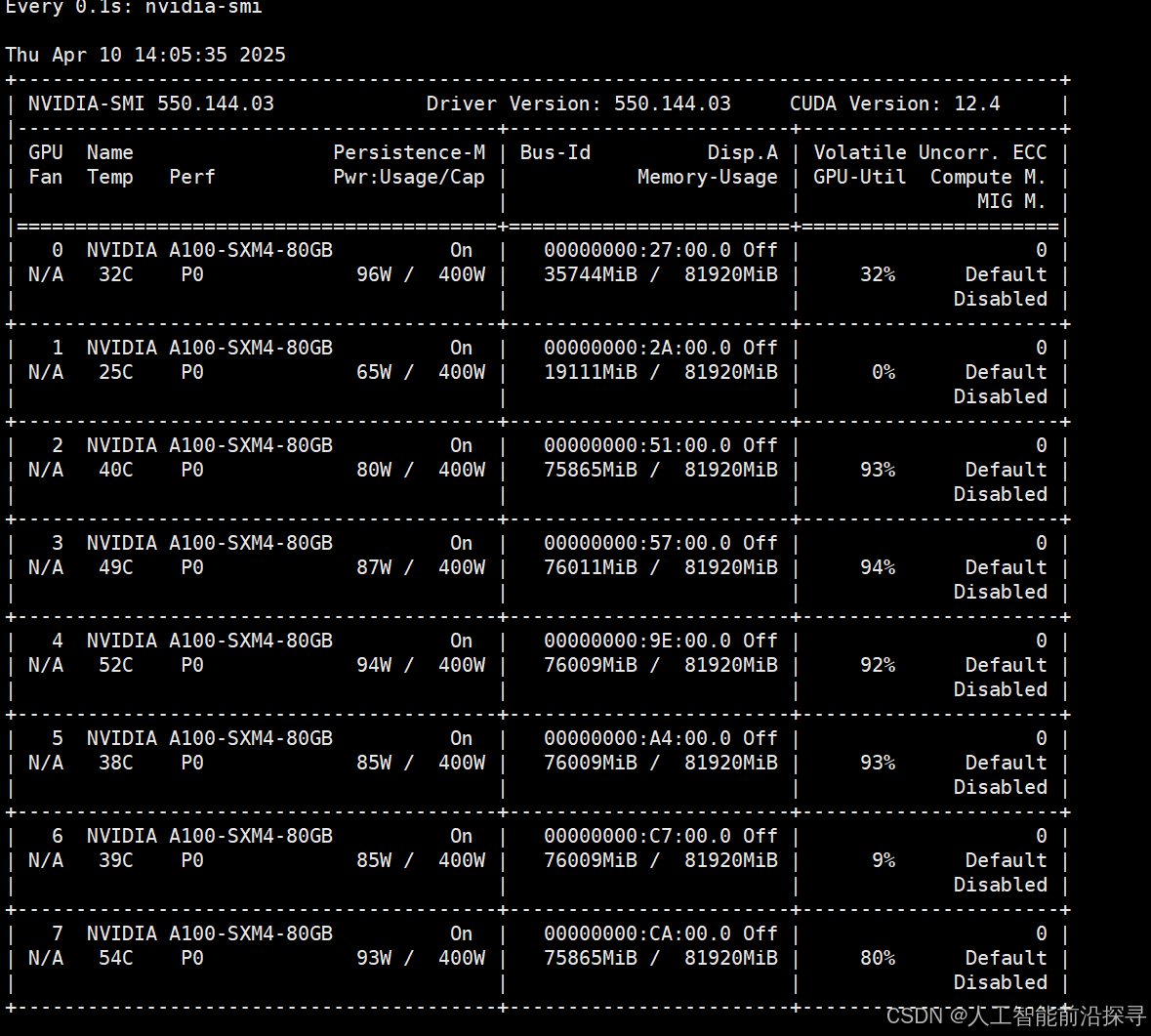
- Batch Size / Gradient Accumulation等超参配置
细节可根据自己设备而定
🧾 accelerate config 配置文件
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: 0,1,2,3,4,5,6,7
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
3.3 微调细节
- Loss函数、优化器(AdamW等)
使用
AdamW 优化器搭配线性学习率调度(Linear Warmup + Decay)策略,有效提升模型稳定性与收敛速度。训练总步数由 epoch × batch 数计算,前 1500 步进行 warmup,避免初期梯度不稳定。每 1000 步执行日志记录、验证与模型保存(仅保存最优 10 个),方便监控与恢复训练进度。
- Tokenizer(使用NLLB自己的tokenizer?)
使用
NLLB自己的词表以及tokenizer。
- 是否使用语言标签
| 语言 | FLORES-200 code |
|---|---|
| Uyghur | uig_Arab |
| Chinese | zho_Hans |
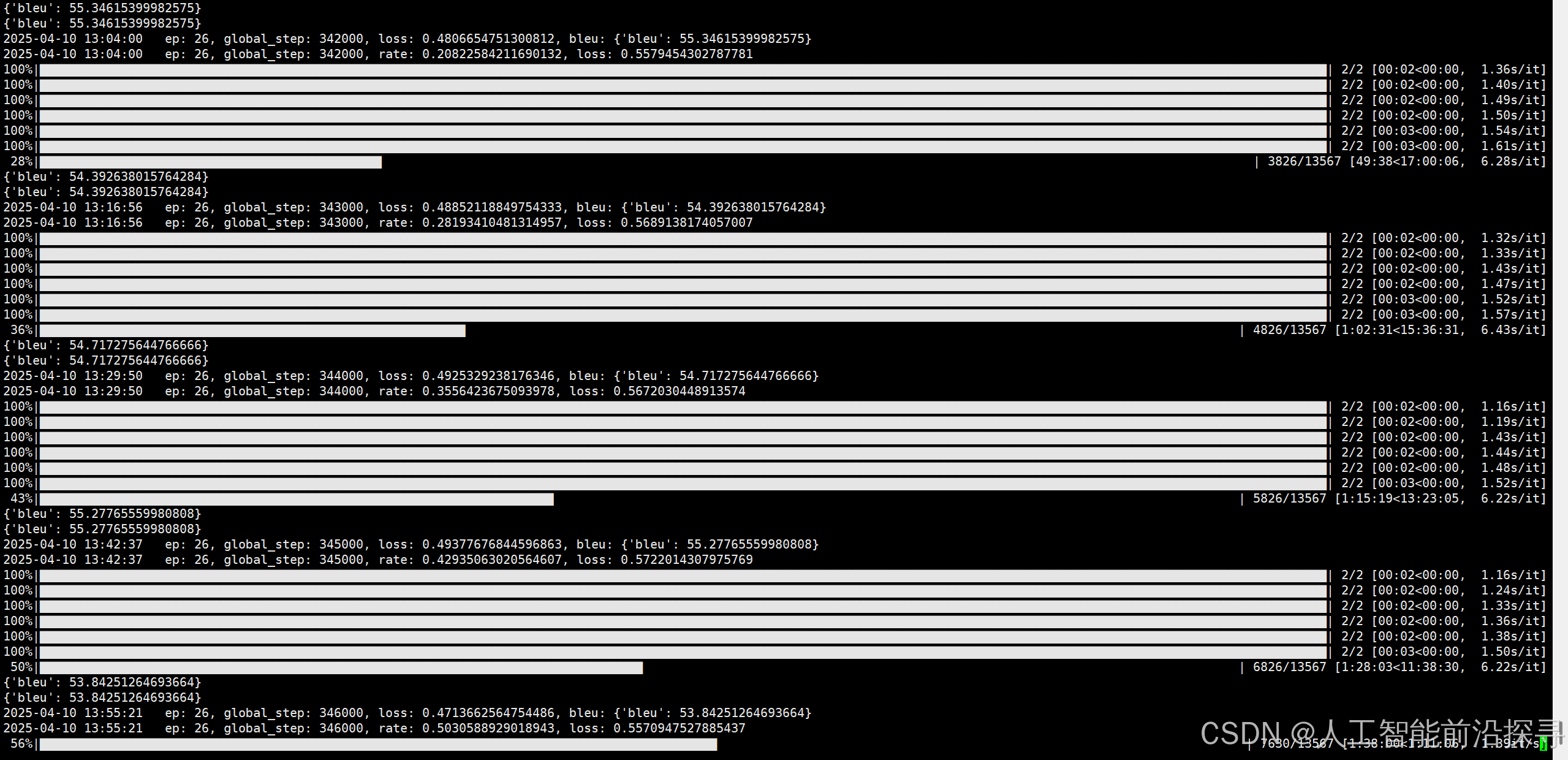
📷 训练过程loss下降曲线
暂时没图, 自己训练没这么讲究,通过日志看 loss,下次可以加一个 tensorboard 进行可视化。
四、评估与结果分析
4.1 指标选择
- BLEU / chrF / COMET / TER 等(重点介绍BLEU)
📊 评估指标结果
| 模型 | BLEU (ug2zh) | 备注 |
|---|---|---|
| 原始NLLB-600M | 13.4 | Zero-shot |
| 微调后模型(本文) | 58.6 | Fine-tuned |

4.2 人类评估样例
- 展示几条翻译前后文本对比
📊 翻译示例对比表
| 模型预测 | 标准答案 |
|---|---|
| 这是他给我写的最后一封信。 | 这是她写给我最后的一封信。 |
| 我和你一起看书。 | 我要和你一起看书。 |
| 他完成作业又快又好。 | 她的作业完成的又快又好。 |
| 我看这还是头一回有人向她求婚呢。 | 我看这还是头一回有人向她求婚呢。 |
| 筹备工作已经展开 | 筹备工作展开 |
| 你很快乐因为所有这些都发生了。 | 你很快乐因为所有这些都发生了。 |
| 皮肤也进入了中期老化阶段 | 皮肤也进入了中期老化阶段 |
| 书店。 | 书店。 |
| 朋友你的名字叫什么呢? | 朋友你的名字叫呢? |
| 主要领导不在 | 主要领导不在 |
| 这几天一直在出去。 | 这几天一直在出去。 |
| 你到底要带我去哪里 | 你究竟要带我去哪儿 |
| 言和他们理论,但那个所谓的总经理却死不认账。 | 言和他们理论,但那个所谓的总经理却死不认账。 |
| 它是以活性炭为载体,用铜等氧化物的混合物作活性成分。 | 它是以活性炭为载体,用铜等氧化物的混合物作活性组分。 |
| 健全各级党组织 | 各级党组织 |
| 五个北方人热气球逃脱了。 | 五个北方人热气球逃脱了。 |
| 相互包含 | 相互包含 |
| 我希望他们不要再复读。 | 我希望他们不要再复读了。 |
| 你抽烟抽得有些多。 | 你抽烟抽得有些多。 |
| 艾斯拉汗阿卜都尼亚 | 艾斯拉汗啊不都呢亚 |
| 加一小茶匙糖。 | 加一小茶匙糖。 |
| 在班图人大迁徙时是西班图人的一支,曾在刚果河中下游一带建立安济科国。 | 在班图人大迁徙时是西班图人的一支,曾在刚果河中下游一带建立安济科国。 |
| 那是一个不以人们意志为转移的过程。 | 是一个不以人们意志为转移的变迁过程。 |
数据处理阶段已经按照 token 长度(5-128)筛选过了,不知为何还是有单个词的内容!不过问题不大,问就是增加了鲁棒性。
五、部署与使用
5.1 如何加载微调模型
- 使用
transformers加载微调后的权重 - 推理代码示例
🧾 模型加载 + 推理
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
tokenizer_zh2en = AutoTokenizer.from_pretrained("模型路径\\NLLB-200-600M")
model_zh2en = AutoModelForSeq2SeqLM.from_pretrained("模型路径\\NLLB-200-600M")
translator = pipeline(
'translation',
model=model_zh2en,
tokenizer=tokenizer_zh2en,
src_lang='uig_Arab',
tgt_lang='zho_Hans',
max_length=512
)
content = 'ﻡەﻥ ﺏۇ ﻥەﺮﺳﻰﻧﻯ ﺏەﻙ ﻕﻯﺯﻰﻗﺍﺮﻟﻰﻗ ھېﺱ ﻕﻰﻟﺩﻰﻣ.'
tgt_text = translator(content)
5.2 API封装建议
- 用 Flask/FastAPI 封装REST API
六、挑战与经验总结
- 数据不规范问题
感觉整个过程难度最大的部分就是处理数据,训练初期最大的问题是语料数据不规范,部分句子存在编码错误、缺失对齐或语法不完整。为提升数据质量,清洗过程用了大量策略,甚至耗费大量算力进行质量评估,不过最终结果显示,这是值得的。😊
- 训练中遇到的问题(如过拟合、显存爆炸)
比较顺利,没有很多坑,
huggingface以及accelerate框架代码比较成熟,我只修改了一小部分。
- 翻译质量评估中BLEU的局限
BLEU 虽是翻译评估常用指标,但在低资源语言或自由翻译中常失效。它过于依赖 n-gram 重叠,难以反映语义准确性与表达多样性。目前还未确认我训练出的高 BLEU 的实际有效性,等项目经过大量测试再说。
七、未来展望
- 多语言混合训练?
将进行中、维、藏、英多语言混合训练,将使用更大的模型。训练复杂度较高,需要合理选择模型大小、数据配比等问题。
- 蒸馏成更轻量的版本部署?
使用 600M 大小的模型原因就是方便部署。
附录
- 所用代码仓库地址
Huggingface模型链接
https://huggingface.co/facebook/nllb-200-distilled-600M
- 参考资料链接(Huggingface Blog、NLLB论文)
Huggingface官方 NLLB 文档:
https://huggingface.co/docs/transformers/model_doc/nllb
NLLB paper:
https://arxiv.org/abs/2207.04672
NLLB 支持的语言列表以及对应的FLORES-200 code:
https://blog.csdn.net/u010302327/article/details/131183852

















 2292
2292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









