






论文链接:https://ieeexplore.ieee.org/abstract/document/10172029
1. 论文概述

背景与动机
细粒度图像分类任务面临两个主要挑战:
- 类间差异小:不同类别之间的视觉特征非常相似;
- 类内差异大:同一类别的图像在姿态、光照、背景等方面可能存在较大变化。
传统方法大多只关注图像的视觉特征,而忽略了图像中通常伴随的其他信息,如拍摄位置(经纬度)和拍摄时间。这篇论文提出利用这些多模态时空信息,结合视觉特征,从而进一步提升细粒度图像分类的准确率。
主要贡献
论文提出的整体方法包含四个核心模块:
- 多模态数据预处理
- 多时序特征融合(包括早期和晚期融合)
- 基于自注意力的MLP(SAMLP)模块用于多模态特征提取
- 决策校正策略
实验结果表明,在iNaturalist系列数据集上,综合使用各模块的方法能在保持较小计算代价的前提下取得SOTA效果。
2. 多模态数据预处理
论文首先对原始的时空多模态数据进行预处理,其目的是使得不同来源的数据(位置、时间)能够统一尺度,并在后续阶段更好地表达其语义信息。
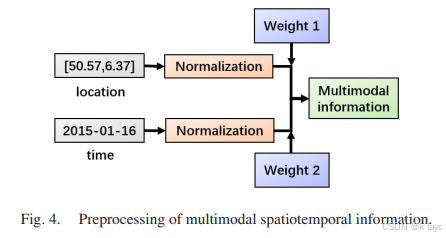
2.1 数据归一化
-
经度与纬度归一化
原始经度数据的取值范围为 [ 0 , 180 ] [0, 180] [0,180],纬度为 [ 0 , 90 ] [0, 90] [0,90],归一化公式如下:
l a t = l a t 90 lat = \frac{lat}{90} lat=90lat
l o n = l o n 180 lon = \frac{lon}{180} lon=180lon -
日期归一化
将日期数据转换为一年中对应的天数比例:
d a t e = s u m d a y s t o t a l d a y s date = \frac{sumdays}{totaldays} date=totaldayssumdays
其中, s u m d a y s sumdays sumdays为该天在一年中的序号, t o t a l d a y s totaldays totaldays为该年的总天数(考虑闰年因素)。
2.2 数据包装与非线性映射
为了更好地捕捉位置信息与时间信息的关系,论文将归一化后的数据进一步“包装”为语句(phrase)的形式:
-
位置包装
先将归一化后的纬度与经度拼接为一个向量:
l o c = c o n c a t ( l a t , l o n ) loc = concat(lat, lon) loc=concat(lat,lon)
再进行非线性映射:
l o c ^ = [ sin ( π ⋅ l o c ) , cos ( π ⋅ l o c ) ] \hat{loc} = [\sin(\pi \cdot loc), \cos(\pi \cdot loc)] loc^=[sin(π⋅loc),cos(π⋅loc)] -
时间包装
对归一化后的日期同样做非线性映射:
d a t e ^ = [ sin ( π ⋅ d a t e ) , cos ( π ⋅ d a t e ) ] \hat{date} = [\sin(\pi \cdot date), \cos(\pi \cdot date)] date^=[sin(π⋅date),cos(π⋅date)]
2.3 自适应加权与融合
将位置和时间信息分别经过可训练的线性层后,再进行拼接:
X
m
=
c
o
n
c
a
t
(
f
(
l
o
c
^
)
,
f
(
d
a
t
e
^
)
)
X_m = concat(f(\hat{loc}), f(\hat{date}))
Xm=concat(f(loc^),f(date^))
其中,
f
(
⋅
)
f(\cdot)
f(⋅)表示可训练的线性映射。由于位置与时间对分类的贡献不同,因此在拼接时会引入自适应加权,确保不同信息能够按适当比例参与后续特征提取。
3. 早期特征融合
早期特征融合的目标是将多模态信息直接注入原始图像数据中,从而在输入阶段就为视觉网络引入辅助信息。
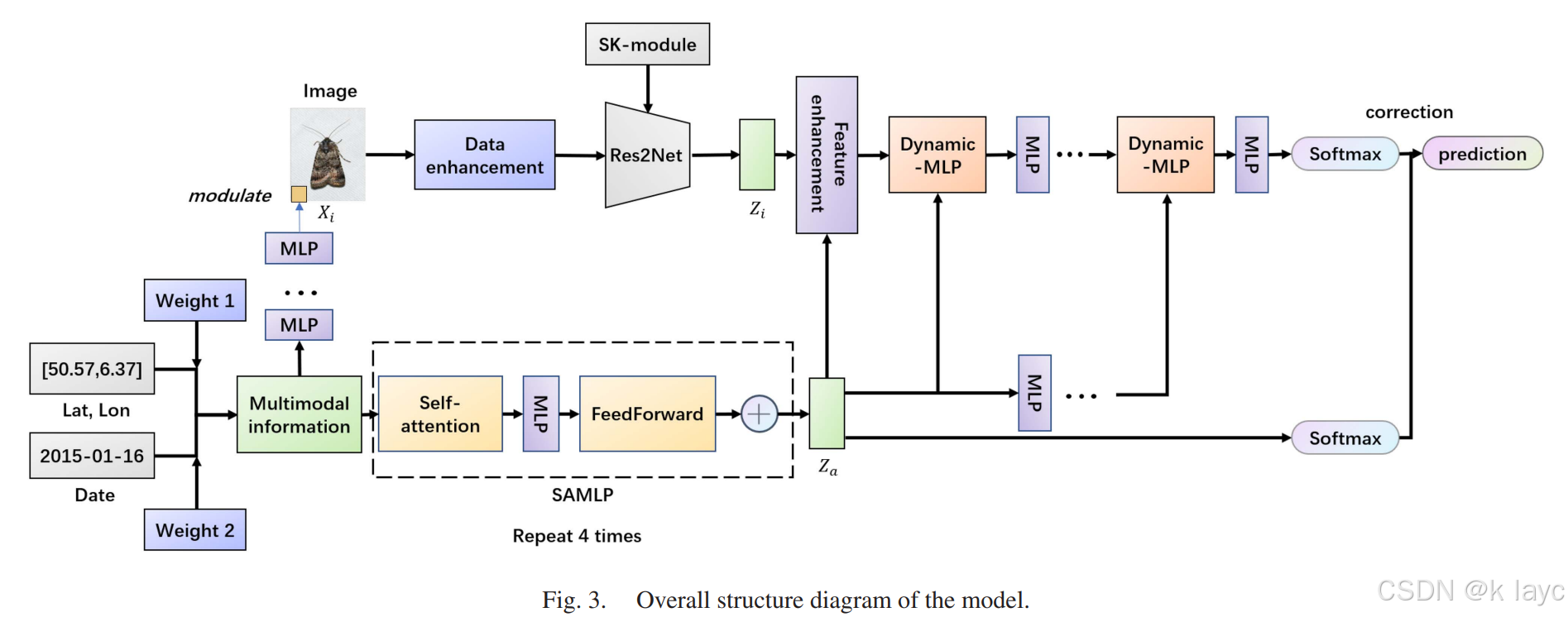
3.1 多模态信息标记的生成
- 生成方法
使用多层MLP从预处理后的 X m X_m Xm中提取初步特征,并调整其尺寸(例如转换为 24 × 24 24\times24 24×24的标记),作为多模态信息标记。生成公式为:
m a r k e r = R e s h a p e ( M L P p ( X m ) ) marker = Reshape(MLP_p(X_m)) marker=Reshape(MLPp(Xm))
其中, M L P p MLP_p MLPp表示用于标记生成的MLP结构。
3.2 标记的添加方法
- 添加策略
论文提出两种添加方式:- 直接替换:将标记数据直接替换图像边缘区域对应的像素值。
- 调制操作:利用标记数据与原图像边缘区域的像素进行逐元素乘积调制:
i m a g e s [ : , : , 0 : 24 , 0 : 24 ] = m a r k e r ⊗ i m a g e s [ : , : , 0 : 24 , 0 : 24 ] images[:, :, 0:24, 0:24] = marker \otimes images[:, :, 0:24, 0:24] images[:,:,0:24,0:24]=marker⊗images[:,:,0:24,0:24]
这种方法只在图像的边缘噪声区域进行,从而避免破坏图像主体信息。
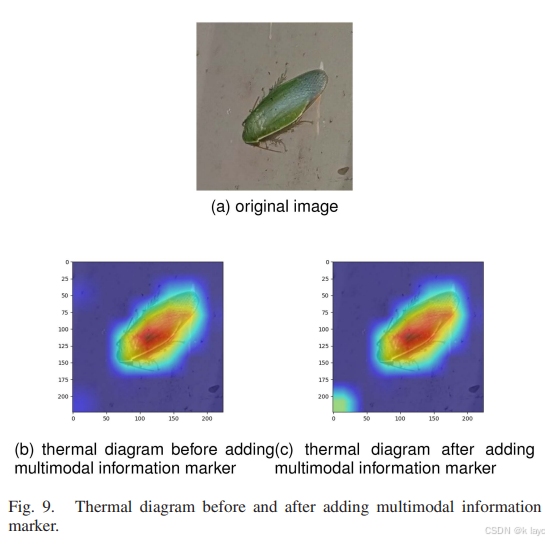
3.3 效果验证
利用Grad-CAM方法绘制热力图,比较添加前后图像的贡献区域,证明多模态信息标记能将原本无效的噪声区域转变为对分类有正贡献的信息。
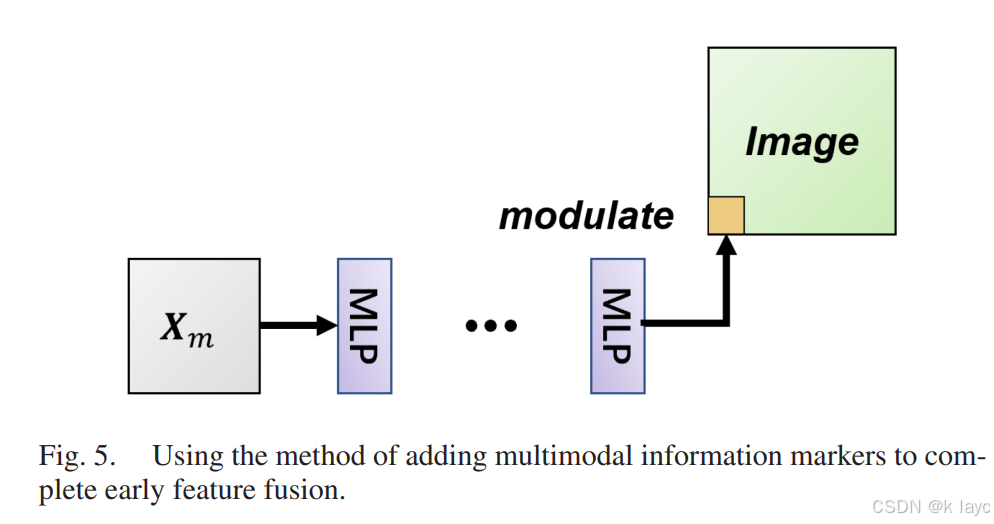
4. 多模态特征提取:SAMLP模块
传统的MLP结构在提取多模态信息时能力有限,论文引入了自注意力机制,将其与MLP相结合,形成SAMLP(Self-Attention MLP)模块,以增强对多模态内部关联性的建模。
4.1 自注意力机制
- 基本原理
对于输入的多模态特征 Z m Z_m Zm,通过生成Query、Key和Value,进行加权求和:
Output = ∑ i a i ( q , k i ) ⋅ v i \text{Output} = \sum_{i} a_i(q, k_i) \cdot v_i Output=i∑ai(q,ki)⋅vi
其中, a i ( q , k i ) a_i(q, k_i) ai(q,ki)表示Query和第 i i i个Key之间的相似度权重,而 v i v_i vi为对应的Value。
4.2 后续MLP与FeedForward层
- 结构设计
自注意力模块之后,接入MLP模块以及带有激活和Dropout的前馈网络,以加深网络层次:
Z m 2 = ReLU ( LN ( f ( Z m 1 ) ) ) Z_m^2 = \text{ReLU}(\text{LN}(f(Z_m^1))) Zm2=ReLU(LN(f(Zm1)))
Z m 3 = f 1 ( D r o p o u t ( ReLU ( f 2 ( Z m 2 ) ) ) ) Z_m^3 = f_1(Dropout(\text{ReLU}(f_2(Z_m^2)))) Zm3=f1(Dropout(ReLU(f2(Zm2))))
最后采用残差连接,将处理后的特征与原始输入 Z m Z_m Zm相加,输出作为最终多模态特征。
5. 晚期特征融合
晚期特征融合旨在将视觉特征和多模态特征在更高层次进行整合,从而获得更强的表示能力。
5.1 融合策略
论文提出了三种策略来实现这一目标:
-
Geo-Prior策略
利用地理和时间信息构建先验概率,基于贝叶斯公式得到:
P ( y ∣ X i , X m ) ∝ P ( y ∣ X i ) ⋅ P ( y ∣ X m ) P(y|X_i, X_m) \propto P(y|X_i) \cdot P(y|X_m) P(y∣Xi,Xm)∝P(y∣Xi)⋅P(y∣Xm)
其中, X i X_i Xi为视觉信息, X m X_m Xm为多模态信息。 -
特征拼接
直接将视觉特征 Z i Z_i Zi与多模态特征 Z m Z_m Zm拼接后输入分类器:
y p r e d = h ( c o n c a t ( Z i , Z m ) ) y_{pred} = h(concat(Z_i, Z_m)) ypred=h(concat(Zi,Zm)) -
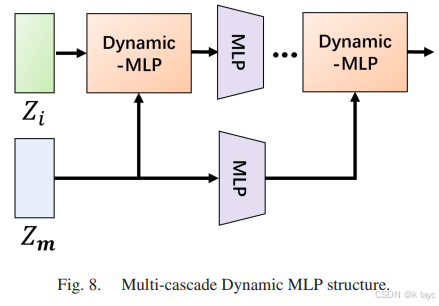
动态MLP结构
设计一个多级级联的动态MLP结构,使得由多模态信息动态生成的权重能够在不同层次上对视觉特征进行过滤和重构,达到更深层次的特征融合。该结构使得视觉信息与多模态信息能够在高维空间中充分互动。
6. 决策校正策略
由于直接特征融合可能仍存在信息冗余或融合不完全的问题,论文引入决策校正策略,在最终预测阶段利用多模态预测结果对融合预测进行校正。
6.1 决策校正原理
设:
- p r e d 1 m pred1_m pred1m:基于融合特征的预测标签及其概率;
- p r e d 2 m pred2_m pred2m:基于多模态特征的预测标签及其概率。
根据标签在两个预测中的出现情况,定义综合概率 t o t a l _ p r o b total\_prob total_prob,其计算分为三种情况:
- Case 1: 标签同时出现在
p
r
e
d
1
m
pred1_m
pred1m与
p
r
e
d
2
m
pred2_m
pred2m中,
t o t a l _ p r o b ( l a b e l ) = p r e d 1 _ m _ p r o b ( l a b e l ) + p r e d 2 _ m _ p r o b ( l a b e l ) total\_prob(label) = pred1\_m\_prob(label) + pred2\_m\_prob(label) total_prob(label)=pred1_m_prob(label)+pred2_m_prob(label) - Case 2: 标签只出现在 p r e d 1 m pred1_m pred1m中,但为第一预测时,采用 p r e d 2 m pred2_m pred2m中第 m m m个预测的概率进行补偿。
- Case 3: 标签只出现在
p
r
e
d
1
m
pred1_m
pred1m中且不在第一预测,则只采用
p
r
e
d
1
m
pred1_m
pred1m的概率:
t o t a l _ p r o b ( l a b e l ) = p r e d 1 _ m _ p r o b ( l a b e l ) total\_prob(label) = pred1\_m\_prob(label) total_prob(label)=pred1_m_prob(label)
6.2 损失函数的改进
为确保融合预测模型和多模态预测模型同时收敛,论文修改了损失函数,并引入标签平滑:
- 定义平滑标签分布:
p i = { 1 − λ , if i = y λ K − 1 , if i ≠ y p_i = \begin{cases} 1-\lambda, & \text{if } i = y \\ \frac{\lambda}{K-1}, & \text{if } i \neq y \end{cases} pi={1−λ,K−1λ,if i=yif i=y - 采用softmax计算预测概率:
q t i = exp ( z t i ) ∑ j = 1 K exp ( z t j ) , q m i = exp ( z m i ) ∑ j = 1 K exp ( z m j ) q_{t_i} = \frac{\exp(z_{t_i})}{\sum_{j=1}^{K}\exp(z_{t_j})}, \quad q_{m_i} = \frac{\exp(z_{m_i})}{\sum_{j=1}^{K}\exp(z_{m_j})} qti=∑j=1Kexp(ztj)exp(zti),qmi=∑j=1Kexp(zmj)exp(zmi) - 定义两个损失:
l o s s 1 = − ∑ i = 1 K p i log q t i , l o s s 2 = − ∑ i = 1 K p i log q m i loss1 = -\sum_{i=1}^{K} p_i \log q_{t_i}, \quad loss2 = -\sum_{i=1}^{K} p_i \log q_{m_i} loss1=−i=1∑Kpilogqti,loss2=−i=1∑Kpilogqmi - 最终总损失为:
l o s s = l o s s 1 + l o s s 2 loss = loss1 + loss2 loss=loss1+loss2
7. 实验部分
论文在多个数据集上(如iNaturalist 2018和iNaturalist 2021的子集INAT18-1K和INAT21-1K,以及INAT2021_mini)进行了大量实验验证各模块的有效性。
7.1 实验配置
- 骨干网络:使用ResNet-50、ResNet-101、Res2Net-101等作为视觉特征提取网络;
- 训练参数:例如批量大小设置为32、初始学习率为0.001,以及采用随机梯度下降(SGD)等策略;
- 数据增强:统一采用mix-up数据增强方法。
7.2 早期特征融合实验
- 通过对不同尺寸(12、24、48)的多模态信息标记进行测试,以及对标记生成(使用不同层数的MLP)和添加方式(直接替换或调制)的对比,实验表明:
- 使用4层MLP生成尺寸为 24 × 24 24\times24 24×24的标记,且采用调制操作能够取得最佳效果;
- 利用Grad-CAM绘制热力图验证,添加标记后图像的边缘区域从原来的低贡献变为对分类有正面贡献。

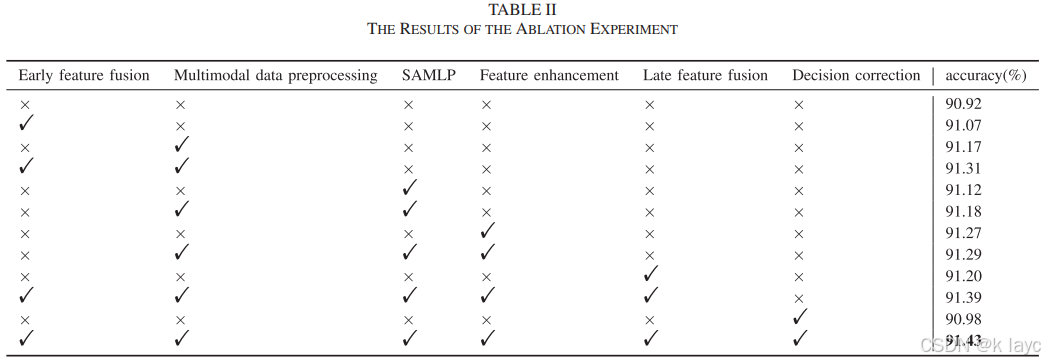
7.3 消融实验
- 分别验证各模块(数据预处理、SAMLP、多时序融合、决策校正)的贡献。
- 单个模块及其组合的使用均能带来分类精度的提升,综合所有模块相比基线模型(仅使用视觉特征)提高约0.51%。
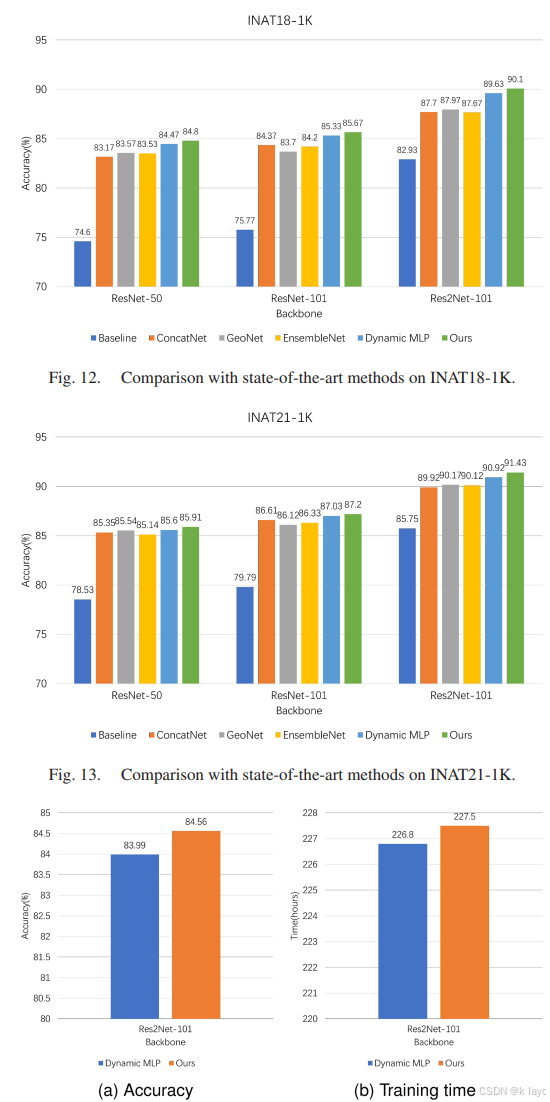
7.4 与现有方法的比较
- 与ConcatNet、GeoawareNet、EnsembleNet以及Dynamic MLP等方法进行对比,结果显示论文提出的方法在分类准确率上均有提升,同时训练时间仅有微小增加(例如在INAT2021_mini数据集上仅增加约0.3%)。
8. 结论与展望
论文提出了一种综合利用多模态信息(主要为拍摄位置和时间)来改进细粒度图像分类的方法。主要贡献包括:
- 多模态数据预处理:将不同信息通过归一化、非线性映射、包装和自适应加权等方法统一处理;
- 多时序特征融合:通过早期的多模态标记注入与晚期的动态MLP深度融合,实现视觉与多模态信息的充分互补;
- SAMLP模块:利用自注意力机制提高多模态信息特征提取效果;
- 决策校正策略:通过对预测结果的校正进一步提高分类准确性,并辅以标签平滑损失函数确保模型稳定收敛。
未来的工作方向可能集中在进一步精简融合结构、提高融合效率以及细化决策校正策略,以期在更低的计算开销下实现更高的分类精度。

















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









