







9. K近邻算法 KNN
- pdf版本下载:https://pan.baidu.com/s/1i48oAI5
- html版本下载:https://pan.baidu.com/s/1c1ODJWk
KNN算法也是经典的机器学习算法之一。本节对这个算法做一个简单的介绍。
1 简介
KNN是K-Neighbor Nearest的缩写,顾名思义,就是要寻找到距离最近的k个点。如果是分类问题,将该点分类为这k个点钟最多的那一类;如果是回归问题,预测值为这k个点的均值。
KNN算法是一个十分简洁容易解释的模型,并且只有k一个参数,这是它的优点。相反的,它也有很多的缺点,比如计算复杂度非常高,并且算法占用的内存很大。这个算法在训练的时候非常容易,就好比一个平常不好好学习的学生,到了考试就开始临时抱佛脚。KNN算法每预测一个测试数据就需要针对训练样本进行一次遍历,因此它的算法复杂度可以达到平方级别。
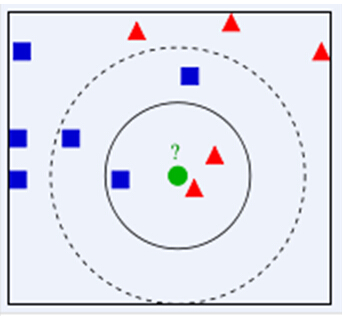
在下图中,假设红色的三角形和蓝色的正方形已经被正确分类,现在我们需要预测绿色圆的分类。依照knn的规则,当我们取k=3时,显然被分类为红三角;当我们取k=5时,被分类为蓝正方形。可以看到,k的取值是对最终的预测结果有较大影响的。
2 算法步骤
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点中出现频率最高的类别作为测试数据的预测分类。
3 算法总结
在算法中衡量距离常用的是欧氏距离:
d(x,y)=∑i=1n(xi−yi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









