







Pytorch中的CrossEntropy
表达式
(1) 二分类
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 p 和1-p 。此时表达式为:
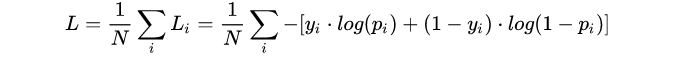
其中:
- yi —— 表示样本i的label,正类为1,负类为0
- pi —— 表示样本i预测为正的概率
(2) 多分类
多分类的情况实际上就是对二分类的扩展:
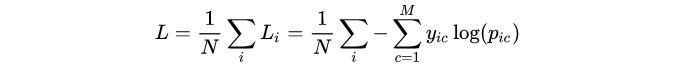
其中:
- M ——类别的数量;
- yic ——指示变量(0或1),如果该类别和样本i的类别相同就是1,否则是0;
- pic ——对于观测样本i属于类别 c 的预测概率。
CrossEntropyLoss()的实现可以参考如下代码
import torch
import torch.nn as nn
loss = nn.CrossEntropyLoss()
input = torch.tensor([[-1., 1],[-1, 1],[1, -1]]) # raw scores correspond to the correct class
# input = torch.tensor([[-3., 3],[-3, 3],[3, -3]]) # raw scores correspond to the correct class with higher confidence
# input = torch.tensor([[1., -1],[1, -1],[-1, 1]]) # raw scores correspond to the incorrect class
# input = torch.tensor([[3., -3],[3, -3],[-3, 3]]) # raw scores correspond to the incorrect class with incorrectly placed confidence
target = torch.tensor([1, 1, 0])
output = loss(input, target)
print(output)
output:tensor(0.1269)
如何计算得到输出
可以注意到target的元素是scalar的列表,它的含义是指定table对应class的index(可以回忆一下one-hot,label class处的值为1而其余为0),而不是y的值。
注意到input是未经sigmoid处理(多分类则是通过softmax处理,sigmoid可以看做是特殊的softmax),这是因为nn.CrossEntropyLoss会对input进行softmax处理。
计算过程如下:
input:
[-1, 1]
[-1, 1]
[1, -1]
target:
[1, 1, 0] 即,选择index=1, 1, 0的input进行loss的计算;
对应的 pic 的计算公式为:
e
p
i
c
/
∑
i
=
0
N
e
p
i
c
e^{p_{ic}}/{\sum_{i=0}^{N}e^{p_{ic}}}
epic/∑i=0Nepic,即
e
x
e
x
+
e
−
x
\frac{e^x}{e^x+e^{-x}}
ex+e−xex,
e
x
e
x
+
e
−
x
\frac{e^x}{e^x+e^{-x}}
ex+e−xex,
e
x
e
x
+
e
−
x
\frac{e^x}{e^x+e^{-x}}
ex+e−xex(注意第三个还是
e
x
e
x
+
e
−
x
\frac{e^x}{e^x+e^{-x}}
ex+e−xex)
因此,
l
o
s
s
=
1
/
3
∗
3
∗
(
−
l
n
e
x
e
x
+
e
−
x
)
=
0.1269
loss = 1/3 *3 * (-ln\frac{e^x}{e^x+e^{-x}}) =0.1269
loss=1/3∗3∗(−lnex+e−xex)=0.1269
交叉熵的计算公式为:
c
r
o
s
s
_
e
n
t
r
o
p
y
=
−
∑
k
=
1
N
(
p
k
∗
log
q
k
)
cross\_entropy=-\sum_{k=1}^{N}\left(p_{k} * \log q_{k}\right)
cross_entropy=−∑k=1N(pk∗logqk)
其中p表示真实值,在这个公式中是one-hot形式;q是预测值,在这里假设已经是经过softmax后的结果了。
如果此处有表述不清,可以参考以下文段,转自https://www.cnblogs.com/marsggbo/p/10401215.html
仔细观察可以知道,因为p的元素不是0就是1,而且又是乘法,所以很自然地我们如果知道1所对应的index,那么就不用做其他无意义的运算了。所以在pytorch代码中target不是以one-hot形式表示的,而是直接用scalar表示。所以交叉熵的公式(m表示真实类别)可变形为:
c
r
o
s
s
_
e
n
t
r
o
p
y
=
−
∑
k
=
1
N
(
p
k
∗
log
q
k
)
=
−
l
o
g
q
m
cross\_entropy=-\sum_{k=1}^{N}\left(p_{k} * \log q_{k}\right)=-log \, q_m
cross_entropy=−∑k=1N(pk∗logqk)=−logqm
即同于log_softmax和nll_loss两个步骤。
所以Pytorch中的F.cross_entropy会自动调用上面介绍的log_softmax和nll_loss来计算交叉熵,其计算方式如下:
loss ( x , class ) = − log ( exp ( x [ class ] ) ∑ j exp ( x [ j ] ) ) \operatorname{loss}(x, \text {class})=-\log \left(\frac{\exp (x[\operatorname{class}])}{\sum_{j} \exp (x[j])}\right) loss(x,class)=−log(∑jexp(x[j])exp(x[class]))















 2513
2513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









