






参考:
https://www.jianshu.com/p/5d9407376c7c
https://www.zhihu.com/question/65288314/answer/849294209
https://www.cnblogs.com/brt2/p/13743440.html
目录:
1: Entropy
2 : Kullback-Leibler
3: Cross Entropy
一 Entropy熵
定义:
熵(Entropy)用于描述一个系统中不确定性
如果一个随机事件X取值为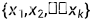 ,
,
概率分布为 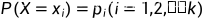 ,
,
则随机变量的熵定义为,
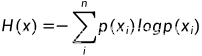
如扔一枚硬币:
事件x : 硬币方向
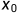 : 代表正面朝上,
: 代表正面朝上,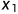 代表方面朝上,
代表方面朝上,
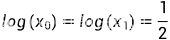
则熵:
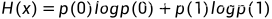
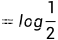
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 15 22:07:03 2023
@author: cxf
"""
import torch
#熵
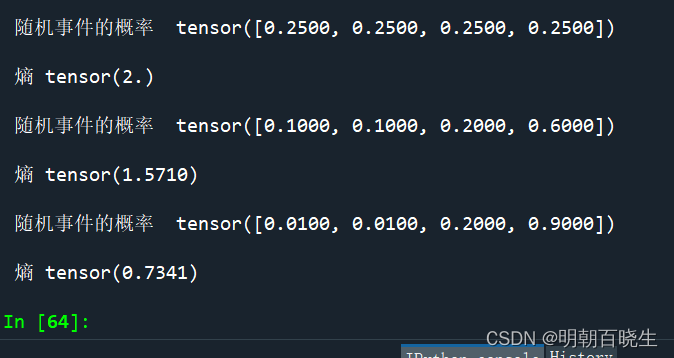
def Entropy(a):
out = -a*torch.log2(a)
print("\n 随机事件的概率 ",a)
print("\n 熵",out.sum())
#运行
def Run():
a = torch.full([4],1/4)
Entropy(a)
a = torch.tensor([0.1,0.1,0.2,0.6])
Entropy(a)
a = torch.tensor([0.01,0.01,0.2,0.9])
Entropy(a)
if __name__ == "__main__":
Run()
二 Kullback-Leibler
散度或信息散度[两个事件分布的不同]
KL散度:
如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 q(x),我们可以使用 KL 散度(Kullback-Leibler divergence)来衡量这两个分布的差异。
在机器学习中,一般p表示真实分布,而q表示预测分布
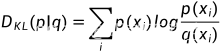
q分布与p分布越接近,KL散度越小,相对熵越小。
三 Cross Entropy
交叉熵:可以用来表示从事件A的角度来看,如何描述事件B。

由交叉熵和熵组成
p,q 分别表示真实分布,以及模型预测分布情况
二分布的时候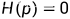 ,散度=交叉熵
,散度=交叉熵
3.1 torch.nn.CrossEntropyLoss
相当于softmax + log + nllloss。
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 23 17:02:06 2023
@author: chengxf2
"""
import numpy as np
import torch as t
import torch.nn.functional as F
def train():
#共三3样本,有5个类别的概率,注意要是float类型
x = t.FloatTensor([[1,1,1,1,1],
[1,1,1,1,2],
[1,2,3,4,5]])
y = t.tensor([1, 1, 0])#这3个样本的标签分别是1,1,0即两个是第2类,一个是第1类。
soft_out = F.softmax(x,dim=1)#给每个样本的pred向量做指数归一化---softmax
log_soft_out = t.log(soft_out)#将上面得到的归一化的向量再point-wise取对数
loss = F.nll_loss(log_soft_out, y)#将归一化且取对数后的张量根据标签求和,实际就是计算loss的过程
print(soft_out)
print(log_soft_out)
print(loss)
loss = F.cross_entropy(x, y)
print(loss)
if __name__ == "__main__":
train()
3.2 NLLLoss
import torch as t
from torch import nn
def NLLLoss_1():
nllloss = nn.NLLLoss()
predict = t.Tensor([[0.2, 0.3, 0.5],
[0.3, 0.7, 0.9]])
label = t.tensor([1, 2])
#将两数取平均后加负号后输出
out = nllloss(predict, label)
print("\n out ",out)
def NLLLoss_2():
nllloss = nn.NLLLoss()
predict = t.Tensor([[0.7,0.2,0.1]]) #shape: (n,category) [0,1,2]
#predict则表示每个类别预测的概率,比如向量(2,3,1)则表示类别0,1,2预测的概率分别为(0.7,0.2,0.1)(先忽略概率大于1的问题)
label = t.tensor([1])
out = nllloss(predict, label)
print("\n out ",out)
if __name__ =="__main__":
NLLLoss_1()














 8095
8095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









