







理论解释
对于p-范数,对于x向量:
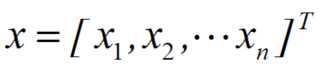
向量x的p-范数为:
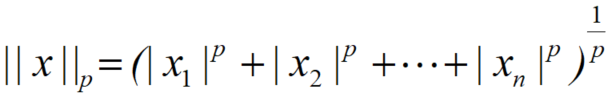
因此,可得到L0、L1、L2范数分别为:
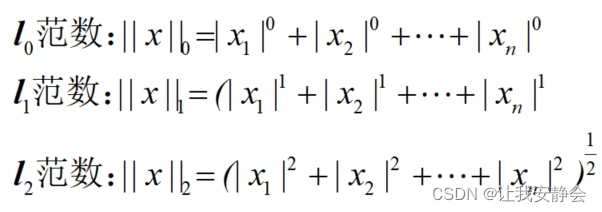
L0范数是指向量中非0的元素的个数
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根(开根号)
L1范数可以进行特征选择,得到稀疏矩阵,仅仅有少量值为非0,这些就是提取出来的特征。
L2范数可以防止过拟合,提升模型的泛化能力,得到的值很小,但不会到0。TiBA6K6p5oiR5a6J6Z2Z5Lya,size_20,color_FFFFFF,t_70,g_se,x_16)
normalize函数详情
部分如下:
from sklearn.preprocessing import normalize
def normalize(X, norm='l2', *, axis=1, copy=True, return_norm=False):
"""
Parameters
----------
X : {array-like, sparse matrix}, shape [n_samples, n_features]
The data to normalize, element by element.
scipy.sparse matrices should be in CSR format to avoid an
un-necessary copy.
norm : 'l1', 'l2', or 'max', optional ('l2' by default)
The norm to use to normalize each non zero sample (or each non-zero
feature if axis is 0).
axis : 0 or 1, optional (1 by default)
axis used to normalize the data along.
If 1, independently normalize each sample,
otherwise (if 0) normalize each feature.
copy : boolean, optional, default True
set to False to perform inplace row normalization and avoid a
copy (if the input is already a numpy array or a scipy.sparse
CSR matrix and if axis is 1).
return_norm : boolean, default False
whether to return the computed norms
Returns
-------
X : {array-like, sparse matrix}, shape [n_samples, n_features]
Normalized input X.
norms : array, shape [n_samples] if axis=1 else [n_features]
An array of norms along given axis for X.
When X is sparse, a NotImplementedError will be raised
for norm 'l1' or 'l2'.
"""
if norm not in ('l1', 'l2', 'max'):
raise ValueError("'%s' is not a supported norm" % norm)
if axis == 0:
sparse_format = 'csc'
elif axis == 1:
sparse_format = 'csr'
else:
raise ValueError("'%d' is not a supported axis" % axis)
X = check_array(X, accept_sparse=sparse_format, copy=copy,
estimator='the normalize function', dtype=FLOAT_DTYPES)
if axis == 0:
X = X.T
if norm == 'l1':
norms = np.abs(X).sum(axis=1)
elif norm == 'l2':
norms = row_norms(X)
elif norm == 'max':
norms = np.max(abs(X), axis=1)
norms = _handle_zeros_in_scale(norms, copy=False)
X /= norms[:, np.newaxis]
if return_norm:
return X, norms
else:
return X
Note
- X shape [n_samples, n_features]
- norm有l1,l2,max三种可选。
- axis=1,按行进行归一化(normalize each sample);
- axis=0,按列进行归一化(normalize each feature)。
if axis == 0: # 列
sparse_format = 'csc' # csc是按列存储一个稀疏矩阵
elif axis == 1: # 行
sparse_format = 'csr' # csr是按行存储一个稀疏矩阵
参考:
- L0范式、L1范式、L2范式解释通俗版:https://blog.csdn.net/qq_43170213/article/details/97375510
- 机器学习中正则化项L1和L2的直观理解:https://blog.csdn.net/panghaomingme/article/details/54022709?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1
- 稀疏矩阵的定义(COO、CSC、CSR):https://www.jianshu.com/p/9671c568096d

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









