






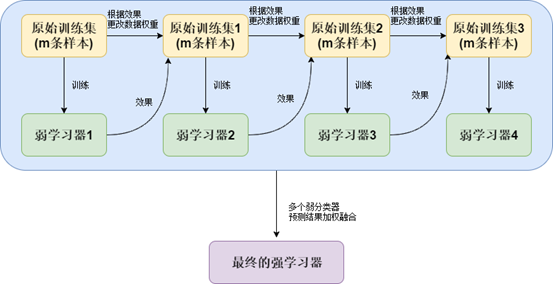
boosting是集成学习的一种思想,可以用于回归和分类问题;多伦迭代(全部数据) 每一轮产生一个弱分类器;将弱分类器预测结果相加得到强分类器的最终结果
常见模型有Adaboost,GBDT,xgboost
目录
Adaboost简介
权重与函数的关系
Adaboost算法构建过程
sklearn_learn实现
总结
Adaboost简介
对样本赋予权重,采用迭代的方式来构造每一步的弱分类器
通过弱分类器的linearblending得到强分类器
G(x) =a₁g₁(x) + a₂g₂(x)+a₃g₃(x) ...+an*gn(x)
那么每个弱分类器g(x)及对应的a怎么确认?
通过赋予样本不同的权重,使得本次训练的弱分类器在上次弱分类器的不好的地方进行训练来获得本次的基分类器
基分类器g(x)大多使用decision-stump(决策桩)
权重与函数的关系
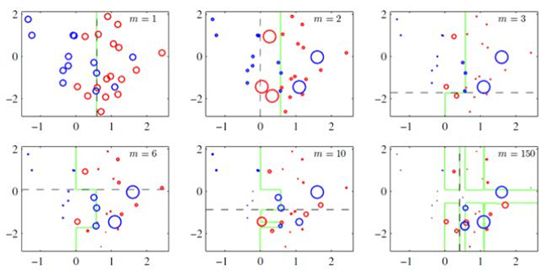
对于同一个算法:
训练集不同,生成的模型一定不同
如果训练集相同,调整训练集中数据的权重,生成的模型也一定不同
对于同一个模型:
输入的数据权重不同 模型预测的正确率也一定不同
可以通过调整输入数据的权重,让本来还不错的分类器的正确率达到1/2
样本加权示意图
Adaboost算法构建过程
1、假设训练集数据集T = {(X1,Y1),(X2,Y2)...(Xn,Yn)}
2、初始化训练数据权重分布
D1 =(W11,W12,....W1i...W1n) ,W1i = 1/n ,i = 1,2,....N
3、使用具有权值分布Dm的训练数据集学习,得到基本分类器(类似cart树构建,决策桩)
Gm(x):x--> {-1,+1}
4、计算本次Gm(x)模型的权重系数a (ε为错误率)
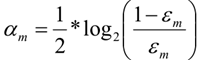
5、通过调整输入数据的权重,让本次还不错的分类器的正确率达到1/2,得到下一次训练数据的样本权重
设 错误(t+1) / (错误(t+1)+正确(t+1) ) = 1/2
所以 错误(t+1) =正确(t+1)
得 错误t * 正确t个数 = 正确t*错误t个数
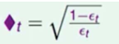
可以使 正确(t+1) = 正确t /∆t
错误权重(t+1) = 错误t * ∆t
6、构建基本分类器的线性组合
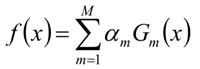
7、得到最终分类器
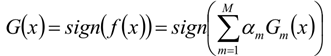
举列子理解Adaboost
1、训练集

2、初始化训练数据集的权值分布
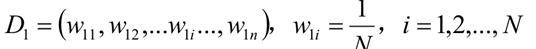
所有W1i = 0.1
3、第一轮迭代时候,则有

4、在上图带权重分布D1的训练集上,可得到基分类器
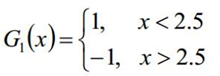
5、G1(x)在训练集上的错误率ε1 = P(G1(xi!=yi))=0.3
6、根据公式计算出G1基分类器的系数a1 = 1/2 log(1-ε1)/ε1 = 0.6112
7、更新数据D1的权值,将G1的正确率降低为 1/2
正确(t+1) = 正确t / ∆t
错误权重(t+1) = 错误t * ∆t
所以D2的根据权重为 0.0582,0.0582,0.0582,0.0582,0.0582,0.0582,0.1976,0.1976,0.1976 ,0.0582
8、则对于第二轮迭代

9、在权值分布D2的训练集上,又可得到基分类器G2
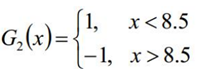
10、同样获得G2(x)分类器的系数a
ε1 =P(G2(xi!=yi))=0.1746
a2 = 1/2log(1-ε2)/ε2 =1.1205
11、以后以此类推,分类器
F(x) =sign(0.6112G1(x) + 1.1205G2(x) + 1.631G3(x) ) 在训练集上有0个误分类点;结束循环
scikit_learn实现

code:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import zero_one_lossfrom sklearn.ensemble import AdaBoostClassifierimport time
a = time.time()
n_estimators = 400learning_rate = 1.0X, y = datasets.make_hastie_10_2(n_samples=12000, random_state=1)X_test, y_test = X[10000:], y[10000:]X_train, y_train = X[:2000], y[:2000]
# 决策树桩dt_stump = DecisionTreeClassifier(max_depth=1, min_samples_leaf=1)dt_stump.fit(X_train, y_train)dt_stump_err = 1.0 - dt_stump.score(X_test, y_test)
# 决策树dt = DecisionTreeClassifier(max_depth=9, min_samples_leaf=1)dt.fit(X_train, y_train)dt_err = 1.0 - dt.score(X_train, y_test)
# 决策树桩的生成ada_discrete = AdaBoostClassifier(base_estimator=dt_stump, learning_rate=learning_rate, n_estimators=n_estimators, algorithm='SAMME')ada_discrete.fit(X_train, y_train)
ada_real = AdaBoostClassifier(base_estimator=dt_stump, learning_rate=learning_rate, n_estimators=n_estimators, algorithm='SAMME.R') # 相比于ada_discrete只改变了Algorithm参数ada_real.fit(X_train, y_train)
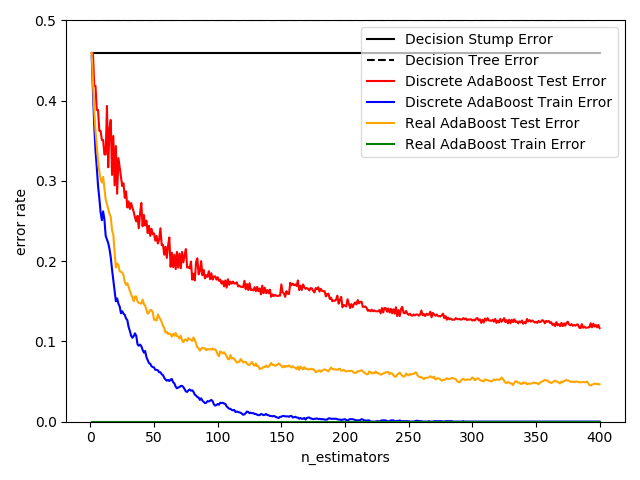
fig = plt.figure()ax = fig.add_subplot(111)ax.plot([1, n_estimators], [dt_stump_err] * 2, 'k-', label='Decision Stump Error')ax.plot([1, n_estimators], [dt_err] * 2, 'k--', label='Decision Tree Error')
ada_discrete_err = np.zeros((n_estimators,))for i, y_pred in enumerate(ada_discrete.staged_predict(X_test)): ada_discrete_err[i] = zero_one_loss(y_pred, y_test) # 0-1损失,类似于指示函数ada_discrete_err_train = np.zeros((n_estimators,))for i, y_pred in enumerate(ada_discrete.staged_predict(X_train)): ada_discrete_err_train[i] = zero_one_loss(y_pred, y_train)
ada_real_err = np.zeros((n_estimators,))for i, y_pred in enumerate(ada_real.staged_predict(X_test)): ada_real_err[i] = zero_one_loss(y_pred, y_test)ada_real_err_train = np.zeros((n_estimators,))for i, y_pred in enumerate(ada_real.staged_predict(X_train)): ada_discrete_err_train[i] = zero_one_loss(y_pred, y_train)
ax.plot(np.arange(n_estimators) + 1, ada_discrete_err, label='Discrete AdaBoost Test Error', color='red')ax.plot(np.arange(n_estimators) + 1, ada_discrete_err_train, label='Discrete AdaBoost Train Error', color='blue')ax.plot(np.arange(n_estimators) + 1, ada_real_err, label='Real AdaBoost Test Error', color='orange')ax.plot(np.arange(n_estimators) + 1, ada_real_err_train, label='Real AdaBoost Train Error', color='green')
ax.set_ylim((0.0, 0.5))ax.set_xlabel('n_estimators')ax.set_ylabel('error rate')
leg = ax.legend(loc='upper right', fancybox=True)leg.get_frame().set_alpha(0.7)b = time.time()print('total running time of this example is :', (b - a))plt.show()
总结
Adaboost优点:
可以处理连续值和离散值
模型的鲁棒性比较强
解释强,结构简单
Adaboost缺点:
对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果
往期精选

关注公众号,加小编微信即可拉入线上交流群















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









