









 本文概述了TransformerEncoder的工作原理,包括输入字向量、PositionEncoding加入位置信息、ResidualConnection保留位置信息、KQV计算字间相关性、Self-attention和Multi-headattention的机制,以及Feedforward层的作用。文章详细描述了维度变化过程和各模块在保持句子结构信息上的作用。
本文概述了TransformerEncoder的工作原理,包括输入字向量、PositionEncoding加入位置信息、ResidualConnection保留位置信息、KQV计算字间相关性、Self-attention和Multi-headattention的机制,以及Feedforward层的作用。文章详细描述了维度变化过程和各模块在保持句子结构信息上的作用。
参考了这篇文章以及chatGPT的内容,这篇博客将会总结个人对Transformer Encoder的简单理解。(推荐看看原文)
总的来说,一个block的输入是一个句子中每个字,他的输出是也是一个句子,只不过每个字都加了他和这句话里其他字之间的相关性。一般transformer中都会有多个block,每个block代表一种隐藏空间(the latent space,有点抽象,或者说某个维度),那么一个block的输出就是一句话,其中每个字都加了这个隐藏空间中这个字与这句话其他字的相关性,所以当多个block堆叠在一起之后,他的输出就是一句话,他的每个字都加了不同block代表的隐藏空间中这个字和其他字的相关性(multi-head的话就是不同的相关性)。
接下来,通俗的介绍不同模块。故事从一个句子被输入到一个encoder的block开始。一个句子中的每个字都被表示成一个向量,他们排在一起表示成一个句子。
(以下的图来自引用的文章里的,如果侵权,就会删掉)。
Encoder中一个block的结构
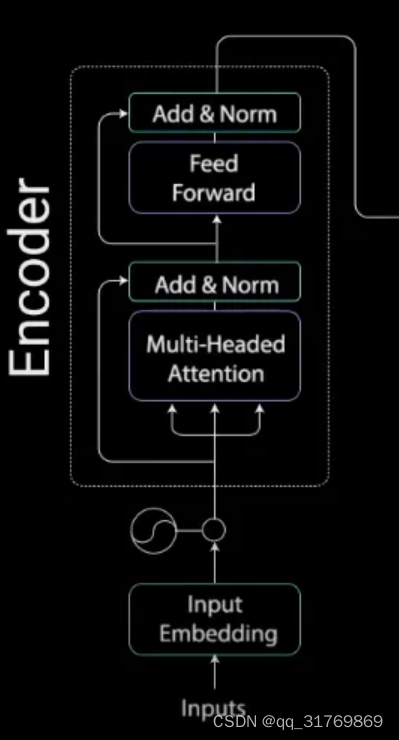
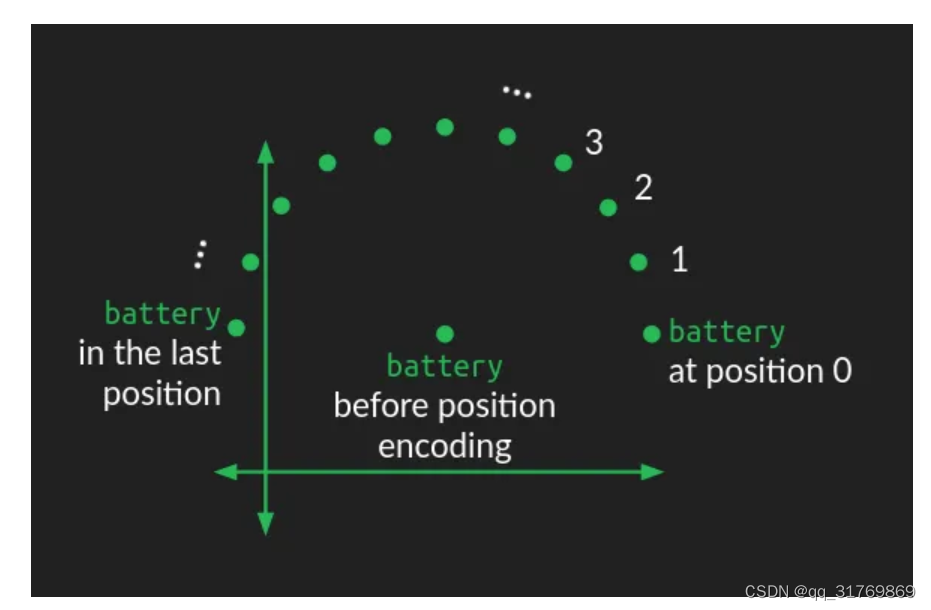
Position Encoding
这个部分的功能是加入位置信息,也就是每个字是这个句子的第几个字。这样做的原因是block中的操作不能考虑到位置信息,但是位置信息又很重要,比如“我爱”和“爱我”是两种意思。如果不加入每个字的位置,block就不知道他们的先后。
从实现的方式的角度看,其实是对每个字向量分别加了一个能够代表自己位置信息的向量(为了不会与其他字混淆,这个字向量改变的很小)。不管怎么样,从结果来看,每个字向量通过有规律的扰动来使得自己的向量中包含了位置信息,具体细节参考这篇文章(其中第三部分embeddings和9.1部分)。
灵魂拷问:为什么一开始加入了位置信息,这个位置信息就能一直保持在向量里呢?这么复杂的encoder,它难道不会把位置信息弄丢吗?
Residual Connection
这个的作用有很多,巴拉巴拉,其中,我觉得有一个很大的理由是它能保留一些必要特征,就比如字向量中的位置信息。这也就解释了位置信息是如何保留的问题。
K,Q ,V
简单来说,这三个向量是为了计算这个字与其他字的相关性的。接下来看一下他们是如果计算的,和之前一样,我不会加入难懂的任何部分。
首先,一句话里的每个字都需要计算出他们的K,Q,V向量,这个计算的方法就是在每个字向量后面分别加3个不共享参数的线性层,分别线性的转化为K,Q,V。也就是说计算一个字的一个需要的向量(K,Q,V),都需要一个线性层。
接下来,只对一个字进行分析,其他字做相同操作。
接着,每个字的Q向量和这句话里所有字的K向量做一些运算,结果是得到一个向量 R i R_i Ri,第i个位置代表这个字与第i个字之间相关度的值。
最后 R i R_i Ri的每个值和第i个V向量的每个值对应相乘,之后相加(也就是说R向量的每个值当作权重,将所有V向量weighted sum),它的结果是一个向量(context vector),代表着这个字和其他字的相关性。其实这个向量的名字取得真的很贴切,它是代表自己上下文的向量!
了解了每个字是如何计算出context vector了(也就是如果计算出自己和其他字的相关性向量),那么所有字的计算可以统一写成矩阵的形式。
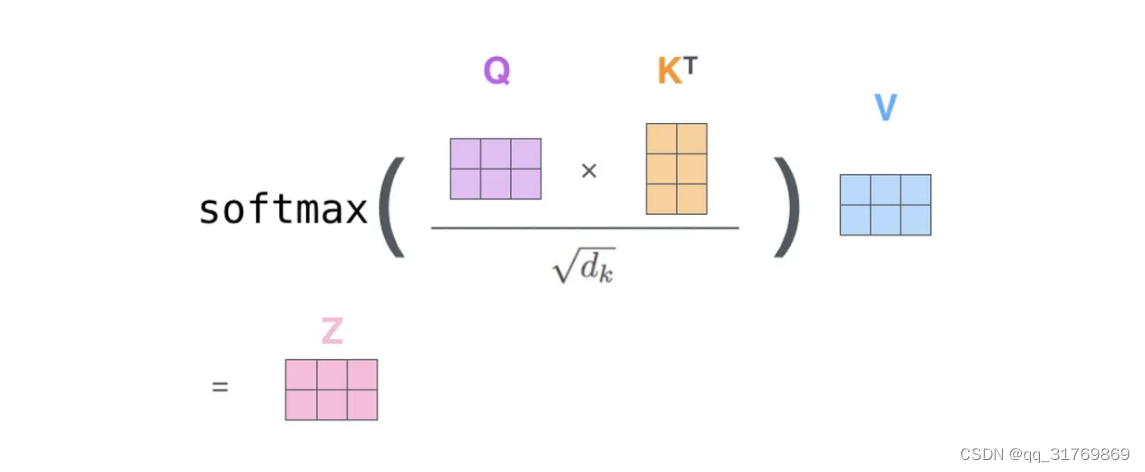
这里可以看到我说的R向量其实就是softmax计算后的结果,只不过这里是不同字的R向量所构成的矩阵,代表每个字之间的相关度矩阵。softmax里有个分母,其中 d k d_k dk是k向量的维度,加入这一项的目的是为了训练的时候更加的稳定。
Self-attention
Single-head attention
什么是head? 其实刚刚K,Q,V的计算就是一个head。
从整体上看,single-head的作用是,输入一个句子里的每个字向量,输出是每个字对应的context vector(每个字与其他字的相关性)
为了之后进行residual操作,也就是加上原来的向量,它用了一个线形层使得他们的维度一致。维度的事情,在下面会聊。
Multi-head attention
了解了single-head,multi-head重复做了几次和single-head一样的运算,然后把产生的context vectors拼接在一起,在做一次线性变化(输入到线性层,这里注意,不同的context vector输入到不同的线形层,所以,这些context vector并没有融合相关性的特征,只是拼接在一起),得到最终的拼接的向量。
举个列子,对于每个字来说, 10个head就对这个字进行10次K,Q,V的计算,他们的参数不共享(产生K,Q,V的线性模型参数,从上面的小节中,你应该也发现了,K,Q,V的计算不需要额外的参数),这样对于每个字就会得到10个context vectors。接着10个context vectors拼在一起,就像排队一样,之后输入到对应的10个线形层,进行线性变换,最终得到拼接的向量,
Feedforward
self-attention得到的向量依次输入到这个FFN中,他的输出的向量维度和输入block时的维度一致,也就是加了position embedding的维度一致,这是为了之后的block可以堆叠在一起。之后做一些之前都讲过的操作,就得到最后的结果了。
Q:这个层和之前一直说的线性层有什么区别呢?
A:它有非线性的激活函数。
Q:为什么需要它?
A:修改维度、特征提取等等(我觉得,它还有一个作用是将这些包含相关性的向量转换到另外的隐性空间,通过非线性的函数)
关于维度
是时候了解一个字从出生到穿过一个block之后的维度大小了!以下是一个字如何穿过single-head attention mechanism的block。
这个字向量最开始的维度是m,当他加入位置信息以后,他的维度还是m,然后他就进入block了,首先它将碰到3个线性层,将其变成维度是n的K,Q,V向量,之后他们计算,得到维度还是n的context vector,接着它穿过一个线形层,他的维度就转变为m,之后它进行add&norm,维度还是m,之后进入FFN,出来后还是m,之后又来一次add&norm,就离开了block!
multi-head attention mechanism的block,其他是一样的,不过,它因为有多个头,进入block后,他会碰到3head个线性层,得到head个context vectors,每个context vector的维度是n,拼接起来后是维度是nhead,他们各自穿过自己的线性层,得到最终的向量的维度是m,之后就一样了!
ok!这就是所有内容,如果你喜欢可以打赏我1元,提前向你表示感谢!!!


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









