







简介
在上一篇【MindSpore易点通】Transformer的注意力机制帖子中,跟大家分享了注意力机制的结构和原理。基于上篇内容,本次再和大家一起解锁下Transformer中的Encoder和Decoder以及Softmax部分。
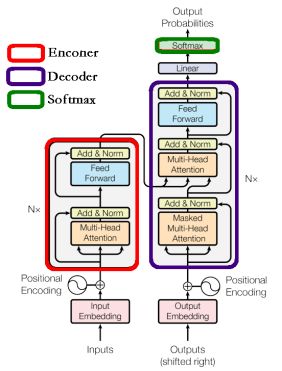
Encoder结构
图中红框内就是Transformer的Encoder block结构,从下到上是由Multi-Head Attention-->Add & Norm-->Feed Forward-->Add & Norm组成的。因为Multi-Head Attention部分比较复杂,所以单独有分享:【MindSpore易点通】Transformer的注意力机制,了解了Multi-Head Attention的结构和计算过程,现在重点解析下Add & Norm和Feed Forward部分。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7062
7062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









