






Yolo-v3 and Yolo-v2 for Windows and Linux
(neural network for object detection) - Tensor Cores can be used on Linux and Windows
- Improvements in this repository
- How to use
- How to compile on Linux
- How to compile on Windows
- How to train (Pascal VOC Data)
- How to train (to detect your custom objects)
- When should I stop training
- How to calculate mAP on PascalVOC 2007
- How to improve object detection
- How to mark bounded boxes of objects and create annotation files
- Using Yolo9000
- How to use Yolo as DLL
| |
|---|
- YOLOv3-spp (is not indicated) better than YOLOv3 - mAP = 60.6%, FPS = 20: https://pjreddie.com/darknet/yolo/
- Yolo v3 source chart for the RetinaNet on MS COCO got from Table 1 (e): https://arxiv.org/pdf/1708.02002.pdf
- Yolo v2 on Pascal VOC 2007: https://hsto.org/files/a24/21e/068/a2421e0689fb43f08584de9d44c2215f.jpg
- Yolo v2 on Pascal VOC 2012 (comp4): https://hsto.org/files/3a6/fdf/b53/3a6fdfb533f34cee9b52bdd9bb0b19d9.jpg
"You Only Look Once: Unified, Real-Time Object Detection (versions 2 & 3)"
A Yolo cross-platform Windows and Linux version (for object detection). Contributtors: https://github.com/pjreddie/darknet/graphs/contributors
This repository is forked from Linux-version: https://github.com/pjreddie/darknet
More details: http://pjreddie.com/darknet/yolo/
This repository supports:
- both Windows and Linux
- both OpenCV 2.x.x and OpenCV <= 3.4.0 (3.4.1 and higher isn't supported)
- both cuDNN v5-v7
- CUDA >= 7.5
- also create SO-library on Linux and DLL-library on Windows
Requires:
- Linux GCC>=4.9 or Windows MS Visual Studio 2015 (v140): https://go.microsoft.com/fwlink/?LinkId=532606&clcid=0x409 (or offline ISO image)
- CUDA 10.0: https://developer.nvidia.com/cuda-toolkit-archive (on Linux do Post-installation Actions)
- OpenCV 3.3.0: https://sourceforge.net/projects/opencvlibrary/files/opencv-win/3.3.0/opencv-3.3.0-vc14.exe/download
- or OpenCV 2.4.13: https://sourceforge.net/projects/opencvlibrary/files/opencv-win/2.4.13/opencv-2.4.13.2-vc14.exe/download
- OpenCV allows to show image or video detection in the window and store result to file that specified in command line
-out_filename res.avi
- OpenCV allows to show image or video detection in the window and store result to file that specified in command line
- GPU with CC >= 3.0: https://en.wikipedia.org/wiki/CUDA#GPUs_supported
Pre-trained models for different cfg-files can be downloaded from (smaller -> faster & lower quality):
yolov3-openimages.cfg(247 MB COCO Yolo v3) - requires 4 GB GPU-RAM: https://pjreddie.com/media/files/yolov3-openimages.weightsyolov3-spp.cfg(240 MB COCO Yolo v3) - requires 4 GB GPU-RAM: https://pjreddie.com/media/files/yolov3-spp.weightsyolov3.cfg(236 MB COCO Yolo v3) - requires 4 GB GPU-RAM: https://pjreddie.com/media/files/yolov3.weightsyolov3-tiny.cfg(34 MB COCO Yolo v3 tiny) - requires 1 GB GPU-RAM: https://pjreddie.com/media/files/yolov3-tiny.weightsyolov2.cfg(194 MB COCO Yolo v2) - requires 4 GB GPU-RAM: https://pjreddie.com/media/files/yolov2.weightsyolo-voc.cfg(194 MB VOC Yolo v2) - requires 4 GB GPU-RAM: http://pjreddie.com/media/files/yolo-voc.weightsyolov2-tiny.cfg(43 MB COCO Yolo v2) - requires 1 GB GPU-RAM: https://pjreddie.com/media/files/yolov2-tiny.weightsyolov2-tiny-voc.cfg(60 MB VOC Yolo v2) - requires 1 GB GPU-RAM: http://pjreddie.com/media/files/yolov2-tiny-voc.weightsyolo9000.cfg(186 MB Yolo9000-model) - requires 4 GB GPU-RAM: http://pjreddie.com/media/files/yolo9000.weights
Put it near compiled: darknet.exe
You can get cfg-files by path: darknet/cfg/
Examples of results:
Others: https://www.youtube.com/channel/UC7ev3hNVkx4DzZ3LO19oebg
Improvements in this repository
- added support for Windows
- improved binary neural network performance 2x-4x times for Detection on CPU and GPU if you trained your own weights by using this XNOR-net model (bit-1 inference) : https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny_xnor.cfg
- improved neural network performance ~7% by fusing 2 layers into 1: Convolutional + Batch-norm
- improved neural network performance Detection 3x times, Training 2 x times on GPU Volta (Tesla V100, Titan V, ...) using Tensor Cores if
CUDNN_HALFdefined in theMakefileordarknet.sln - improved performance ~1.2x times on FullHD, ~2x times on 4K, for detection on the video (file/stream) using
darknet detector demo... - improved performance 3.5 X times of data augmentation for training (using OpenCV SSE/AVX functions instead of hand-written functions) - removes bottleneck for training on multi-GPU or GPU Volta
- improved performance of detection and training on Intel CPU with AVX (Yolo v3 ~85%, Yolo v2 ~10%)
- fixed usage of
[reorg]-layer - optimized memory allocation during network resizing when
random=1 - optimized initialization GPU for detection - we use batch=1 initially instead of re-init with batch=1
- added correct calculation of mAP, F1, IoU, Precision-Recall using command
darknet detector map... - added drawing of chart of average loss during training
- added calculation of anchors for training
- added example of Detection and Tracking objects: https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp
- fixed code for use Web-cam on OpenCV 3.x
- run-time tips and warnings if you use incorrect cfg-file or dataset
- many other fixes of code...
And added manual - How to train Yolo v3/v2 (to detect your custom objects)
Also, you might be interested in using a simplified repository where is implemented INT8-quantization (+30% speedup and -1% mAP reduced): https://github.com/AlexeyAB/yolo2_light
How to use:
Example of usage in cmd-files from build\darknet\x64\:
-
darknet_yolo_v3.cmd- initialization with 236 MB Yolo v3 COCO-model yolov3.weights & yolov3.cfg and show detection on the image: dog.jpg -
darknet_voc.cmd- initialization with 194 MB VOC-model yolo-voc.weights & yolo-voc.cfg and waiting for entering the name of the image file -
darknet_demo_voc.cmd- initialization with 194 MB VOC-model yolo-voc.weights & yolo-voc.cfg and play your video file which you must rename to: test.mp4 -
darknet_demo_store.cmd- initialization with 194 MB VOC-model yolo-voc.weights & yolo-voc.cfg and play your video file which you must rename to: test.mp4, and store result to: res.avi -
darknet_net_cam_voc.cmd- initialization with 194 MB VOC-model, play video from network video-camera mjpeg-stream (also from you phone) -
darknet_web_cam_voc.cmd- initialization with 194 MB VOC-model, play video from Web-Camera number #0 -
darknet_coco_9000.cmd- initialization with 186 MB Yolo9000 COCO-model, and show detection on the image: dog.jpg -
darknet_coco_9000_demo.cmd- initialization with 186 MB Yolo9000 COCO-model, and show detection on the video (if it is present): street4k.mp4, and store result to: res.avi
How to use on the command line:
On Linux use ./darknet instead of darknet.exe, like this:./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights
- Yolo v3 COCO - image:
darknet.exe detector test data/coco.data cfg/yolov3.cfg yolov3.weights -i 0 -thresh 0.25 - Output coordinates of objects:
darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights -ext_output dog.jpg - Yolo v3 COCO - video:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -ext_output test.mp4 - Yolo v3 COCO - WebCam 0:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -c 0 - Yolo v3 COCO for net-videocam - Smart WebCam:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg - Yolo v3 - save result to the file res.avi:
darknet.exe detector demo data/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 test.mp4 -out_filename res.avi - Yolo v3 Tiny COCO - video:
darknet.exe detector demo data/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights test.mp4 - Yolo v3 Tiny on GPU #0:
darknet.exe detector demo data/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -i 0 test.mp4 - Alternative method Yolo v3 COCO - image:
darknet.exe detect cfg/yolov3.cfg yolov3.weights -i 0 -thresh 0.25 - 186 MB Yolo9000 - image:
darknet.exe detector test cfg/combine9k.data yolo9000.cfg yolo9000.weights - Remeber to put data/9k.tree and data/coco9k.map under the same folder of your app if you use the cpp api to build an app
- To process a list of images
data/train.txtand save results of detection toresult.txtuse:
darknet.exe detector test cfg/coco.data yolov3.cfg yolov3.weights -dont_show -ext_output < data/train.txt > result.txt
For using network video-camera mjpeg-stream with any Android smartphone:
-
Download for Android phone mjpeg-stream soft: IP Webcam / Smart WebCam
- Smart WebCam - preferably: https://play.google.com/store/apps/details?id=com.acontech.android.SmartWebCam2
- IP Webcam: https://play.google.com/store/apps/details?id=com.pas.webcam
-
Connect your Android phone to computer by WiFi (through a WiFi-router) or USB
-
Start Smart WebCam on your phone
-
Replace the address below, on shown in the phone application (Smart WebCam) and launch:
- Yolo v3 COCO-model:
darknet.exe detector demo data/coco.data yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg -i 0
How to compile on Linux:
Just do make in the darknet directory. Before make, you can set such options in the Makefile: link
GPU=1to build with CUDA to accelerate by using GPU (CUDA should be in/usr/local/cuda)CUDNN=1to build with cuDNN v5-v7 to accelerate training by using GPU (cuDNN should be in/usr/local/cudnn)CUDNN_HALF=1to build for Tensor Cores (on Titan V / Tesla V100 / DGX-2 and later) speedup Detection 3x, Training 2xOPENCV=1to build with OpenCV 3.x/2.4.x - allows to detect on video files and video streams from network cameras or web-camsDEBUG=1to bould debug version of YoloOPENMP=1to build with OpenMP support to accelerate Yolo by using multi-core CPULIBSO=1to build a librarydarknet.soand binary runable fileuselibthat uses this library. Or you can try to run soLD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib test.mp4How to use this SO-library from your own code - you can look at C++ example: https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp or use in such a way:LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov3.cfg yolov3.weights test.mp4
To run Darknet on Linux use examples from this article, just use ./darknet instead of darknet.exe, i.e. use this command: ./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights
How to compile on Windows:
-
If you have MSVS 2015, CUDA 10.0, cuDNN 7.4 and OpenCV 3.x (with paths:
C:\opencv_3.0\opencv\build\include&C:\opencv_3.0\opencv\build\x64\vc14\lib), then start MSVS, openbuild\darknet\darknet.sln, set x64 and Release https://hsto.org/webt/uh/fk/-e/uhfk-eb0q-hwd9hsxhrikbokd6u.jpeg and do the: Build -> Build darknet. Also add Windows system variablecudnnwith path to CUDNN: https://hsto.org/files/a49/3dc/fc4/a493dcfc4bd34a1295fd15e0e2e01f26.jpg NOTE: If installing OpenCV, use OpenCV 3.4.0 or earlier. This is a bug in OpenCV 3.4.1 in the C API (see #500).1.1. Find files
opencv_world320.dllandopencv_ffmpeg320_64.dll(oropencv_world340.dllandopencv_ffmpeg340_64.dll) inC:\opencv_3.0\opencv\build\x64\vc14\binand put it near withdarknet.exe1.2 Check that there are
binandincludefolders in theC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1if aren't, then copy them to this folder from the path where is CUDA installed1.3. To install CUDNN (speedup neural network), do the following:
-
download and install cuDNN v7.4.1 for CUDA 10.0: https://developer.nvidia.com/cudnn
-
add Windows system variable
cudnnwith path to CUDNN: https://hsto.org/files/a49/3dc/fc4/a493dcfc4bd34a1295fd15e0e2e01f26.jpg
1.4. If you want to build without CUDNN then: open
\darknet.sln-> (right click on project) -> properties -> C/C++ -> Preprocessor -> Preprocessor Definitions, and remove this:CUDNN; -
-
If you have other version of CUDA (not 10.0) then open
build\darknet\darknet.vcxprojby using Notepad, find 2 places with "CUDA 10.0" and change it to your CUDA-version, then do step 1 -
If you don't have GPU, but have MSVS 2015 and OpenCV 3.0 (with paths:
C:\opencv_3.0\opencv\build\include&C:\opencv_3.0\opencv\build\x64\vc14\lib), then start MSVS, openbuild\darknet\darknet_no_gpu.sln, set x64 and Release, and do the: Build -> Build darknet_no_gpu -
If you have OpenCV 2.4.13 instead of 3.0 then you should change pathes after
\darknet.slnis opened4.1 (right click on project) -> properties -> C/C++ -> General -> Additional Include Directories:
C:\opencv_2.4.13\opencv\build\include4.2 (right click on project) -> properties -> Linker -> General -> Additional Library Directories:
C:\opencv_2.4.13\opencv\build\x64\vc14\lib -
If you have GPU with Tensor Cores (nVidia Titan V / Tesla V100 / DGX-2 and later) speedup Detection 3x, Training 2x:
\darknet.sln-> (right click on project) -> properties -> C/C++ -> Preprocessor -> Preprocessor Definitions, and add here:CUDNN_HALF;Note: CUDA must be installed only after that MSVS2015 had been installed.
How to compile (custom):
Also, you can to create your own darknet.sln & darknet.vcxproj, this example for CUDA 9.1 and OpenCV 3.0
Then add to your created project:
- (right click on project) -> properties -> C/C++ -> General -> Additional Include Directories, put here:
C:\opencv_3.0\opencv\build\include;..\..\3rdparty\include;%(AdditionalIncludeDirectories);$(CudaToolkitIncludeDir);$(cudnn)\include
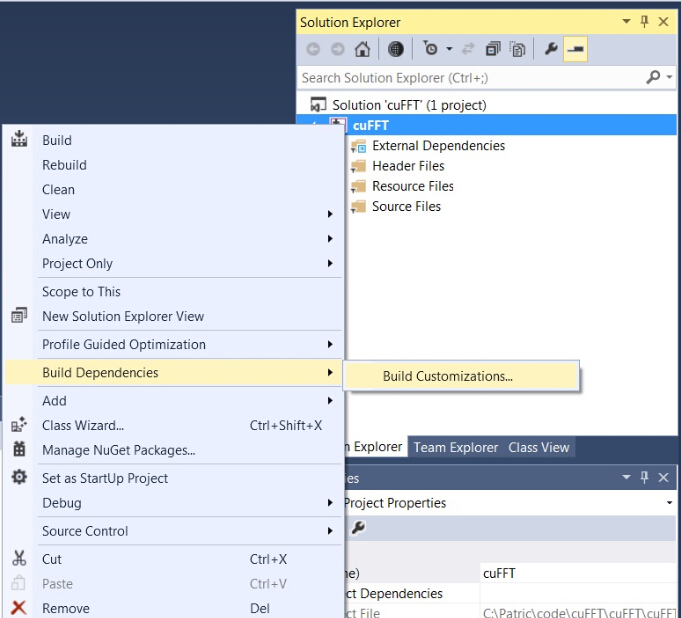
- (right click on project) -> Build dependecies -> Build Customizations -> set check on CUDA 9.1 or what version you have - for example as here: http://devblogs.nvidia.com/parallelforall/wp-content/uploads/2015/01/VS2013-R-5.jpg
- add to project all
.c&.cufiles and filehttp_stream.cppfrom\src - (right click on project) -> properties -> Linker -> General -> Additional Library Directories, put here:
C:\opencv_3.0\opencv\build\x64\vc14\lib;$(CUDA_PATH)lib\$(PlatformName);$(cudnn)\lib\x64;%(AdditionalLibraryDirectories)
- (right click on project) -> properties -> Linker -> Input -> Additional dependecies, put here:
..\..\3rdparty\lib\x64\pthreadVC2.lib;cublas.lib;curand.lib;cudart.lib;cudnn.lib;%(AdditionalDependencies)
- (right click on project) -> properties -> C/C++ -> Preprocessor -> Preprocessor Definitions
OPENCV;_TIMESPEC_DEFINED;_CRT_SECURE_NO_WARNINGS;_CRT_RAND_S;WIN32;NDEBUG;_CONSOLE;_LIB;%(PreprocessorDefinitions)
-
compile to .exe (X64 & Release) and put .dll-s near with .exe: https://hsto.org/webt/uh/fk/-e/uhfk-eb0q-hwd9hsxhrikbokd6u.jpeg
-
pthreadVC2.dll, pthreadGC2.dllfrom \3rdparty\dll\x64 -
cusolver64_91.dll, curand64_91.dll, cudart64_91.dll, cublas64_91.dll- 91 for CUDA 9.1 or your version, from C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin -
For OpenCV 3.2:
opencv_world320.dllandopencv_ffmpeg320_64.dllfromC:\opencv_3.0\opencv\build\x64\vc14\bin -
For OpenCV 2.4.13:
opencv_core2413.dll,opencv_highgui2413.dllandopencv_ffmpeg2413_64.dllfromC:\opencv_2.4.13\opencv\build\x64\vc14\bin
-
How to train (Pascal VOC Data):
-
Download pre-trained weights for the convolutional layers (154 MB): http://pjreddie.com/media/files/darknet53.conv.74 and put to the directory
build\darknet\x64 -
Download The Pascal VOC Data and unpack it to directory
build\darknet\x64\data\vocwill be created dirbuild\darknet\x64\data\voc\VOCdevkit\:- http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
- http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
- http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
2.1 Download file
voc_label.pyto dirbuild\darknet\x64\data\voc: http://pjreddie.com/media/files/voc_label.py -
Download and install Python for Windows: https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe
-
Run command:
python build\darknet\x64\data\voc\voc_label.py(to generate files: 2007_test.txt, 2007_train.txt, 2007_val.txt, 2012_train.txt, 2012_val.txt) -
Run command:
type 2007_train.txt 2007_val.txt 2012_*.txt > train.txt -
Set
batch=64andsubdivisions=8in the fileyolov3-voc.cfg: link -
Start training by using
train_voc.cmdor by using the command line:darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
(Note: To disable Loss-Window use flag -dont_show. If you are using CPU, try darknet_no_gpu.exe instead of darknet.exe.)
If required change pathes in the file build\darknet\x64\data\voc.data
More information about training by the link: http://pjreddie.com/darknet/yolo/#train-voc
Note: If during training you see nan values for avg (loss) field - then training goes wrong, but if nan is in some other lines - then training goes well.
How to train with multi-GPU:
-
Train it first on 1 GPU for like 1000 iterations:
darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -
Then stop and by using partially-trained model
/backup/yolov3-voc_1000.weightsrun training with multigpu (up to 4 GPUs):darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights -gpus 0,1,2,3
Only for small datasets sometimes better to decrease learning rate, for 4 GPUs set learning_rate = 0.00025 (i.e. learning_rate = 0.001 / GPUs). In this case also increase 4x times burn_in = and max_batches = in your cfg-file. I.e. use burn_in = 4000 instead of 1000.
https://groups.google.com/d/msg/darknet/NbJqonJBTSY/Te5PfIpuCAAJ
How to train (to detect your custom objects):
(to train old Yolo v2 yolov2-voc.cfg, yolov2-tiny-voc.cfg, yolo-voc.cfg, yolo-voc.2.0.cfg, ... click by the link)
Training Yolo v3:
- Create file
yolo-obj.cfgwith the same content as inyolov3.cfg(or copyyolov3.cfgtoyolo-obj.cfg)and:
- change line batch to
batch=64 - change line subdivisions to
subdivisions=8 - change line
classes=80to your number of objects in each of 3[yolo]-layers:- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L610
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L696
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L783
- change [
filters=255] to filters=(classes + 5)x3 in the 3[convolutional]before each[yolo]layer- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L603
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L689
- https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L776
So if classes=1 then should be filters=18. If classes=2 then write filters=21.
(Do not write in the cfg-file: filters=(classes + 5)x3)
(Generally filters depends on the classes, coords and number of masks, i.e. filters=(classes + coords + 1)*<number of mask>, where mask is indices of anchors. If mask is absence, then filters=(classes + coords + 1)*num)
So for example, for 2 objects, your file yolo-obj.cfg should differ from yolov3.cfg in such lines in each of 3 [yolo]-layers:
[convolutional]
filters=21















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}