







 本文探讨了推荐系统中存在的用户选择偏差和数据观测偏差问题,指出当前模型主要学习的是相关性而非因果性。为解决这一问题,文章介绍了利用因果推断来识别变量间的因果关系,以提高推荐系统的可解释性和鲁棒性。在快手的推荐场景中,因果推断的应用旨在通过识别因果关系进行模型纠偏,改善用户体验并促进系统生态建设。
本文探讨了推荐系统中存在的用户选择偏差和数据观测偏差问题,指出当前模型主要学习的是相关性而非因果性。为解决这一问题,文章介绍了利用因果推断来识别变量间的因果关系,以提高推荐系统的可解释性和鲁棒性。在快手的推荐场景中,因果推断的应用旨在通过识别因果关系进行模型纠偏,改善用户体验并促进系统生态建设。
推荐系统不可避免地存在偏差(bias)。一个用户无论是在刷视频、看资讯、还是在线购物等基于推荐的场景中作出的选择通常会产生各种偏差。比如用户会偏向点击位置靠前的内容,也会偏向于点击流行度比较高的内容;另外由于推荐系统给用户推荐的候选内容只占整体内容的一小部分,而用户的点击行为都是基于这样一小部分候选集进行的,所以这会产生选择偏差。
与此同时,用户交互日志是模型训练的基础,直接基于这部分观测日志数据作为训练模型的样本会导致训练的模型存在bias,导致给用户推荐的内容同样存在bias,进而整个系统会形成bias闭环,在影响用户体验的同时,不利于系统生态的建设。
因此我们尝试结合因果推断来解决推荐系统中的bias问题,本次分享的主题是因果推断在快手推荐场景的应用探索,旨在通过识别变量之间的因果关系来进行纠偏。
具体将围绕以下几点展开:
-
背景介绍
-
最新研究进展
-
因果推断在快手的应用
-
总结与思考
背景介绍
首先和大家分享下因果推断的背景。
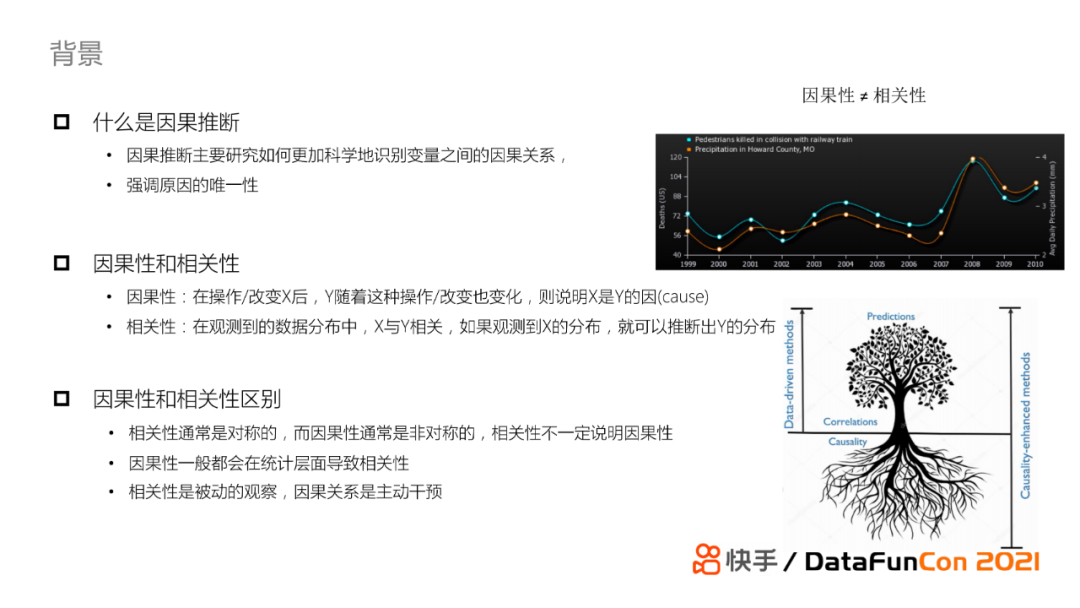
首先我们介绍一下因果推断的定义。因果推断主要研究如何更加科学得识别变量之间的因果关系,强调原因的唯一性。因果性和相关性是有一定的联系与区别的,从他们的定义来看:因果性指的是在改变X后Y随之也发生变化,我们称X是Y的因;相关性指在观测到的数据分布中,若果我们观测到了X的分布就可以推断出Y的分布。因此从定义可以得出,相关性是对称的,即若X和Y相关,则Y和X相关;但是因果性是非对称的。相关性不一定说明因果性,但是因果一般会在统计层面导致相关性。我们现有的机器学习中纯数据驱动的方法其实更多时候学习的是相关性,这就导致目前的深度学习模型的可解释性较差。如果我们引入因果性结合相关性一起建模,从理论上来说它的效果会比仅使用相关性建模要好,即会使模型的可解释性变好,模型的鲁棒性也有一定的提升。


















 4231
4231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









