







讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。
MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili
本案例用到的网址为:成语大全列表成语大全列表 https://chengyu.bmcx.com/e1zdh_1__chengyulist/
https://chengyu.bmcx.com/e1zdh_1__chengyulist/
请大家在电脑浏览器中打开上方的网址:
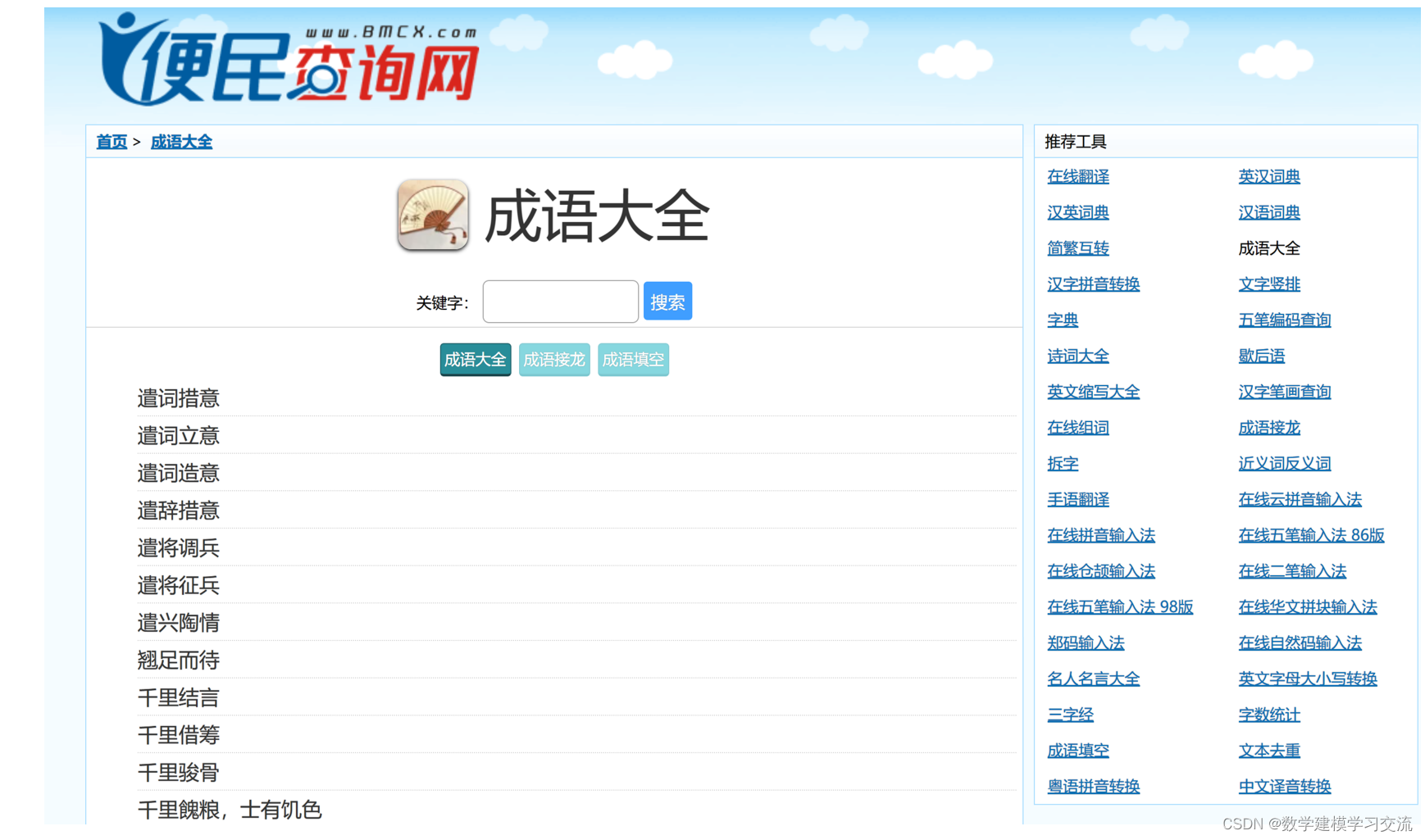
请使用鼠标滚轮将网站下滑滚动到页面底部,可以看到该网站设置了分页功能:

我们可以分别点击第2页和第3页,可以看到新打开的网页地址变为了
https://chengyu.bmcx.com/e1zdh_2__chengyulist/
和
https://chengyu.bmcx.com/e1zdh_3__chengyulist/.
因此,我们发现了这个网址的规律:https://chengyu.bmcx.com/e1zdh_k__chengyulist/,这里的k就表示第k页。通过循环语句,我们能够获取每一个网页的源码,并将每一页的成语提取出来保存到同一个字符串数组中。
现在我们先以第一页的网址为例,获取相应的源码并提取对应的成语。
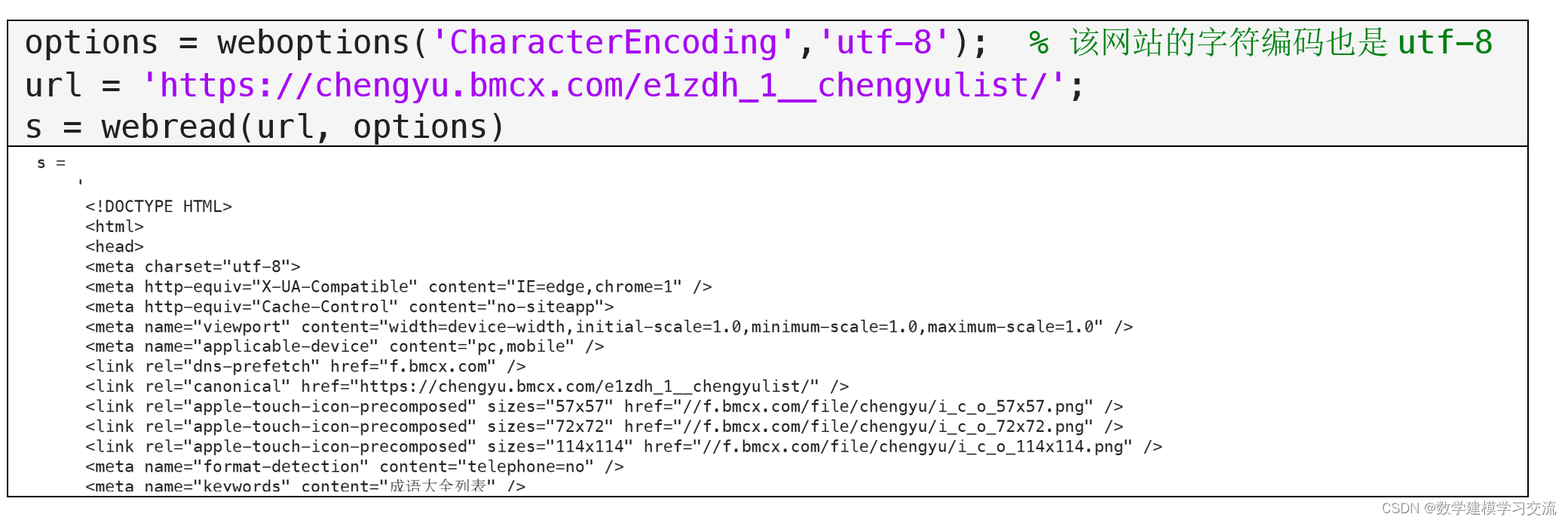
接下来,我们需要在网页的源码中定位成语的位置。这一步需要仔细分析网页的结构,并设计出合适的正则表达式来匹配成语。

通过观察成语在源码中的位置,我们可以设计下面的正则表达式来提取出所有的成语:

以上是获取第一个网页的成语数据的代码。接下来,我们使用循环语句获取前5个网页的成语数据。

小技巧:对于批量爬取多个网页,建议使用try-catch语句来捕获潜在的错误以确保程序的稳健性。我们只需要将其添加到循环体内,当某次循环出现错误时,会产生警告信息。


















 4600
4600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









